标签:
一、spring:是基础,可以管理对象,也可以通过关键对象管理另一个框架。但是首先应该明确spring并不是只能应用于web方面,而是可以应用在一般的java项目中。只是如果在web环境下使用需要在web.xml中进行注册(启动IOC容器的servletContextListener)。还有就是获取方式稍有不同。

1 <!-- 下面是有关spring在web中启动的配置,是spring提供的listener --> 2 <!-- 启动IOC容器的servletContextListener --> 3 <listener> 4 <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> 5 </listener> 6 <!-- 添加spring配置文件名称和位置 --> 7 <context-param> 8 <param-name>contextConfigLocation</param-name> 9 <param-value>classpath:applicationContext.xml</param-value> 10 </context-param>
①管理对象,所有对象都是通过spring配置,需要时通过其产生(IOC)。是解除紧耦合的第一步。
通过spring管理的对象需要在配置文件中注册或者通过注释配置,就是一个<bean>,还可以为 构造函数参数/属性 注入值
②AOP面向切面编程的实现,我的简单理解就是业务层面的解耦。
AOP同样可以通过配置和注释实现。
1 <?xml version="1.0" encoding="UTF-8"?> 2 <beans 3 xmlns="http://www.springframework.org/schema/beans" 4 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 5 xmlns:p="http://www.springframework.org/schema/p" 6 xmlns:aop="http://www.springframework.org/schema/aop" 7 xmlns:context="http://www.springframework.org/schema/context" 8 xsi:schemaLocation="http://www.springframework.org/schema/beans 9 http://www.springframework.org/schema/beans/spring-beans-3.1.xsd 10 http://www.springframework.org/schema/aop 11 http://www.springframework.org/schema/aop/spring-aop-3.1.xsd 12 http://www.springframework.org/schema/context 13 http://www.springframework.org/schema/context/spring-context-3.1.xsd"> 14 <!-- 下面一句是开启spring的注释配置方式,需要在beans的属性中添加xmlns:context的命名空间 15 实质上是开启了注解的解析处理器,有四种 16 --> 17 <context:annotation-config/> 18 19 20 <!-- 注意:每个bean默认情况下都是单例对象 --> 21 <!-- 配置bean,id在获取时使用,class对应实际的javabean类--> 22 <bean id="stu" class="com.dqxst.domain.Stu"> 23 <!-- 24 1、 下面是设置构造器参数,按照顺序,对应可以接受这些值的构造器来构造对象, 25 例如下面的设置就是对应(String,int)参数的构造器,顺序不能乱 26 2、如果参数是自定义对象,则应该使用ref而非value,值为已经声明的bean的id 27 --> 28 <constructor-arg value="sfl"/> 29 <constructor-arg value="15"/> 30 <constructor-arg ref="helloWorld" /> 31 32 <!-- 33 下面是为javabean属性赋值,相当于使用set(),也称属性注入 34 当然,这种操作是在创建对象之后的,也就是在上面的构造器方法之后使用 35 同样,如果注入的是一个对象,使用的是ref 36 --> 37 <property name="name" value="test"></property> 38 <property name="study" ref="work"></property> 39 <!-- 声明一个内部类 --> 40 <property name="home"> 41 <bean class="com.dqxst.domain.Home"> 42 <property name="father" value="ssk"></property> 43 <property name="mother" value="wsp"></property> 44 </bean> 45 </property> 46 </bean> 47 48 <bean id="helloWorld" class="com.dqxst.domain.HelloWorld"></bean> 49 50 <!-- factory-method属性用于没有公开构造器的类创建对象,通常用于单例模式下的对象创建 51 称为静态工厂方法配置bean 52 --> 53 <bean id="classroom" class="com.dqxst.domain.Classroom" 54 factory-method="getInstance"/> 55 56 <!-- scope属性用于确定bean的作用域,即在那个范围中是唯一的 --> 57 <bean id="work" class="com.dqxst.domain.Work" scope="prototype" /> 58 59 <bean id="collage" class="com.dqxst.domain.Collage" 60 factory-method="getInstance" /> 61 62 <!-- 下面这个bean是用于AOP的 --> 63 <bean id="classes" class="com.dqxst.aop.Classes" /> 64 <bean id="classes2" class="com.dqxst.aop.Classes2" /> 65 <!-- 下面是AOP的一些配置,注意都是在一个节点之内的 --> 66 <aop:config> 67 <!-- 定义一个切面 --> 68 <aop:aspect ref="classes"> 69 <!-- 定义一个通知,在内部声明切点,也可以引用一个外部声明的切点 --> 70 <aop:before pointcut="execution(* com.dqxst.domain.Stu.study(..))" 71 method="stand"/> 72 <!-- 这个通知引用外部切点声明,注意多个同一点的切点按声明顺序执行,例如这里的两个前者通知 --> 73 <aop:before pointcut-ref="pointcut" 74 method="sayHi"/> 75 <aop:after-throwing pointcut-ref="pointcut" 76 method="delayed"/> 77 <aop:after pointcut-ref="pointcut" 78 method="sayBye"/> 79 <!-- 外部切点声明 --> 80 <aop:pointcut id="pointcut" 81 expression="execution(* com.dqxst.domain.Stu.study(..))"/> 82 </aop:aspect> 83 <aop:aspect ref="classes2"> 84 <aop:pointcut expression="execution(* com.dqxst.domain.Stu.nowStudy(..))" 85 id="pcut"/> 86 <aop:around pointcut-ref="pcut" method="onClass"/> 87 </aop:aspect> 88 </aop:config> 89 </beans>
③springmvc:基于spring的mvc框架,优点是和spring结合紧密,不需多余配置。
参考:http://blog.csdn.net/lishuangzhe7047/article/details/20740209
http://www.blogjava.net/stevenjohn/archive/2012/08/20/385846.html
二、strut2:是用filter作为控制器的MVC框架,配置环境分三步:
1、添加jar包,2、添加strut.xml配置文件,3、在web.xml中进行配置(配置strut的主要过滤器filter)
需要注意的是strut配置文件默认不提示,联网情况下可以自动下载dtd约束文件,但是也可以手动配置本地约束文件
struts2负责C(controller)的部分:主要负责将url/form中的数据发送到指定的url对应的Action类进行处理,具体的处理过程如下:
1、首先,Struts2通过属性/模型驱动来自动封装数据为实体对象,节省了很多的重复操作,但是这也对实体属性命名和表单name属性命名有一些对应要求;
2、这些Action类就是和servlet执行相同的工作,也可以获取域对象(即web资源)进行操作。
3、最后定位到JSP页面进行输出。
①struct2数据传递的方式:值栈,可以通过struct2标签和OGNL表达式进行读取,这三个是struct2的重要基础
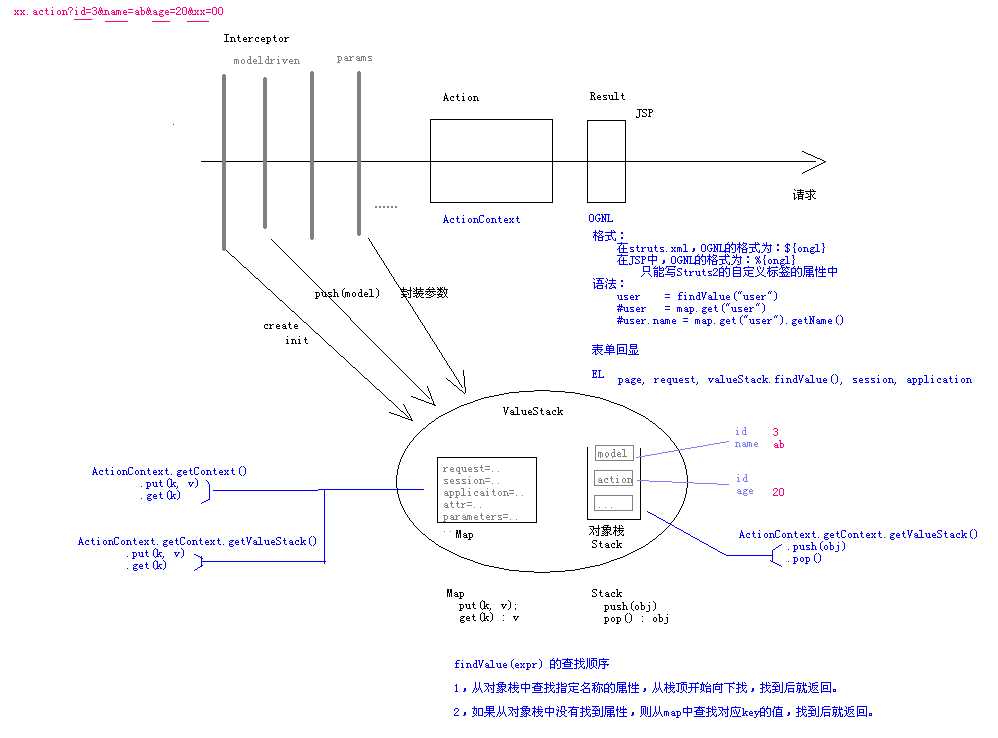
参考:http://blog.knowsky.com/188302.htm
http://blog.csdn.net/a549324766/article/details/7206876
http://blog.knowsky.com/194419.htm
三、hibernate:经典的关系对象映射框架,就是将数据库中关系型的数据转换成java中的对象型数据。主要有以下几点:
①编写pojo类,配置映射关系。重要
②hibernate使用:
①首先获取SessionFactory对象,然后得到Session对象。通过Session对象进行增删查改实际操作。注意:sessionFactory是线程安全的,但是Session线程不安全,由于servlet的单例特点,可能引发线程问题,所以需要注意。并且在Session管理中的对象有不同的状态还可以转化。和jdcb一样,基础操作比较复杂,可以使用工具类简化使用。
参考:http://lialiks.bokee.com/586567.html
http://blog.csdn.net/shrek_xu/article/details/740991
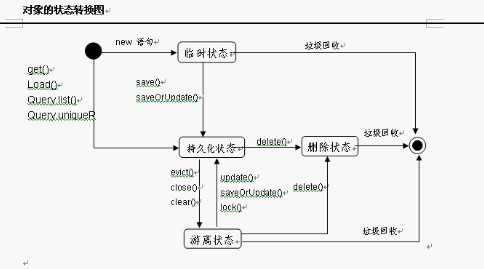
②HQL,面向对象查询,类似sql。多表查询差别大。真实使用的sql语句是hibernate通过HQL和映射文件自动生成的。缺点是不利于优化。
1 import hibernate_g_query.domain.Department; 2 import hibernate_g_query.domain.Employee; 3 4 import java.util.Arrays; 5 import java.util.List; 6 7 import org.hibernate.Criteria; 8 import org.hibernate.Session; 9 import org.hibernate.Transaction; 10 import org.hibernate.criterion.Restrictions; 11 import org.junit.Test; 12 13 import com.dqxst.dao.DaoUtils; 14 15 public class Dao { 16 @Test 17 public void save() { 18 Session session = DaoUtils.openSession(); 19 Transaction tx = null; 20 try { 21 tx = session.beginTransaction(); 22 23 for (int i = 0; i < 10; i++) { 24 Department department = new Department(); 25 department.setName("研发部" + i); 26 session.save(department); 27 } 28 29 for (int i = 0; i < 20; i++) { 30 Employee employee = new Employee(); 31 employee.setName("test" + i); 32 session.save(employee); 33 } 34 35 tx.commit(); 36 } catch (Exception e) { 37 tx.rollback(); 38 throw e; 39 } finally { 40 } 41 } 42 43 // 练习hql查询语句 44 @Test 45 public void hql() { 46 Session session = DaoUtils.openSession(); 47 Transaction tx = null; 48 try { 49 tx = session.beginTransaction(); 50 /* 51 * 一般特点: 1、和sql语句相似,但是移植性好 2、hql查询的是对象及其属性,即from后的是对象; 52 * 3、涉及到对象的部分需要区分大小写,其余部分不用。如果类名是唯一的可以直接使用, 否则需要使用全限定名 53 */ 54 String hql; 55 // 1、简单查询,不使用select,可以使用别名,也可以省略as,没有限定条件查询所有 56 hql = "FROM Employee e"; 57 58 // 2、使用过滤条件,即where语句 59 hql = "FROM Employee e WHERE e.id<10"; 60 61 // 3、使用order by排序 62 hql = "FROM Employee e WHERE e.id<10 ORDER BY id DESC"; 63 64 /* 65 * 4、指定select子句, 1、不使用select时返回值是对象的List集合 2、查询单列: 66 * 3、查询多列:返回的是集合的元素类型是Object数组 !!! 但是可以使用new将这些列封装为对象,需要有对应的构造函数 67 */ 68 hql = "SELECT e.name FROM Employee e"; 69 70 hql = "SELECT e.id,e.name FROM Employee e"; 71 // 对应的构造函数就是以该两列为参数的构造函数 72 hql = "SELECT new Employee(e.id,e.name) FROM Employee e"; 73 74 /* 75 * 5、执行查询,获取结果 1、获取查询对象 2、获取结果集 76 */ 77 // Query query=session.createQuery(hql); 78 // //hibernate的分页 79 // query.setFirstResult(0); 80 // query.setMaxResults(10); 81 // List<?> list=query.list(); 82 83 // 6、hibernate支持方法链操作 84 List<?> list = session.createQuery(hql)// 85 .setFirstResult(0)// 86 .setMaxResults(10)// 87 .list(); 88 89 for (Object obj : list) { 90 if (obj.getClass().isArray()) { 91 System.out.println(Arrays.toString((Object[]) obj)); 92 } else { 93 System.out.println(obj); 94 } 95 } 96 tx.commit(); 97 } catch (Exception e) { 98 tx.rollback(); 99 throw e; 100 } finally { 101 session.close(); 102 } 103 } 104 105 @Test 106 public void hql2() { 107 Session session = DaoUtils.openSession(); 108 Transaction tx = null; 109 try { 110 tx = session.beginTransaction(); 111 112 String hql; 113 114 /* 1,聚集函数:count() min() max() sum() avg() 115 * count()返回结果为Long型,其余返回为查询的属性的类型。使用Number类型最好 116 */ 117 hql="SELECT COUNT(*) FROM Employee"; 118 Number result=(Number) session.createQuery(hql).uniqueResult(); 119 System.out.println(result); 120 121 // 2,分组 group by和having,一些子句可以使用列别名,但是不推荐使用 122 hql="SELECT e.name,COUNT(*) FROM Employee e GROUP BY e.name " 123 + "HAVING COUNT(*)>6"; 124 125 /* 3,连接查询 / HQL是面向对象的查询 126 * 默认是inner join内连接,还可以使用left (out)/right (out)进行查询 127 * 但是hql还有更简单的方式:可以像查询属性一样进行连接查询,内部会进行转换 128 */ 129 //hql="SELECT e.id,e.name,d.name FROM Employee e JOIN e.department d"; 130 hql="SELECT e.id,e.name,e.department.name FROM Employee e"; 131 132 // 4,查询时使用参数:和jdbc中类似,防止sql注入 133 // >>方式一:使用‘?‘占位 134 // hql="FROM Employee WHERE id BETWEEN ? AND ?"; 135 // List<?> list=session.createQuery(hql)// 136 // .setParameter(0, 5)// 137 // .setParameter(1, 15)// 138 // .list(); 139 // >>方式二:使用变量名 140 // hql="FROM Employee WHERE id BETWEEN :idMin AND :idMax"; 141 // List<?> list=session.createQuery(hql)// 142 // .setParameter("idMin", 5)// 143 // .setParameter("idMax", 15)// 144 // .list(); 145 // >>当参数不确定时可以使用集合传参 146 // hql="FROM Employee WHERE id IN (:ids)"; 147 // List<?> list=session.createQuery(hql)// 148 // .setParameterList("ids", new Object[]{1,2,5,7})// 149 // .list(); 150 151 /* 5,使用命名查询:就是将查询语句写到配置文件中而不是硬编码到程序中, 152 * 通过名字来查找sql语句,并生成Query对象, 153 * 该查询语句通常写到该实体的映射文件中 154 */ 155 List<?> list=session.getNamedQuery("queryByIdRange")// 156 .setParameter("idMin", 5)// 157 .setParameter("idMax", 15)// 158 .list(); 159 160 /* 6,update与delete,不会通知Session缓存,也就是通过session获取时不能获取最新值 161 * 所以:在update或delete后,需要refresh(obj)一下以获取最新的状态 162 */ 163 hql="UPDATE Employee e SET e.name=? WHERE e.id>15"; 164 result=session.createQuery(hql)// 165 .setParameter(0, "asd")// 166 .executeUpdate(); //执行更新语句,返回受影响行数 167 session.refresh(list); 168 System.out.println(result); 169 170 // List<?> list = session.createQuery(hql)// 171 // .list(); 172 173 for (Object obj : list) { 174 if (obj.getClass().isArray()) { 175 System.out.println(Arrays.toString((Object[]) obj)); 176 } else { 177 System.out.println(obj); 178 } 179 } 180 tx.commit(); 181 } catch (Exception e) { 182 tx.rollback(); 183 throw e; 184 } finally { 185 session.close(); 186 } 187 } 188 189 @Test 190 public void qbc(){ 191 Session session = DaoUtils.openSession(); 192 Transaction tx = null; 193 try { 194 tx = session.beginTransaction(); 195 196 //创建对象 197 Criteria criteria=session.createCriteria(Employee.class); 198 199 //添加过滤条件 200 criteria.add(Restrictions.ge("id", 5)); 201 criteria.add(Restrictions.le("id", 10)); 202 //添加排序条件 203 204 //执行查询,获取结果集 205 List<?> list=criteria.list(); 206 for (Object obj : list) { 207 if (obj.getClass().isArray()) { 208 System.out.println(Arrays.toString((Object[]) obj)); 209 } else { 210 System.out.println(obj); 211 } 212 } 213 tx.commit(); 214 } catch (Exception e) { 215 tx.rollback(); 216 throw e; 217 } finally { 218 session.close(); 219 } 220 } 221 }
③高级部分:
懒加载:就是关联查询时可以在使用之前在查询而不是直接查询
使用连接池:在hibernate配置文件即可配置,但是如果和spring配合使用则在spring中进行配置。
缓存(一级/二级) 参考:http://www.cnblogs.com/shanmu/p/3598509.html
四、框架整合,所谓的整合就是使用spring关联struct2和hibernate框架,然后使用tomcat生成spring。
①spring整合hibernate,主要是两个:管理sessionFactory,管理事务
1 <?xml version="1.0" encoding="UTF-8"?> 2 <beans xmlns="http://www.springframework.org/schema/beans" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xmlns:p="http://www.springframework.org/schema/p" 5 xmlns:tx="http://www.springframework.org/schema/tx" 6 xmlns:context="http://www.springframework.org/schema/context" 7 xsi:schemaLocation="http://www.springframework.org/schema/beans 8 http://www.springframework.org/schema/beans/spring-beans-3.1.xsd 9 http://www.springframework.org/schema/context 10 http://www.springframework.org/schema/context/spring-context-3.1.xsd 11 http://www.springframework.org/schema/tx 12 http://www.springframework.org/schema/tx/spring-tx.xsd"> 13 14 <context:component-scan base-package="com.dqxst" /> 15 <bean class="org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor"/> 16 17 <!-- 导入资源文件 --> 18 <context:property-placeholder location="classpath:db.properties"/> 19 20 <!-- 配置C3P0资源,值使用的是properties中的值 --> 21 <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> 22 <property name="driverClass" value="${driverClass}"></property> 23 <property name="jdbcUrl" value="${jdbcUrl}"></property> 24 <property name="user" value="${user}"></property> 25 <property name="password" value="${password}"></property> 26 <property name="initialPoolSize" value="${initPoolSize}"></property> 27 <property name="maxPoolSize" value="${maxPoolSize}"></property> 28 </bean> 29 30 <!-- 配置hibernate的SessionFactory实例,其实是spring中的LocalSessionFactoryBean --> 31 <bean id="sessionFactory" 32 class="org.springframework.orm.hibernate3.LocalSessionFactoryBean"> 33 34 <!-- 引入数据源 --> 35 <property name="dataSource" ref="dataSource"></property> 36 37 <!-- 引入hibernate配置文件,最好是在该配置文件中进行配置 --> 38 <property name="configLocation" 39 value="file:src/hibernate.cfg.xml"> 40 </property> 41 <!-- 在spring中配置hibernate属性 --> 42 <property name="hibernateProperties"> 43 <props> 44 <prop key="hibernate.dialect">org.hibernate.dialect.MySQLDialect</prop> 45 </props> 46 </property> 47 48 <!-- 引入映射文件 --> 49 <property name="mappingLocations" value="classpath:com/dqxst/domain/*.hbm.xml"></property> 50 </bean> 51 52 <bean id="transactionManager" 53 class="org.springframework.orm.hibernate3.HibernateTransactionManager"> 54 <property name="sessionFactory" ref="sessionFactory" /> 55 </bean> 56 <tx:annotation-driven transaction-manager="transactionManager" /> 57 </beans>
②spring整合struct2,主要体现在通过spring来管理struct2使用的action对象,所以不需要过多的配置。但是struct2是通过拦截器链实现的,所以需要在web.xml中配置struct2使用的主过滤器,注意要在spring之后配置。
1 <!-- 配置Struts2的主过滤器 --> 2 <filter> 3 <filter-name>struts2</filter-name> 4 <filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class> 5 </filter> 6 <filter-mapping> 7 <filter-name>struts2</filter-name> 8 <url-pattern>/*</url-pattern> 9 </filter-mapping>
标签:
原文地址:http://www.cnblogs.com/songfeilong2325/p/4694758.html
