稍微涉及技术细节,留以我设计中间件时参考,将来整理深度文档时会抽取走,入门人员可以无视。
以下RocketMQ简称为RQ,理论部分采用版本为3.2.4,测试部分采用版本为3.2.6。
MQ的需求
我们对MQ的需求,相比JMS标准有几点要求更高:
1. 必须优美灵活地支持集群消费。
2. 尽量支持消息堆积。
3. 服务高可用性和消息可靠性。
4. 有起码的运维工具做集群管理和服务调整。
其他 提供顺序消息、事务、回溯等面向特别场景的功能更好,目前暂不需要。
RQ架构
RQ的基本组成包括nameserver、broker、producer、consumer四种节点,前两种构成服务端,后两种在客户端上。
还有其他辅助的进程,不提。
NameServer的基本概念
在没有NameServer的中间件中,服务端集群就由干活的broker组成 ,其中的实例分主从两种角色。那么客户端就要知道,需要连接到哪个地址的broker上去做事情,于是客户端就需要配置服务端机器的IP地址,如果服务端部署结构复杂,客户端的配置结构也挺复杂,更讨厌的是甚至可能需要客户端也得更新地址配置。由于有了两种思路的方案:
一是引入NameServer,负责提供地址。客户端只需要知道NameServer机器的地址,需要找服务器干活的时候,先问NameServer我该去找哪个服务器。这样,因为NameServer很简单而不容易出故障,所以极少发生架构调整。而结构复杂的broker部分,无论怎么调整,客户端都不用再操心。
RQ 2.x用的是Zookeeper做NameServer,3.x用的是自己搞的独立服务,不知道为啥,不过代码貌似不复杂。
二是引入反向代理,就是把服务端地址配置成虚拟IP或域名这种思路,这一个地址背后其实可能是一个集群,客户端发起请求后,由网络设施来中转请求给具体服务器。
两者各有优劣,综合使用也挺正常。
NameServer的工作机制
I.NameServer自身之间的机制
可以启动多个实例,相互独立,不需要相互通信,可以理解为多机热备。
II.NameServer与broker之间
Broker启动后,向指定的一批NameServer发起长连接,此后每隔30s发送一次心跳,心跳内容中包含了所承载的topic信息;NameServer会每隔2分钟扫描,如果2分钟内无心跳,就主动断开连接。
当然如果Broker挂掉,连接肯定也会断开。
一旦连接断开,因为是长连接,所以NameServer立刻就会感知有broker挂掉了,于是更新topic与broker的关系。但是,并不会主动通知客户端。
III.NameServer与客户端之间
客户端启动时,要指定这些NameServer的具体地址。之后随机与其中一台NameServer保持长连接,如果该NameServer发生了不可用,那么会连接下一个。
连接后会定时查询topic路由信息,默认间隔是30s,可配置,可编码指定pollNameServerInteval。
(注意是定时的机制,不是即时查询,也不是NameServer感知变更后推送,所以这里造成接收消息的实时性问题)。
NameServer的部署与应用
I. 运行NameServer
启动: nohup mqnamesrv &
终止:
sh ./mqshutdownUseage: mqshutdown broker | namesrvII. Broker指定NameServer
nohup mqbroker -n "192.168.36.53:9876;192.168.36.80:9876" &export NAMESRV_ADDR=192.168.36.53:9876;192.168.36.80:9876
root@rocketmq-master1 bin]# sh mqbroker -mnamesrvAddr= |
III.客户端指定NameServer
有几种方式:
1.编码指定
producer.setNamesrvAddr("192.168.36.53:9876;192.168.36.80:9876");
所以这里指定的并不是broker的主主或主从机器的地址,而是NameServer的地址。
2.java启动参数
-Drocketmq.namesrv.addr=192.168.36.53:9876;192.168.36.80:9876export NAMESRV_ADDR=192.168.36.53:9876;192.168.36.80:9876客户端还可以配置这个域名jmenv.tbsite.alipay.net来寻址,就不用指定IP了,这样NameServer集群可以做热升级。
该接口具体地址是http://jmenv.tbsite.net:8080/rocketmq/nsaddr
(理论上,最后一种可用性最好;实际上,没试出来。)
Broker的机制
I.消息的存储
II.消息的清理
III.消息的消费
1.IO用的是文件内存映射方式,性能较高,只会有一个写,其他的读。顺序写,随机读。
2. 零拷贝原理:
以前使用linux 的sendfile 机制,利用DMA(优点是CPU不参与传输),将消息内容直接输出到sokect 管道,大块文件传输效率高。缺点是只能用BIO。
于是此版本使用的是mmap+write方式,代价是CPU多耗用一些,内存安全问题复杂一些,要避免JVM Crash。
IV.Topic管理
V.物理特性
1.CPU:Load高,但使用率低,因为大部分时间在IO Wait。
2. 内存:依旧需要大内存,否则swap会成为瓶颈。
3. 磁盘:IO密集,转速越高、可靠性越高越好。
VI.broker之间的机制
单机的刷盘机制,虽然保障消息可靠性,但是存在单点故障影响服务可用性,于是有了HA的一些方式。
1.主从双写模式,在消息可靠性上依然很高,但是有小问题。
a.master宕机之后,客户端会得到slave的地址继续消费,但是不能发布消息。
b.客户端在与NameServer直接网络机制的延迟下,会发生一部分消息延迟,甚至要等到master恢复。
c.发现slave有消息堆积后,会令consumer从slave先取数据。
2 异步复制,消息可靠性上肯定小于主从双写
slave的线程不断从master拉取commitLog的数据,然后异步构建出数据结构。类似mysql的机制。
VII.与consumer之间的机制
1.服务端队列
topic的一个队列只会被一个consumer消费,所以该consumer节点最好属于一个集群。
那么也意味着,comsumer节点的数量>topic队列的数量,多出来的那些comsumer会闲着没事干。
举简单例子说明:
假设broker有2台机器,topic设置了4个队列,那么一个broker机器上就承担2个队列。
此时消费者所属的系统,有8台机器,那么运行之后,其中就只有4台机器连接到了MQ服务端的2台broker上,剩下的4台机器是不消费消息的。
所以,此时要想负载均衡,要把topic的分区数量设高。
2.可靠性
consumer与所有关联的broker保持长连接(包括主从),每隔30s发送心跳,可配置,可以通过heartbeatBrokerInterval配置。
broker每隔10s扫描连接,发现2分钟内没有心跳,则关闭连接,并通知该consumer组内其他实例,过来继续消费该topic。
当然,因为是长连接,所以consumer挂掉也会即时发生上述动作。所以,consumer集群的情况下,消费是可靠的。
而因为consumer与所有broker都持有连接,所以可以两种角色都订阅消息,规则由broker来自动决定(比如master挂了之后重启,要先消费哪一台上的消息)。
3.本地队列
consumer有线程不断地从broker拉取消息到本地队列中,消费线程异步消费。轮询间隔可指定pullInterval参数,默认0;本地队列大小可指定pullThresholdForQueue,默认1000。
而不论consumer消费多少个队列,与一个broker只有一个连接,会有一个任务队列来维护拉取队列消息的任务。
4.消费进度上报
定时上报各个队列的消费情况到broker上,时间间隔可设persistConsumerOffsetInterval。
上述采取的是DefaultMQPushConsumer类做的描述,可见所谓push模式还是定时拉取的,不是所猜测的服务端主动推送。不过拉取采用的是长轮询的方式,实时性基本等同推送。
VIII.与producer的机制
1.可靠性
a.producer与broker的网络机制,与consumer的相同。如果producer挂掉,broker会移除producer的信息,直到它重新连接。
b.producer发送消息失败,最多可以重试3次,或者不超过10s的超时时间,此时间可通过sendMsgTimeout配置。如果发送失败,轮转到下一个broker。
c.producer也可以采用oneway的方式,只负责把数据写入客户端机器socket缓冲区。这样可靠性较低,但是开销大大减少。(适合采集小数据日志)
2.消息负载
发送消息给broker集群时,是轮流发送的,来保障队列消息量平均。也可以自定义往哪一个队列发送。
3.停用机制
当broker重启的时候,可能导致此时消息发送失败。于是有命令可以先停止写权限,40s后producer便不会再把消息往这台broker上发送,从而可以重启。
sh mqadmin wipeWritePerm -b brokerName -n namesrvAddr
IX.通信机制
1.组件采用的是Netty.4.0.9。
2.协议是他们自己定的新玩意,并不兼容JMS标准。协议具体内容有待我开发C#版客户端时看详情。
3.连接是可以复用的,通过header的opaque标示区分。
Broker的集群部署
一句话总结其特征就是:不支持主从自动切换、slave只能读不能写,所以故障后必须人工干预恢复负载。
|
集群方式
|
运维特点
|
消息可靠性(master宕机情况)
|
服务可用性(master宕机情况)
|
其他特点
|
备注
|
|---|---|---|---|---|---|
| 一组主主 | 结构简单,扩容方便,机器要求低 | 同步刷盘消息一条都不会丢 |
整体可用 未被消费的消息无法取得,影响实时性 |
性能最高 | 适合消息可靠性最高、实时性低的需求。 |
| 一组主从 |
异步有毫秒级丢失; 同步双写不丢失; |
差评,主备不能自动切换,且备机只能读不能写,会造成服务整体不可写。 |
不考虑,除非自己提供主从切换的方案。 | ||
| 多组主从(异步复制) | 结构复杂,扩容方便 | 故障时会丢失消息; |
整体可用,实时性影响毫秒级别 该组服务只能读不能写 |
性能很高 | 适合消息可靠性中等,实时性中等的要求。 |
| 多组主从(同步双写) | 结构复杂,扩容方便 | 不丢消息 |
整体可用,不影响实时性 该组服务只能读不能写。 不能自动切换? |
性能比异步低10%,所以实时性也并不比异步方式太高。 |
适合消息可靠性略高,实时性中等、性能要求不高的需求。 |
第四种的官方介绍上,比第三种多说了一句:“不支持主从自动切换”。这句话让我很恐慌,因为第三种也是不支持的,干嘛第四种偏偏多说这一句,难道可用性上比第三种差?
于是做了实验,证明第三种和第四种可用性是一模一样的。那么不支持主从切换是什么意思?推断编写者是这个意图:
因为是主从双写的,所以数据一致性非常高,那么master挂了之后,slave本是可以立刻切换为主的,这一点与异步复制不一样。异步复制并没有这么高的一致性,所以这一句话并不是提醒,而是一个后续功能的备注,可以在双写的架构上继续发展出自动主从切换的功能。
架构测试总结:
1.其实根本不用纠结,高要求首选同步双写,低要求选主主方案。
2.最好不用一个机器上部署多个broker实例。端口容易冲突,根源问题还没掌握。
所以,建议采用多台机器,一台起一个broker,构成同步双写的架构。也就是官方提供的这种物理和逻辑架构。
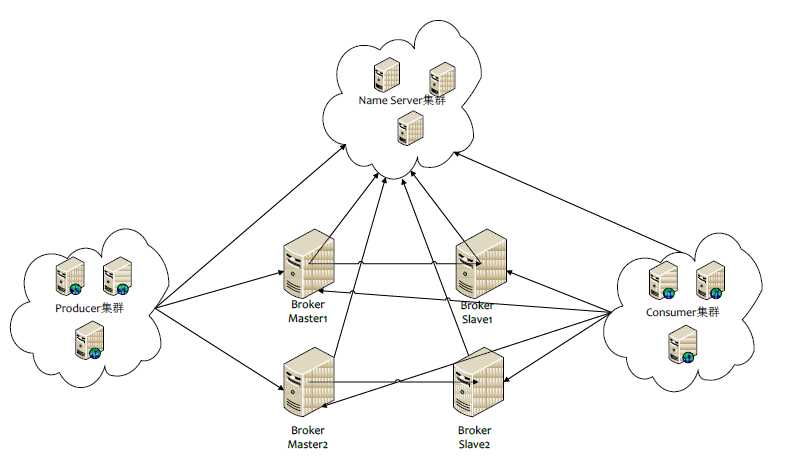
注意几个特征:
a.客户端是先从NameServer寻址的,得到可用Broker的IP和端口信息,然后自己去连接broker。
b.生产者与所有的master连接,但不能向slave写入;而消费者与master和slave都建有连接,在不同场景有不同的消费规则。
c.NameServer不去连接别的机器,不主动推消息。
客户端的概念
1.Producer Group
Producer实例的集合。
Producer实例可以是多机器、但机器多进程、单进程中的多对象。Producer可以发送多个Topic。
处理分布式事务时,也需要Producer集群提高可靠性。
2.Consumer Group
Consumer实例 的集合。
Consumer 实例可以是多机器、但机器多进程、单进程中的多对象。
同一个Group中的实例,在集群模式下,以均摊的方式消费;在广播模式下,每个实例都全部消费。
3.Push Consumer
应用通常向Consumer对象注册一个Listener接口,一旦收到消息,Consumer对象立刻回调Listener接口方法。所以,所谓Push指的是客户端内部的回调机制,并不是与服务端之间的机制。
4.Pull Consumer
应用通常主动调用Consumer从服务端拉消息,然后处理。这用的就是短轮询方式了,在不同情况下,与长轮询各有优点。
发布者和消费者类库另有文档,不提。
重要问题总结:
1.客户端选择推还是拉,其实考虑的是长轮询和短轮询的适用场景。
2.服务端首选同步双写架构,但依然可能造成故障后30s的消息实时性问题(客户端机制决定的)。
3.Topic管理,需要先调查客户端集群机器的数目,合理设置队列数量之后,再上线。