标签:
Hadoop伪分布环境搭建的“三步”总流程

第一 、Jdk安装和环境变量配置
1、先检测一下,jdk是否安装
java - version

2、查看下CentOS的位数
file /bin/ls

3、切换到usr/,创建java/目录
cd /
ls
cd usr/
mkdir java
cd java/
ls

4、上传本地下载好的 ,显示上传命令没有安装
rz

5 、下载rz 、sz命令
yum -y install lrzsz

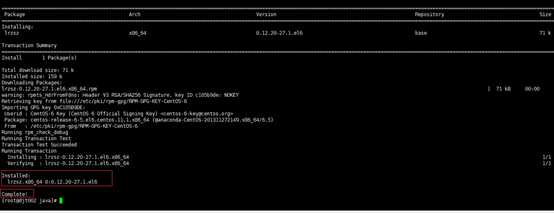
6 、上传本地下载好的 jdk-7u79-linux-x64.tar.gz
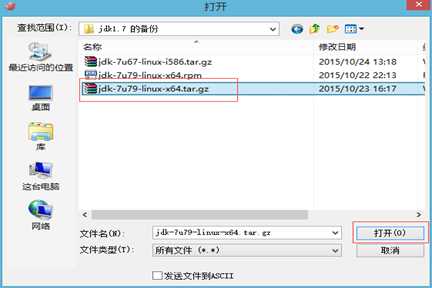
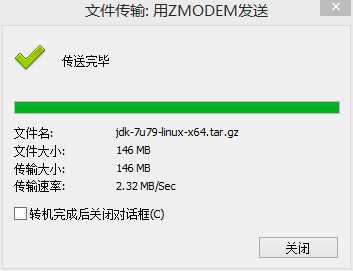
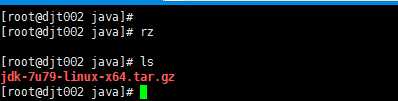
7、查看是否,上次成功!jdk-7u79-linux-x64.tar.gz
rz
8、对安装包 jdk-7u79-linux-x64.tar.gz ,进行解压。
tar zxvf jdk-7u79-linux-x64.tar.gz
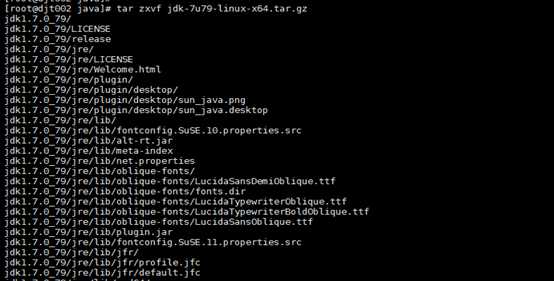
解压完毕!
9、jdk的环境变量配置

cd /etc/profile.d
ls
vi java.sh
JAVA_HOME=/usr/java/jdk1.7.0_79
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export JAVA_HOME PATH CLASSPATH
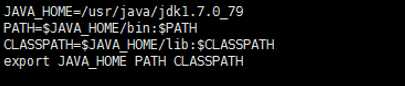
10、使用source来使刚jdk环境变量配置文件生效。
source /etc/profile.d/java.sh

11、配置hosts文件 ,添加hostname与IP间的关系,方便日后的访问。
12、首先,ifconfig查看IP
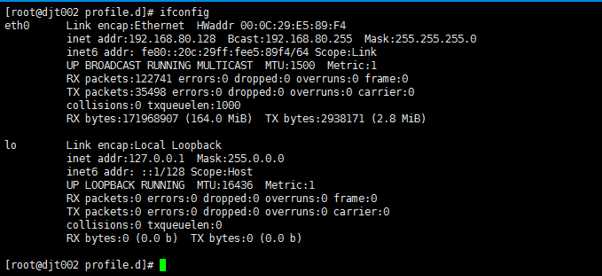
13、vi /etc/hosts ,来修改hosts文件

以:wq保存退出。
14、 准备Hadoop专用用户和组
groupadd hadoop 这是创建hadoop用户组
useradd -g hadoop hadoop 这是新建hadoop用户并增加到hadoop组中
passwd hadoop hadoop用户密码,为hadoop

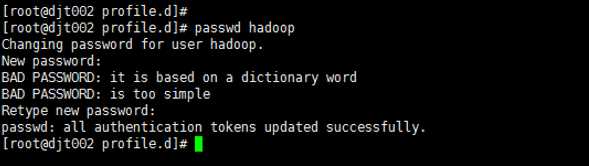
15、因Hadoop使用端口比较多,建议关闭防火墙避免出现不必要的问题,生产环境中可以对相应端口做安全控制。先需要关闭防火墙
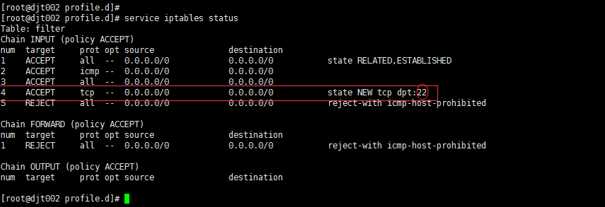
Centos6.5自带防火墙是iptables防火墙,没有firewall防火墙。
service iptables status
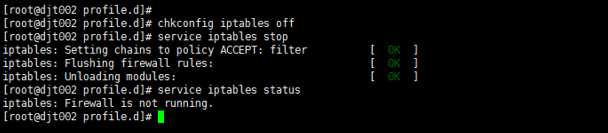
16、 那么,需要使用命令来关闭防火墙。有两种方式:
chkconfig iptables off 这种方式是永久性关闭,系统重启后不会复原。
service iptables stop 这种方式是即时生效,系统重启后会复原。
第二、 SSH配置
1 配置SSH实现无密码验证配置,首先切换到刚创建的hadoop用户下。
由于hadoop需要无密码登录作为datanode的节点,而由于部署单节点的时候,当前节点既是namenode又是datanode,所以此时需要生成无密码登录的ssh。方法如下:
su hadoop
cd

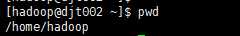
2 、创建.ssh目录,生成密钥
mkdir .ssh
ssh-keygen -t rsa
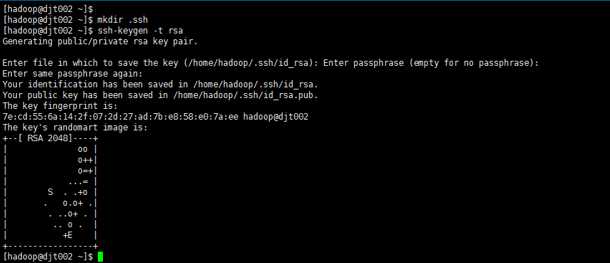
3 、切换到.ssh目录下,进行查看公钥和私钥
cd .ssh
ls

4、将公钥复制到日志文件里。查看是否复制成功
cp id_rsa.pub authorized_keys
ls

5、查看日记文件具体内容
vi authorized_keys

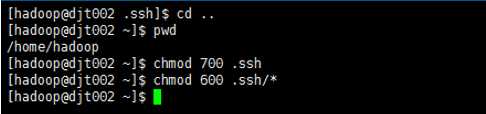
6、退回到/home/hadoop/,来赋予权限
cd ..
chmod 700 .ssh 将.ssh文件夹的权限赋予700
chmod 600 .ssh/* 将.ssh文件夹里面的文件的权限赋予600
7、切换到root用户下,安装ssh插件
su root
yum -y install openssh-clients



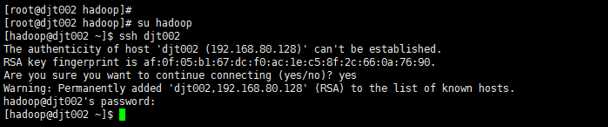
8、切换到/home/hadoop/,测试ssh无密码访问、
su hadoop
ssh djt002
yes
第三 、hadoop环境变量配置
接下来,
搭建hadoop伪分布式环境
下载并解压Hadoop2.2.0,把文件放到/usr/java/目录下,注意:下载前确认一下你的Linux系统是64位系统还是32位系统,分别下载对应的版本,如果下载错了,后面会有很多问题
1首先,切换到/usr/java/ ,再切换到root用户下,再 /root/java
cd /usr/java
su root

2、使用wget命令安装,没安装?
yum -y install wget


3、用wget命令在线下载hadoop-2.2.0-x64.tar.gz
wget http://hadoop.f.dajiangtai.com/hadoop2.2/hadoop-2.2.0-x64.tar.gz

或者 3用rz命令从Windows来上传hadoop-2.2.0-x64.tar.gz到/usr/java/下。
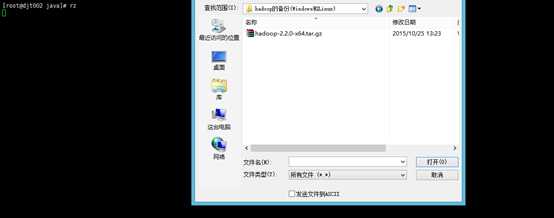
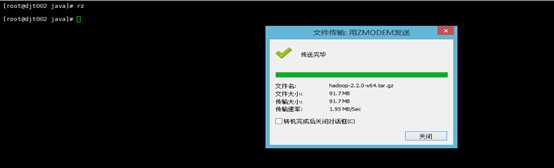
4、查看,解压,
ls
tar axvf hadoop-2.2.0-x64.tar.gz



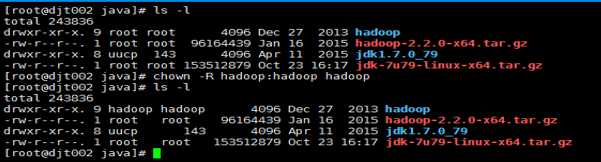
5、将文件名hadoop-2.2.0修改为hadoop
mv hadoop-2.2.0 hadoop

6、将刚改名的hadoop文件,权限赋给hadoop用户
chown -R hadoop:hadoop hadoop
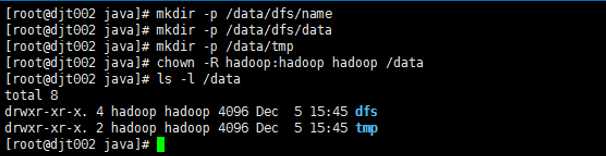
7先创建hadoop数据目录 ,将整个data目录权限赋予给hadoop用户
mkdir -p /data/dfs/name
mkdir -p /data/dfs/data
mkdir -p /data/tmp
chown -R hadoop:hadoop hadoop /data
8、修改hadoop对应的配置文件
切换到hadoop用户,切换到hadoop目录
su hadoop
cd hadoop

9、查看下etc/hadoop的配置文件
cd etc/
ls
cd hadoop/
ls

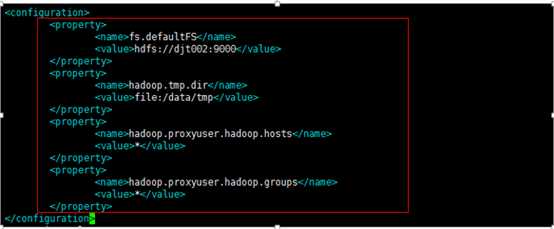
10、修改etc/hadoop/core-site.xml配置文件,添加如下信息
vi core-site.xml

下面这里配置的是HDFS(hadoop)的分布式文件系统的地址及端口号
<property>
<name>fs.defaultFS</name>
<value>hdfs://djt002:9000</value>
</property>

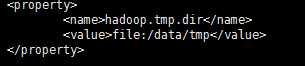
下面配置的是HDFS路径的存放数据的公共目录
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/tmp</value>
</property>
下面配置的是,因为在hadoop1.0中引入了安全机制,所以从客户端发出的作业提交者全变成了hadoop,不管原始提交者是哪个用户,为了解决该问题,引入了安全违章功能,允许一个超级用户来代替其他用户来提交作业或者执行命令,而对外来看,执行者仍然是普通用户。所以
配置设为任意客户端
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
配置设为任意用户组
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
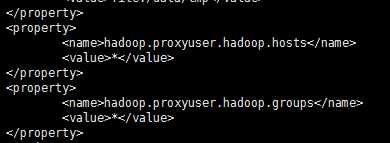
即总的是如下:
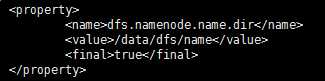
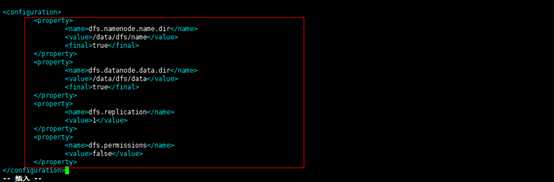
11修改etc/hadoop/hdfs-site.xml配置文件,添加如下信息。
vi hdfs-site.xml
下面这是配置的是namenode文件目录
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/dfs/name</value>
<final>true</final>
</property>
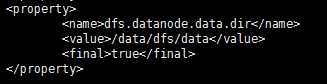
下面这是配置的是datanode文件目录
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dfs/data</value>
<final>true</final>
</property>
下面配置的是数据块副本和HDFS权限
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
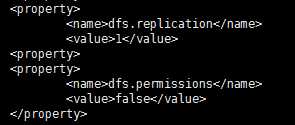
总的是如下:
12、修改etc/hadoop/mapred-site.xml配置文件,添加如下信息。
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml

配置的是mapreduce环境为yarn
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

13 、修改etc/hadoop/yarn-site.xml配置文件,添加如下信息。
vi yarn-site.xml
为了能够运行mapreduce程序,我们需要让.nodemanger在启动时加载shuffle。所以需要下面设置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
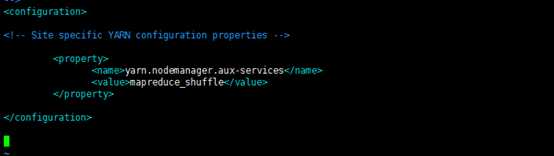
14、修改etc/hadoop/slaves,添加如下信息。即slaves文件
vi slaves

现在是伪分布式单节点集群,所以datanode和namedata在一个节点上。
修改为


15、设置Hadoop环境变量
切换到root用户下,修改/etc/profile文件
su root
vi /etc/profile

不是HADOOP_HOME=/usr/java/hadoop-2.2.0 ,因为前面更改名字了
HADOOP_HOME=/usr/java/hadoop
PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_HOME PATH
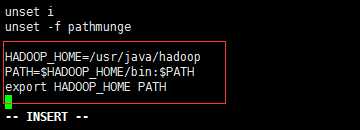
总结 : jdk环境变量配置是放在/etc/profile.d hadoop环境变量配置是放在/etc/profile
16 、使配置文件生效
source /etc/profile
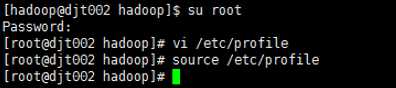
第四 测试hadoop运行
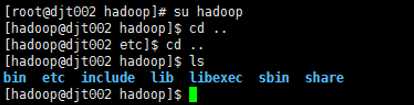
1 切换到hadoop用户,退回到hadoop目录下。
su hadoop
cd ..
cd ..
ls
2 格式化namenode
bin/hadoop namenode -format


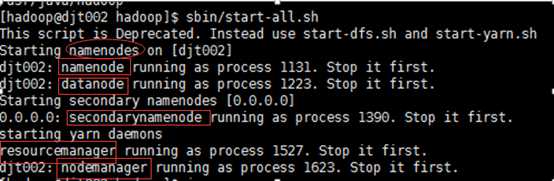
3 启动集群
sbin/start-all.sh
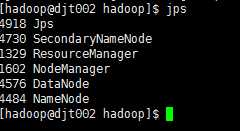
4 查看集群进程
jps
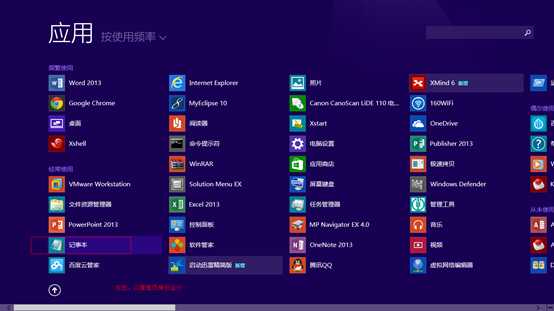
5 管理员身份运行记事本
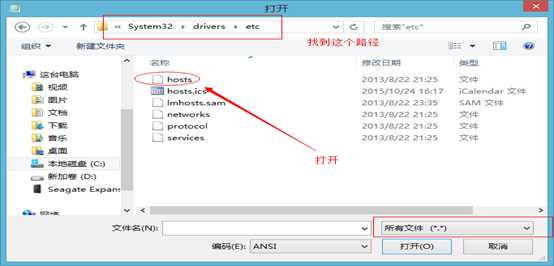
6 本地的hosts文件
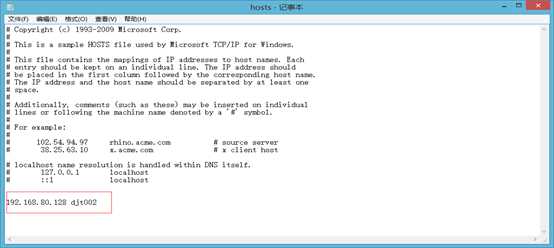
然后,保存,再关闭。
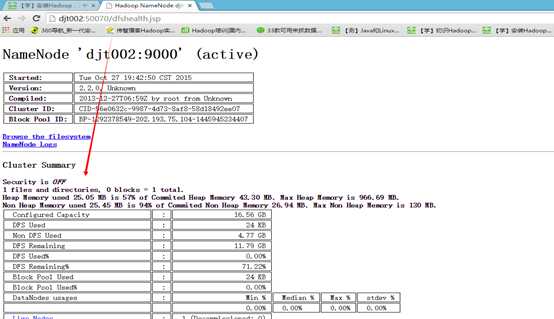
7 最后,现在是来验证hadoop是否安装成功。
在Windows上可以通过 http://djt002:50070 访问WebUI来查看NameNode,集群、文件系统的状态。这里是HDFS的Web页面
8新建djt.txt,用来测试。通过hadoop自带的wordcount程序来测试


然后,保存退出,

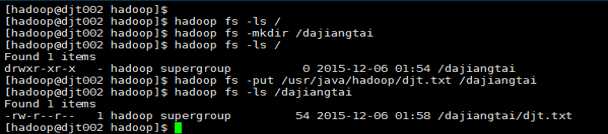
9 查看hdfs的文件目录。
hadoop fs -ls /
hadoop fs -mkdir /dajiangtai
hadoop fs -ls /
hadoop fs -put /usr/java/hadoop/djt.txt /dajiangtai
hadoop fs -ls /dajiangtai
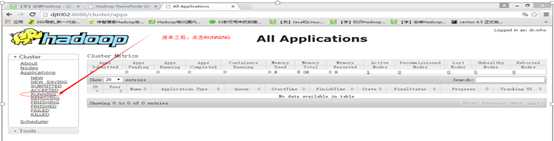
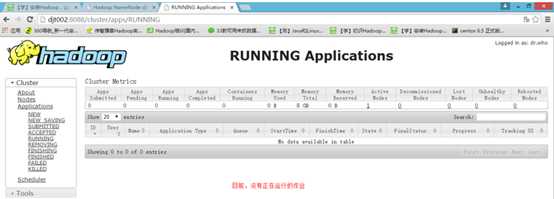
10 打开web页面,查看作业的动态情况
http://djt002:8088/cluster/apps
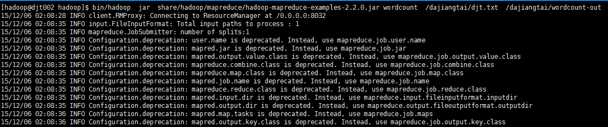
11 执行Hadoop自带的wordcount程序来测试运行下
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /dajiangtai/djt.txt /dajiangtai/wordcount-out
解释下,/dajiangtai/djt.txt是输入路径,/dajiangtai/wordcount-out是输出路径。
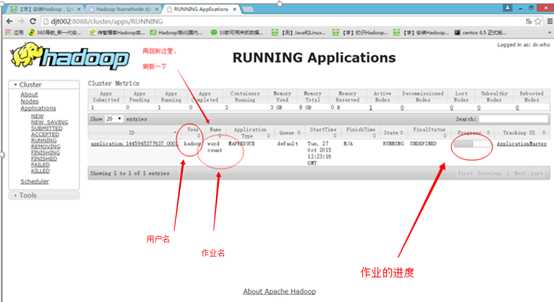
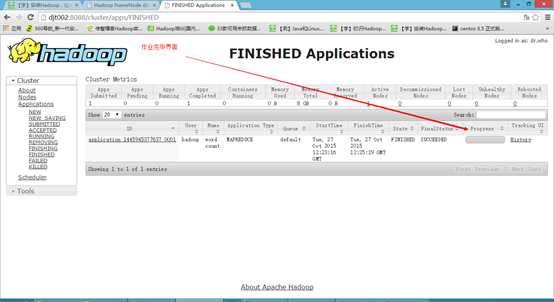
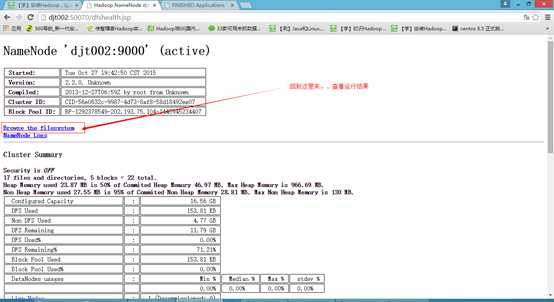
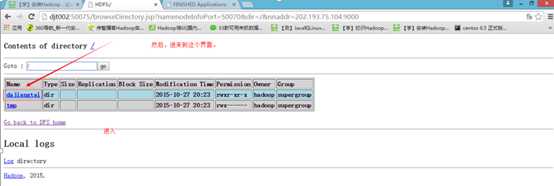
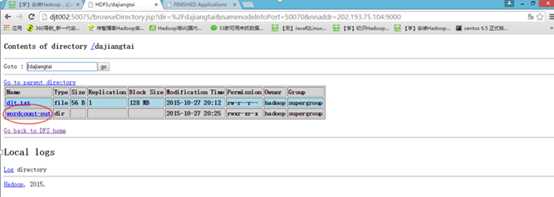
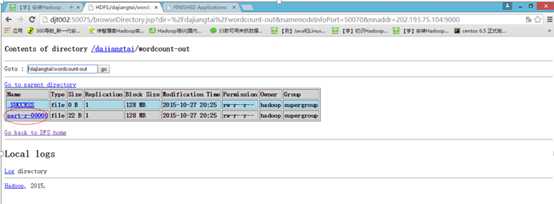
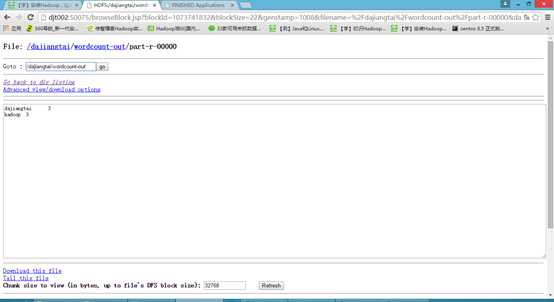
如果以上都OK,那么恭喜你,你的Hadoop单节点伪分布运行环境已经搭建成功了!
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5068426.html