标签:
HDFS全称是Hadoop Distributed System。HDFS是为以流的方式存取大文件而设计的。适用于几百MB,GB以及TB,并写一次读多次的场合。而对于低延时数据访问、大量小文件、同时写和任意的文件修改,则并不是十分适合。
目前HDFS支持的使用接口除了Java的还有,Thrift、C、FUSE、WebDAV、HTTP等。HDFS是以block-sized chunk组织其文件内容的,默认的block大小为64MB,对于不足64MB的文件,其会占用一个block,但实际上不用占用实际硬盘上的64MB,这可以说是HDFS是在文件系统之上架设的一个中间层。之所以将默认的block大小设置为64MB这么大,是因为block-sized对于文件定位很有帮助,同时大文件更使传输的时间远大于文件寻找的时间,这样可以最大化地减少文件定位的时间在整个文件获取总时间中的比例 。
构成HDFS主要是Namenode(master)和一系列的Datanode(workers)。Namenode是管理HDFS的目录树和相关的文件元数据,这些信息是以"namespace image"和"edit log"两个文件形式存放在本地磁盘,但是这些文件是在HDFS每次重启的时候重新构造出来的。Datanode则是存取文件实际内容的节点,Datanodes会定时地将block的列表汇报给Namenode。
由于Namenode是元数据存放的节点,如果Namenode挂了那么HDFS就没法正常运行,因此一般使用将元数据持久存储在本地或远程的机器上,或者使用secondary namenode来定期同步Namenode的元数据信息,secondary namenode有点类似于MySQL的Master/Salves中的Slave,"edit log"就类似"bin log"。如果Namenode出现了故障,一般会将原Namenode中持久化的元数据拷贝到secondary namenode中,使secondary namenode作为新的Namenode运行起来。
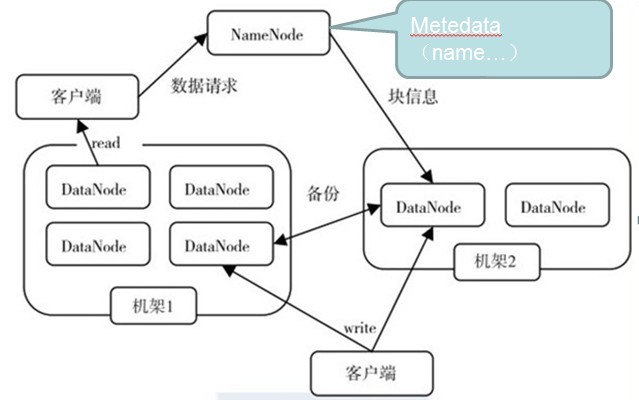
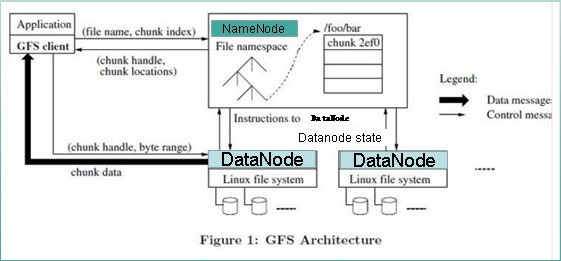

文件读取的过程如下:
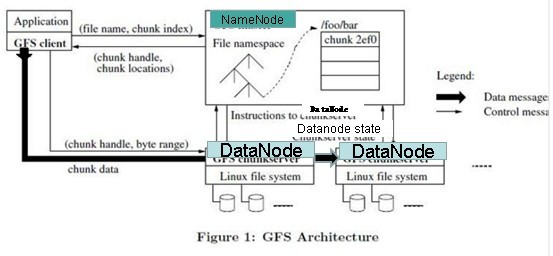

写入文件的过程比读取较为复杂:
标签:
原文地址:http://www.cnblogs.com/destim/p/5448533.html