标签:
本文简单地讲解如何使用n-gram模型结合汉字拼音来作中文错别字纠错,然后介绍最短编辑距离在中文搜索纠错方面的应用;最后从依赖树入手讲解如何作文本长距离纠错(语法纠错),并从该方法中得到一种启示,利用依赖树的特点结合ESA算法来做同义词的聚类。
在中文错别字查错情景中,我们判断一个句子是否合法可以通过计算它的概率来得到,假设一个句子S = {w1, w2, ..., wn},则问题可以转换成如下形式:
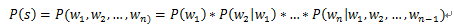
P(S)被称为语言模型,即用来计算一个句子合法概率的模型。
但是使用上式会出现很多问题,参数空间过大,信息矩阵严重稀疏,这时就有了n-gram模型,它基于马尔科夫模型假设,一个词的出现概率仅依赖于该词的前1个词或前几个词,则有
(1)一个词的出现仅依赖于前1个词,即Bigram(2-gram):

(2)一个词的出现仅依赖于前2个词,即Trigram(3-gram):

当n-gram的n值越大时,对下一个词的约束力就越强,因为提供的信息越多,但同时模型就越复杂,问题越多,所以一般采用bigram或trigram。下面举一个简单的例子,说明n-gram的具体使用:
n-gram模型通过计算极大似然估计(Maximum Likelihood Estimate)构造语言模型,这是对训练数据的最佳估计,对于Bigram其计算公式如下:

对于一个数据集,假设count(wi)统计如下(总共8493个单词):

而count(wi, wi-1)统计如下:
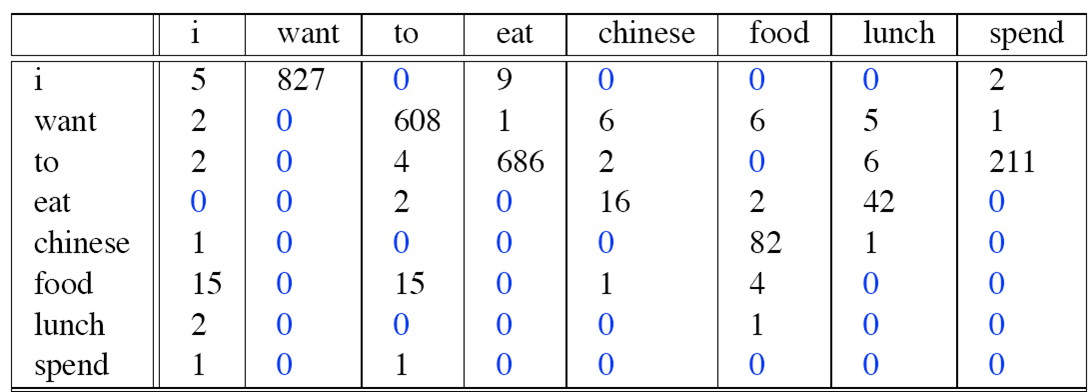
则Bigram概率矩阵计算如下:
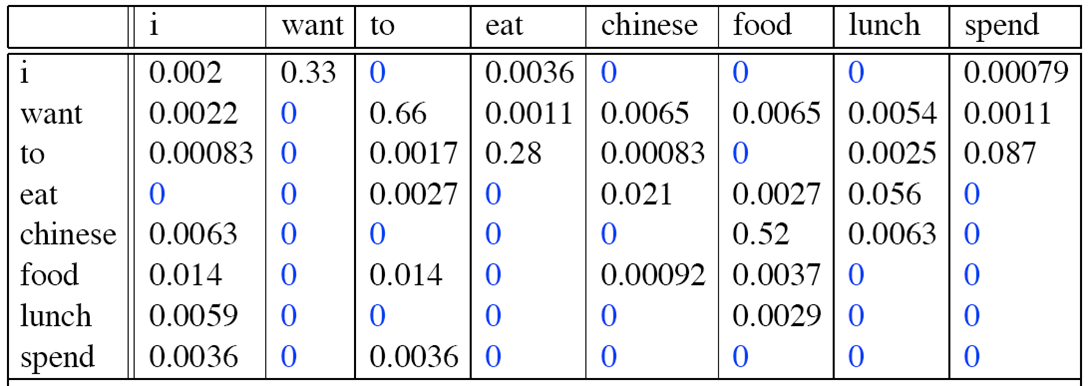
句子“I want to eat Chinese food”成立的概率为:
P(I want to eat Chinese food) = P(I) * P(want|I) * P(to|want) * P(eat|to) * P(Chinese|eat) * P(food|Chinese)
= (2533/8493) * 0.33 * 0.66 * 0.28 * 0.021 * 0.52。
接下来我们只需要训练确定一个阀值,只要概率值≥阀值就认为句子合法。
为了避免数据溢出、提高性能,通常会使用取log后使用加法运算替代乘法运算,即
log(p1*p2*p3*p4) = log(p1) + log(p2) + log(p3) + log(p4)
可以发现,上述例子中的矩阵存在0值,在语料库数据集中没有出现的词对我们不能就简单地认为他们的概率为0,这时我们采用拉普拉斯矩阵平滑,把0值改为1值,设置成该词对出现的概率极小,这样就比较合理。

有了上面例子,我们可以拿n-gram模型来做选择题语法填空,当然也可以拿来纠错。中文文本的错别字存在局部性,即我们只需要选取合理的滑动窗口来检查是否存在错别字,下面举一个例子:
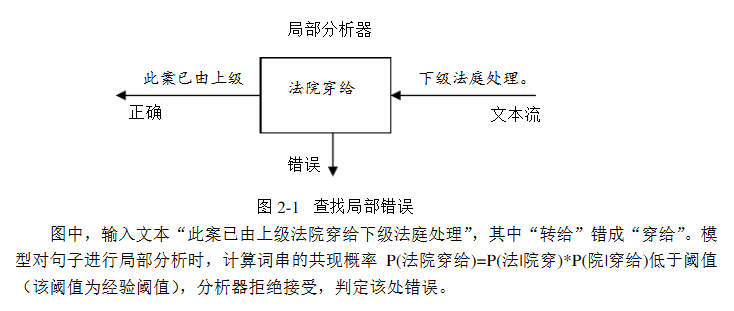
我们可以使用n-gram模型检查到“穿”字打错了,这时我们将“穿”字转换成拼音“chuan”,再从词典中查找“chuan”的候选词,一个一个试填,用n-gram检查,看是否合理。这就是n-gram模型结合汉字拼音来做中文文本错别字纠错了。汉字转拼音可以使用Java库pinyin4j 。
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
import net.sourceforge.pinyin4j.format.HanyuPinyinToneType;
import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;
public class Keyven {
public static void main(String[] args) {
HanyuPinyinOutputFormat format = new HanyuPinyinOutputFormat();
format.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
String str = "我爱自然语言处理,Keyven";
System.out.println(str);
String[] pinyin = null;
for (int i = 0; i < str.length(); ++i) {
try {
pinyin = PinyinHelper.toHanyuPinyinStringArray(str.charAt(i),
format);
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
if (pinyin == null) {
System.out.print(str.charAt(i));
} else {
if (i != 0) {
System.out.print(" ");
}
System.out.print(pinyin[0]);
}
}
}
}
当然,现实生活中也存在汉字拼音没打错,是词语选错了;或者n-gram检查合理但词语不存在,例如:

这时就用到最短编辑距离了,对于这种热搜词,我们仅需记录n-Top,然后用最短编辑距离计算相似度,提供相似度最高的那个候选项就可以了。
编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。例如将kitten一字转成sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
俄罗斯科学家Vladimir Levenshtein在1965年提出这个概念。它是一种DP动态规划算法,在POJ或ACM算法书上有类似的题目。主要思想如下:
首先定义这样一个函数Edit(i, j),它表示第一个字符串的长度为i 的子串到第二个字符串的长度为j 的子串的编辑距离。显然可以有如下动态规划公式:
if (i == 0 且 j == 0),Edit(i, j) = 0
if (i == 0 且 j > 0),Edit(i, j) = j
if (i > 0 且j == 0),Edit(i, j) = i
if (i ≥ 1 且 j ≥ 1) ,Edit(i, j) = min{ Edit(i-1, j) + 1, Edit(i, j-1) + 1, Edit(i-1, j-1) + F(i, j) },
其中,当第一个字符串的第i 个字符不等于第二个字符串的第j 个字符时,F(i, j) = 1;否则,F(i, j) = 0。
#include <iostream>
#include <string.h>
using namespace std;
#define min(a,b) (a<b?a:b)
#define min3(a,b,c) (a<min(b,c)?a:min(b,c))
int main()
{
/*
AGTCTGACGC
AGTAAGTAGGC
sailn
failing
*/
char astr[100], bstr[100];
int dist[100][100];
memset(astr, ‘\0‘, sizeof(astr));
memset(bstr, ‘\0‘, sizeof(bstr));
memset(dist, 0, sizeof(dist));
gets(astr);
gets(bstr);
int alen = strlen(astr);
int blen = strlen(bstr);
for (int i = 0; i <= alen; i++)
{
dist[i][0] = i;
}
for (int i = 0; i <= blen; i++)
{
dist[0][i] = i;
}
for (int i = 1; i <= alen; i++)
{
for (int j = 1; j <= blen; j++)
{
int d = (astr[i - 1] != bstr[j - 1]) ? 1 : 0;
dist[i][j] = min3(dist[i - 1][j] + 1, dist[i][j - 1] + 1, dist[i - 1][j - 1] + d);
}
}
for (int i = 0; i <= alen; i++)
{
for (int j = 0; j <= blen; j++)
{
printf("%d ", dist[i][j]);
}
printf("\n");
}
printf("%d\n", dist[alen][blen]);
system("pause");
return 0;
}
中文语法纠错
之前参加了中文语法错误诊断评测CGED(ACL-IJCNLP2015 workshop)比赛,我负责的是Selection 部分,我们来看官方给出的样例(Redundant、Missing、Selection、Disorder分别对应4种语法错误):

比赛过程中有想到使用依存树来解决Selection(语法搭配错误)问题,语法搭配与其说是语法范畴,倒不如说是语义概念,例如“那个电影”我们判断“个”错了是依据“电影”一词来判断,又如“吴先生是修理脚踏车的拿手”判断“拿手”错了是依据“是”一字,“拿手”是动词,怎么能采用“是+名词”结构呢?但是当时事情比较多各种手忙脚乱前途未卜,所以没做出来。后来上网查论文看到一篇《基于n-gram及依存分析的中文自动差错方法》,记得是2年前看到过的,当时对依存树还不理解所以没在意论文的后半部,现在理解了,写东西也有个理论支撑,没想到想法好有缘分^_^。
词与词之间的搭配是看两者之间的语义关联强度,而依存树的边正可以用来体现这种语义关联度,如果一个句子存在Selection语法错误,那么建成依存树也应该存在一条边是不合理的,我们可以用这条边来判断是否出现了语法错误。在上述论文中作者将其称之为用来作长距离的中文纠错,而n-gram则是短距离中文纠错。
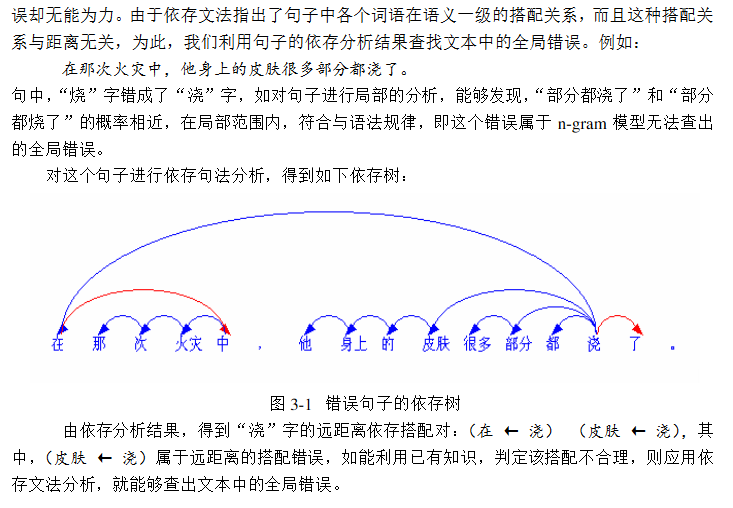
至于怎样利用已有知识,建立领域知识库,我们可以跑一遍正确的语料库数据集,统计那些语法正确的句子的依存树边... ...CEGD那个比赛所给的训练集有点奇怪,这个也是导致比赛过程不理想没把依存树想法做出来的原因。我重新从网上找来了几个测试样例(语言学专业的课件PPT),我们来看一下再看如何拿依存树来做同义词聚类。利用依存树做Selection语法侦错是有了,可是还要纠错呢,怎么实现一种纠错算法呢,当然是同义词替换了,会产生Selection类错误一般都是同义词误用。我曾经拿HIT-IRLab-同义词词林(扩展版) 对比,效果不是很好,所以就有了后来的同义词聚类想法。

之前有接触过同义词聚类的论文,其中印象比较深刻的一篇是《 Computing Semantic Relatedness using Wikipedia-based Explicit Semantic Analysis 》,也就是ESA(Explicit Semantic Analysis)算法。ESA的主要思想就是,将一个Wiki词条看成一个主题概念,然后将词条下的解释文本先用TF-IDF逆文档频率过滤分词,再用倒排索引建立成(word-Topic),这样就可以构造主题向量,我们可以用这些主题向量来做语义相似度计算,完成同义词的聚类。
但是这种工作对于我来说有点难以完成,后来在看Selection平行语料库时,发现一样有意思的东西,就是上图中标成黄色的边,瞬间突发奇想,是不是可以拿这些依存边作为一个Topic,利用倒排索引建立主题向量,这样就可以造出一大堆丰富的原始特征,然后再找个算法作特征选择过滤,再完成同义词聚类... ...
基于n-gram及依存分析的中文自动差错方法(马金山,刘挺,李生)
斯坦福大学自然语言处理第四课“语言模型(Language Modeling)”
中文语法错误诊断评测CGED(ACL-IJCNLP2015 workshop)
标签:
原文地址:http://my.oschina.net/keyven/blog/516808