标签:
Zookeeper是Hadoop下的一个子项目,它是一个针对大型分布式系统的可靠的协调系统,提供的功能包括命名服务、配置维护、分布式同步、集群服务等。
Zookeeper是可以集群复制的,集群间通过Zab(Zookeeper Atomic Broadcast)协议来保持数据的一致性。
该协议包括2个阶段:leader election阶段和Actomic broadcast阶段。集群中将选举出一个leader,其他的机器则称为follower,所有的写操作都被传送给leader,并通过broadcast将所有的更新告诉follower。当leader崩溃或者leader失去大多数的follower时,需要重新选举出一个新的leader,让所有的服务器都恢复到一个正确的状态。当leader被选举出来,且大多数服务器完成了和leader的状态同步后,leader election的过程就结束了,将进入Atomic broadcast的过程。Actomic broadcast同步leader和follower之间的信息,保证leader和follower具备相同的系统状态。
Zookeeper集群的结构图如下:
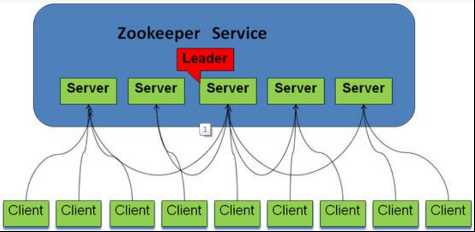
路由和负载均衡的实现
当服务越来越多,规模越来越大时,对应的机器数量也越来越庞大,单靠人工来管理和维护服务及地址的配置信息,已经越来越困难。并且,依赖单一的硬件负载均衡设备或者使用LVS、Nginx等软件方案进行路由和负载均衡调度,单点故障的问题也开始凸显,一旦服务路由或者负载均衡服务器宕机,依赖其的所有服务均将失效。如果采用双机高可用的部署方案,使用一台服务器“stand by”,能部分解决问题,但是鉴于负载均衡设备的昂贵成本,已难以全面推广。
一旦服务器与ZooKeeper集群断开连接,节点也就不存在了,通过注册相应的watcher,服务消费者能够第一时间获知服务提供者机器信息的变更。利用其znode的特点和watcher机制,将其作为动态注册和获取服务信息的配置中心,统一管理服务名称和其对应的服务器列表信息,我们能够近乎实时地感知到后端服务器的状态(上线、下线、宕机)。Zookeeper集群间通过Zab协议,服务配置信息能够保持一致,而Zookeeper本身容错特性和leader选举机制,能保证我们方便地进行扩容。
Zookeeper中,服务提供者在启动时,将其提供的服务名称、服务器地址、以节点的形式注册到服务配置中心,服务消费者通过服务配置中心来获得需要调用的服务名称节点下的机器列表节点。通过前面所介绍的负载均衡算法,选取其中一台服务器进行调用。当服务器宕机或者下线时,由于znode非持久的特性,相应的机器可以动态地从服务配置中心里面移除,并触发服务消费者的watcher。在这个过程中,服务消费者只有在第一次调用服务时需要查询服务配置中心,然后将查询到的服务信息缓存到本地,后面的调用直接使用本地缓存的服务地址列表信息,而不需要重新发起请求到服务配置中心去获取相应的服务地址列表,直到服务的地址列表有变更(机器上线或者下线),变更行为会触发服务消费者注册的相应的watcher进行服务地址的重新查询。这种无中心化的结构,使得服务消费者在服务信息没有变更时,几乎不依赖配置中心,解决了之前负载均衡设备所导致的单点故障的问题,并且大大降低了服务配置中心的压力。
通过Zookeeper来实现服务动态注册、机器上线与下线的动态感知,扩容方便,容错性好,且无中心化结构能够解决之前使用负载均衡设备所带来的单点故障问题。只有当配置信息更新时服务消费者才会去Zookeeper上获取最新的服务地址列表,其他时候使用本地缓存即可,这样服务消费者在服务信息没有变更时,几乎不依赖配置中心,能大大降低配置中心的压力。
标签:
原文地址:http://www.cnblogs.com/chy2055/p/5180386.html