标签:
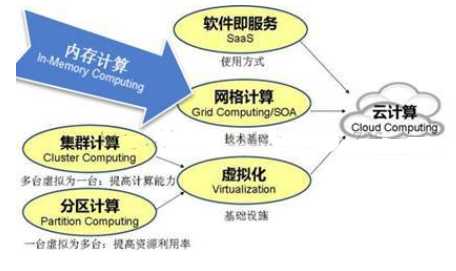
如果说云计算这个新瓶装的是虚拟化+ SOA/网格计算+SaaS(软件即服务)的老酒,那么内存计算则重点是释放了计算这一部分的能量。
但是对内存计算经常有一些误解:
1、大容量内存很贵
2、 内存计算不会持久化:实际上几乎所有的内存计算中间件都提供多种内存备份、持久存储备份以及基于磁盘的swap空间溢出的策略。
3、内存计算要取代数据仓库:内存计算的目的是要改善那些需要OLTP和OLAP混合处理的可操作数据集(Operational Dataset)的计算,而非历史数据集(Historical dataset)。简言之,内存计算不是要把企业的所有数据都放进内存。
4、闪存已经足够快了:内存计算不是要达到2-3倍的边际效应提升(Marginal Effect),而是10-100倍的提升,使之前那些不可行的业务和服务成为可能。
5、内存计算等于内存数据库:首先,内存计算是一种技术而不是某种产品。其次,内存数据库只是目前内存计算触手可及的成果,内存计算长期的发展还是在流式处理(Stream Processing)上。此外,内存计算与传统内存数据库的区别是:内存计算是为分布式、弹性环境以及内存数据处理而设计的。
一、内存计算产品分类
根据内存计算技术的发展顺序,内存计算大致可以分为三类产品:
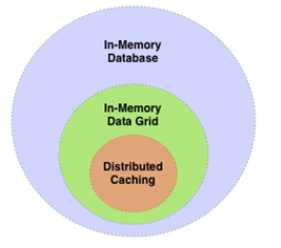
1、 分布式缓存(Memcached/Redis):主要使用场景就是将频繁访问的数据保存在内存中避免磁盘加载。多数产品都是分布式内存key/value存储,并提供简单的put和get方法。随着不断成熟,与后端的read/write-through,ACID事务,复制和分区,eviction策略等也逐渐加入到产品中,这些特性也成为了后来出现的IMDG/IMCG产品的基础。
2、内存数据/计算网格(IMDG/IMCG, GemFire/Hazelcast/GridGain):数据网格的显著特性是co-location计算,将计算过程发送到数据本地执行。这是数据/计算网格的关键创新点,在数据量不断增长的情况下再加数据抓取过来执行计算已经变得不现实了。这种创新也不仅使内存计算从简单的缓存产品进化,也激发了后来IMDB的诞生。
3、分布式内存数据库(IMDB, VoltDB/Impala):分布式内存数据库的显著特性是增加了基于标准SQL或MapReduce的MPP(大规模并行处理)能力。如果说数据网格的核心是解决数据量不断增长下计算的困境,那么分布式内存数据库就是解决计算复杂度不断增长的困境。它提供了分布式SQL、复杂(分布式共享)索引、MapReduce处理等工具。

值得注意的是,随着技术的发展,有些界限不再那样清晰。像现在很多IMDG产品已经具有IMDB的特性,能够提供复杂的分布式SQL和MapReduce计算能力。不管怎样,这些产品中的核心技术和算法都是不变的,所以学习时不必过分纠结某个产品到底属于那一类。
二、应用场景
以上提到的各种内存计算产品可以应用到大数据处理的各个环节上,如下图所示,其中涉及内存计算的技术标成红色
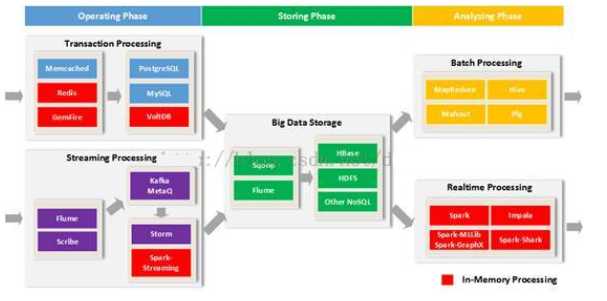
1)事务处理:主要分为Cache(Memcached, Redis, GemFire)、RDBMS、NewSQL(以VoltDB为首的)三部分,缓存和NewSQL数据库是关注的重点。
2)流式处理:Storm本身只是计算的框架,而Spark-Streaming才实现了内存计算式的流处理。
3)分析阶段的对比:
通用处理:MapReduce,Spark
查询:Hive,Pig,Spark-Shark
数据挖掘:Mahout,Spark-MLLib,Spark-GraphX
从上可以看出,Spark生态圈的子项目以及Impala都是值得关注的重点。
三、核心技术
因为内存计算主要释放了云计算中的计算部分的能量,所以它主要涉及并行/分布式计算和内存数据管理这两大方面的技术体系:
1、并行/分布式计算:网络拓扑、RPC通信、系统同步、持久化、日志。
2、内存数据管理:字典编码、数据压缩、内存中数据格式、数据操作、内存索引、内存中并发控制和事务。
以下简单列举了内存计算主流产品中涉及到的技术点:
(1)Memcached/Redis:一致性哈希。
(2)GridGain:DHT、refresh-ahead、off-heap、continuous query。
(3)Infinispan:LIRS eviction。
(4)Spark(LMAX):immutable model(RDD)。
(5)VoltDB:single-threaded。
(6)Impala(Dremel):LLVM optimizing、nested record、MPP
标签:
原文地址:http://www.cnblogs.com/moonandstar08/p/5218419.html