标签:
QQ群: 281442983 (点击链接加入群:http://jq.qq.com/?_wv=1027&k=29LoD19) QQ:1542385235
根据did you know(http://didyouknow.org/)的数据,目前互联网上可访问的信息数量接近1秭= 1百万亿亿 (1024)。毫无疑问,各个大型网站也都存储着海量的数据,这些海量的数据如何有效存储,是每个大型网站的架构师必须要解决的问题。分布式存储技术就是为了解决这个问题而发展起来的技术,下面让将会详细介绍这个技术及应用。
分布式存储概念
与目前常见的集中式存储技术不同,分布式存储技术并不是将数据存储在某个或多个特定的节点上,而是通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。
具体技术及应用:
海量的数据按照结构化程度来分,可以大致分为结构化数据,非结构化数据,半结构化数据。
本文接下来将会分别介绍这三种数据如何分布式存储。
结构化数据的存储及应用
所谓结构化数据是一种用户定义的数据类型,它包含了一系列的属性,每一个属性都有一个数据类型,存储在关系数据库里,可以用二维表结构来表达实现的数据。
大多数系统都有大量的结构化数据,一般存储在Oracle或MySQL的等的关系型数据库中,当系统规模大到单一节点的数据库无法支撑时,一般有两种方法:垂直扩展与水平扩展。
· 垂直扩展:垂直扩展比较好理解,简单来说就是按照功能切分数据库,将不同功能的数据,存储在不同的数据库中,这样一个大数据库就被切分成多个小数据库,从而达到了数据库的扩展。一个架构设计良好的应用系统,其总体功能一般肯定是由很多个松耦合的功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一张或多张表。各个功能模块之间交互越少,越统一,系统的耦合度越低,这样的系统就越容易实现垂直切分。
· 水平扩展:简单来说,可以将数据的水平切分理解为按照数据行来切分,就是将表中的某些行切分到一个数据库中,而另外的某些行又切分到其他的数据库中。为了能够比较容易地判断各行数据切分到了哪个数据库中,切分总是需要按照某种特定的规则来进行的,如按照某个数字字段的范围,某个时间类型字段的范围,或者某个字段的hash值。
垂直扩展与水平扩展各有优缺点,一般一个大型系统会将水平与垂直扩展结合使用。
实际应用:图1是为核高基项目设计的结构化数据分布式存储的架构图。

图1可水平&垂直切分扩展的数据访问框架
· 采用了独立的分布式数据访问层,后端分布式数据库集群对前端应用透明。
· 集成了Memcached集群,减少对后端数据库的访问,提高数据的查询效率。
· 同时支持垂直及水平两种扩展方式。
· 基于全局唯一性主键范围的切分方式,减轻了后续维护的工作量。
· 全局唯一性主键的生成采用DRBD+Heartbeat技术保证了可靠性。
· 利用MySQL Replication技术实现高可用的架构。
注:以上的数据切分方案并不是唯一扩展MySql的方法,有兴趣的读者可以关注一下” 云计算时代的MySQL-Clustrix Sierra分布式数据库系统”。
非结构化数据的存储及应用
相对于结构化数据而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
分布式文件系统是实现非结构化数据存储的主要技术,说到分布式文件系统就不得不提GFS(全称为"Google File System"),GFS的系统架构图如下图所示。
N2[X@F}4`0.png)
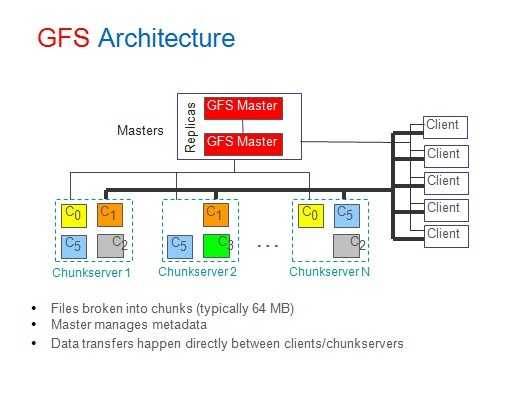
图2 Google-file-system架构图
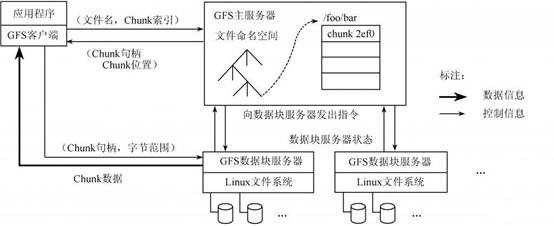
图3 Google-file-system架构图(详细)
GFS将整个系统分为三类角色:Client(客户端)、Master(主服务器)、Chunk Server(数据块服务器)。
· Client(客户端):是GFS提供给应用程序的访问接口,它是一组专用接口,不遵守POSIX规范,以库文件的形式提供。应用程序直接调用这些库函数,并与该库链接在一起。
· Master(主服务器):是GFS的管理节点,主要存储与数据文件相关的元数据,而不是Chunk(数据块)。元数据包括:命名空间(Name Space),也就是整个文件系统的目录结构,一个能将64位标签映射到数据块的位置及其组成文件的表格,Chunk副本位置信息和哪个进程正在读写特定的数据块等。还有Master节点会周期性地接收从每个Chunk节点来的更新("Heart- beat")来让元数据保持最新状态。
· Chunk Server(数据块服务器):负责具体的存储工作,用来存储Chunk。GFS将文件按照固定大小进行分块,默认是64MB,每一块称为一个Chunk(数据块),每一个Chunk以Block为单位进行划分,大小为64KB,每个Chunk有一个唯一的64位标签。GFS采用副本的方式实现容错,每一个Chunk有多个存储副本(默认为三个)。 Chunk Server的个数可有有多个,它的数目直接决定了GFS的规模。
GFS之所以重要的原因在于,在Google公布了GFS论文之后,许多开源组织基于GFS的论文开发了各自的分布式文件系统,其中比较知名的有HDFS,MooseFS,MogileFS等。
实际应用:由于核高基的项目中未来会有大量的数据与应用需要存储,所以我们设计时也采用分布式文件系统的方案,由于开源的分布式文件系统可以基本满足我们需求,另外从时间上来说也比较紧张,所以我们采用了开源的MooseFS作为底层的分布式文件系统。
· MooseFS存在的问题:由于MooseFS是也是按照GFS论文设计的,只有一个Master(主服务器),虽然可以增加一个备份的日志服务器,但是还是存在Master无法扩展的问题,当单一Master节点上存储的元数据越来越多的时候,Master节点占用的内存会越来越多,直到达到服务器的内存上限,所以单一Master节点存在内存上的瓶颈,只能存储有限的数据,可扩展性差,并且不稳定。
· 对MooseFS的优化:面对MooseFS存在的问题,我们采用了类似分布式数据库中的“Sharding”技术,设计了一个分布式文件系统访问框架,可以做到对分布式文件系统做垂直与水平切分。这样就最大限度的保证了MooseFS系统的可扩展性与稳定性。
下图是为核高基项目设计的非结构化数据分布式存储的架构图。我们设计了两种访问方式,一种是类似GFS的API访问方式,以库文件的方式提供,应用程序通过调用API直接访问分布式文件系统。第二种是通过RESTful web Service访问。
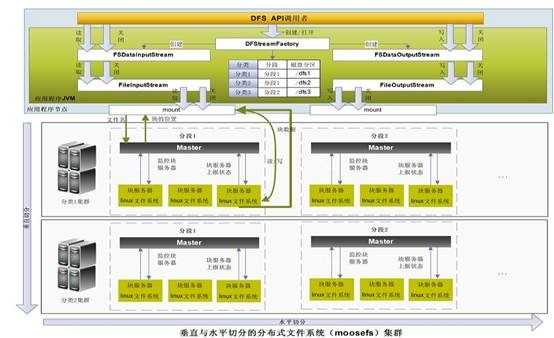
图4可水平&垂直切分扩展的分布式文件系统访问框架(API版)
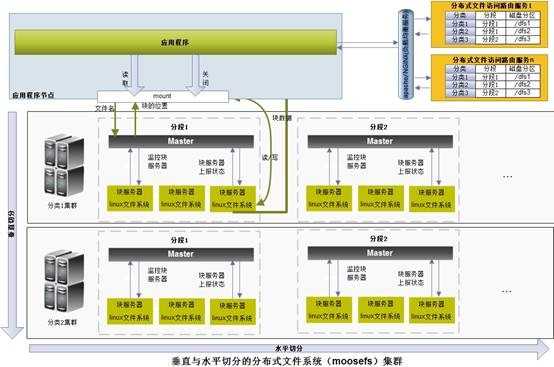
图5可水平&垂直切分扩展的分布式文件系统访问框架(RESTful web Service版)
半结构化数据的存储及应用
就是介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据, 半结构化数据模型具有一定的结构性,但较之传统的关系和面向对象的模型更为灵活。半结构数据模型完全不基于传统数据库模式的严格概念,这些模型中的数据都是自描述的。
由于半结构化数据没有严格的schema定义,所以不适合用传统的关系型数据库进行存储,适合存储这类数据的数据库被称作“NoSQL”数据库。
NoSQL的定义:
被称作下一代的数据库,具有非关系型,分布式,轻量级,支持水平扩展且一般不保证遵循ACID原则的数据储存系统。“NoSQL”其实是具有误导性的别名,称作Non Relational Database(非关系型数据库)更为恰当。所谓“非关系型数据库”指的是:
· 使用松耦合类型、可扩展的数据模式来对数据进行逻辑建模(Map,列,文档,图表等),而不是使用固定的关系模式元组来构建数据模型。
· 以遵循于CAP定理(能保证在一致性,可用性和分区容忍性三者中中达到任意两个)的跨多节点数据分布模型而设计,支持水平伸缩。这意味着对于多数据中心和动态供应(在生产集群中透明地加入/删除节点)的必要支持,也即弹性(Elasticity)。
· 拥有在磁盘或内存中,或者在这两者中都有的,对数据持久化的能力,有时候还可以使用可热插拔的定制存储。
· 支持多种的‘Non-SQL’接口(通常多于一种)来进行数据访问。
图6是Sourav Mazumder提出的NoSQL总体架构:
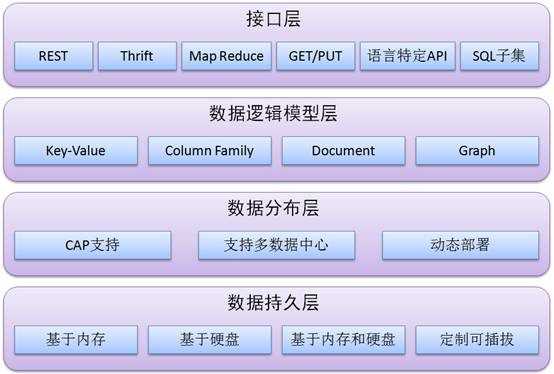
图6 NoSQL总体架构
· 接口:REST (HBase,CouchDB,Riak等),MapReduce (HBase,CouchDB,MongoDB,Hypertable等),Get/Put (Voldemort,Scalaris等),Thrift (HBase,Hypertable,Cassandra等),语言特定的API(MongoDB)。
· 逻辑数据模型:面向键值对的(Voldemort,Dynomite 等),面向Column Family的(BigTable,HBase,Hypertable 等),面向文档的(Couch DB,MongoDB等),面向图的(Neo4j, Infogrid等)
· 数据分布模型:致性和可用性(HBase,Hypertable, MongoDB等), 可用性和可分区性(Cassandra等)。一致性和可分区性的组合会导致一些非额定的节点产生可用性的损失。有趣的是目前还没有一个“非关系型数据库”支持这一组合。
· 数据持久性:基于内存的(如Redis,Scalaris, Terrastore),基于磁盘的(如MongoDB,Riak等),或内存及磁盘二者的结合(如 HBase,Hypertable,Cassandra)。存储的类型有助于我们辨别该解决方案适用于哪种类型。然而,在大多数情况下人们发现基于组合方 案的解决方案是最佳的选择。既能通过内存数据存储支持高性能,又能在写入足够多的数据后存储到磁盘来保证持续性。
NoSQL中的重要理论基础:
CAP理论:
· C: Consistency 一致性
· A: Availability 可用性(指的是快速获取数据)
· P: Tolerance of network Partition 分区容忍性(分布式)
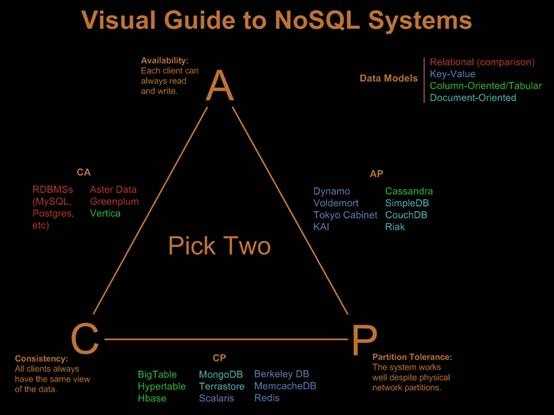
图7 CAP理论
CAP原理告诉我们,这三个因素最多只能满足两个,不可能三者兼顾。对于分布式系统来说,分区容错是基本要求,所以必然要放弃一致性。对于大型网站来说,分区容错和可用性的要求更高,所以一般都会选择适当放弃一致性。对应CAP理论,NoSQL追求的是AP,而传统数据库追求的是CA,这也可以解释为什么 传统数据库的扩展能力有限的原因。
BASE模型:
说起来很有趣,BASE的英文意义是碱,而ACID是酸。真的是水火不容啊。
· Basically Availble –基本可用
· Soft-state –软状态/柔性事务
· Eventual Consistency –最终一致性
BASE模型是传统ACID模型的反面,不同于ACID模型,BASE强调牺牲高一致性,从而获得可用性或可靠性。
基本可用是指通过Sharding,允许部分分区失败。
软状态是指异步,允许数据在一段时间内的不一致,只要保证最终一致就可以了。
最终一致性是整个NoSQL中的一个核心理念,强调最终数据是一致的就可以了,而不是时时一致。
Quorum NRW:

图8 Quorum NRW
N: 复制的节点数,即一份数据被保存的份数。
R: 成功读操作的最小节点数,即每次读取成功需要的份数。
W: 成功写操作的最小节点数 ,即每次写成功需要的份数。
这三个因素决定了可用性,一致性和分区容错性。只需W + R > N,就可以保证强一致性。
实际应用: 今年上半年我在aspire的搜索团队中负责互联网搜索的设计与开发,我设计的网页爬虫系统就是采用Cassandra来存储网页与链接信息的。下面结合我的实际使用经验谈谈我对Cassandra的看法:
优点:
· 弹性扩展:由于Cassandra是完全分布式的,使用时不需要再像使用MySQL那样自己设计复杂的数据切分方案,也不再配置复杂的DRBD+Heartbeat,一切都变得非常简单了,只需要简单的配置就可以给一个集群中增加一个新的节点,而且对客户端完全是透明的,不需要任何更改。
· 灵活的schema:不需要象数据库一样预先设计schema,增加或者删除字段非常方便。
· 使用简单:由于没有类似SQL这样复杂的查询语言,学习成本不高,很容易上手。
缺点:
· 稳定性差:在我们的实际使用过程中发现,单机数据量达到200G以上,时不时就会发生宕机现象。
· 缺乏管理与分析工具:传统的关系型数据都有比较好用的管理与分析工具,使用这些工具可以轻松的管理数据库,查看数据,分析性能瓶颈等,而Cassandra确缺少类似的工具,就连简单的查看一条数据,都要通过编程才能看到。
QQ群: 281442983 (点击链接加入群:http://jq.qq.com/?_wv=1027&k=29LoD19) QQ:1542385235
标签:
原文地址:http://www.cnblogs.com/piwefei/p/5354301.html