标签:
-- 创建一个测试表
create table tp_content(
id int not null,
title char(32) not null,
addtime date not null default ‘2000-01-01‘
) engine = myisam default charset = utf8;
-- 修改sql语句的结束符
delimiter $
-- 创建一个存储过程,插入100万条测试数据
CREATE PROCEDURE load_data()
begin
declare i int default 0;
while i < 1000000
do
insert into tp_content values (i,replace(uuid(), ‘-‘, ‘‘),adddate(‘2000-01-01‘,(rand(i)*36520) mod 3652));
set i = i + 1;
end while;
end
$
call load_data();
-- 修改回原来的结束符
delimiter ;
1、没有建立主键的对比
-- 运行distinct的sql语句

-- 运行group by的sql语句
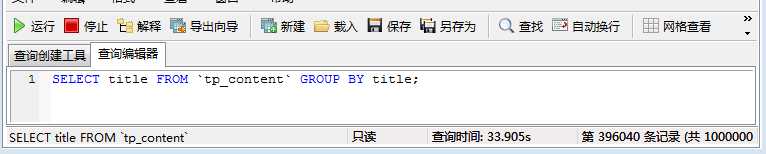
2、建立主键的对比
-- 建立id主键
alter table tp_content add primary key(id);
distinct

group by

结论:
上面的例子可以看出:没有建立主键时,distinct查询的速度要比group by快一点(distinct的时间是30.934s,group by的时间是33.905s),而建立主键后group by和distinct的效率都提高了,但是两者的速度依然差不多(distinct的时间是2.753s,group by的时间是2.762s)。
由于个人电脑的性能比较差,查出的时间比较久,所以这里的时间只是相对时间,假如用更好性能的电脑做实验,时间会快,但是我想结论应该是差不多的。
标签:
原文地址:http://www.cnblogs.com/loveyoume/p/5745805.html