标签:
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,那么这里就总结下Parquet数据结构到底是什么样的呢?
一个Parquet文件是由一个header以及一个或多个block块组成,以一个footer结尾。header中只包含一个4个字节的数字PAR1用来识别整个Parquet文件格式。文件中所有的metadata都存在于footer中。footer中的metadata包含了格式的版本信息,schema信息、key-value paris以及所有block中的metadata信息。footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。
这里注意,不像sequence files以及Avro数据格式文件的header以及sync markers是用来分割blocks。Parquet格式文件不需要sync markers,因此block的边界存储与footer的meatada中。
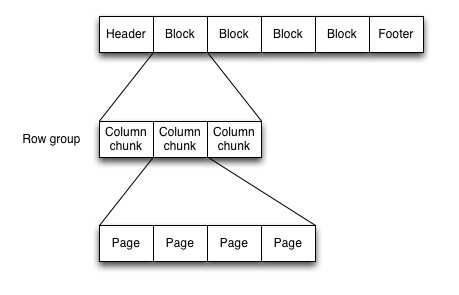
在Parquet文件中,每一个block都具有一组Row group,她们是由一组Column chunk组成的列数据。继续往下,每一个column chunk中又包含了它具有的pages。每个page就包含了来自于相同列的值.
Parquet同时使用更紧凑形式的编码,当写入Parquet文件时,它会自动基于column的类型适配一个合适的编码,比如,一个boolean形式的值将会被用于run-length encoding。
参考: 《Hadoop:The Definitive Guide, 4th Edition》
标签:
原文地址:http://www.cnblogs.com/yangsy0915/p/5565309.html