标签:style blog class code java tar
写在前面:作者水平有限,欢迎不吝赐教,一切以最新源码为准。
InnoDB redo log

669 /* Offsets of a log file header */ 670 #define LOG_GROUP_ID 0 /* log group number */ 671 #define LOG_FILE_START_LSN 4 /* lsn of the start of data in this 672 log file */ 673 #define LOG_FILE_NO 12 /* 4-byte archived log file number; 674 this field is only defined in an 675 archived log file */ 676 #define LOG_FILE_WAS_CREATED_BY_HOT_BACKUP 16 677 /* a 32-byte field which contains 678 the string ‘ibbackup‘ and the 679 creation time if the log file was 680 created by ibbackup --restore; 681 when mysqld is first time started 682 on the restored database, it can 683 print helpful info for the user */ 684 #define LOG_FILE_ARCH_COMPLETED OS_FILE_LOG_BLOCK_SIZE 685 /* this 4-byte field is TRUE when 686 the writing of an archived log file 687 has been completed; this field is 688 only defined in an archived log file */ 689 #define LOG_FILE_END_LSN (OS_FILE_LOG_BLOCK_SIZE + 4) 690 /* lsn where the archived log file 691 at least extends: actually the 692 archived log file may extend to a 693 later lsn, as long as it is within the 694 same log block as this lsn; this field 695 is defined only when an archived log 696 file has been completely written */ 697 #define LOG_CHECKPOINT_1 OS_FILE_LOG_BLOCK_SIZE 698 /* first checkpoint field in the log 699 header; we write alternately to the 700 checkpoint fields when we make new 701 checkpoints; this field is only defined 702 in the first log file of a log group */ 703 #define LOG_CHECKPOINT_2 (3 * OS_FILE_LOG_BLOCK_SIZE) 704 /* second checkpoint field in the log 705 header */ 706 #define LOG_FILE_HDR_SIZE (4 * OS_FILE_LOG_BLOCK_SIZE)
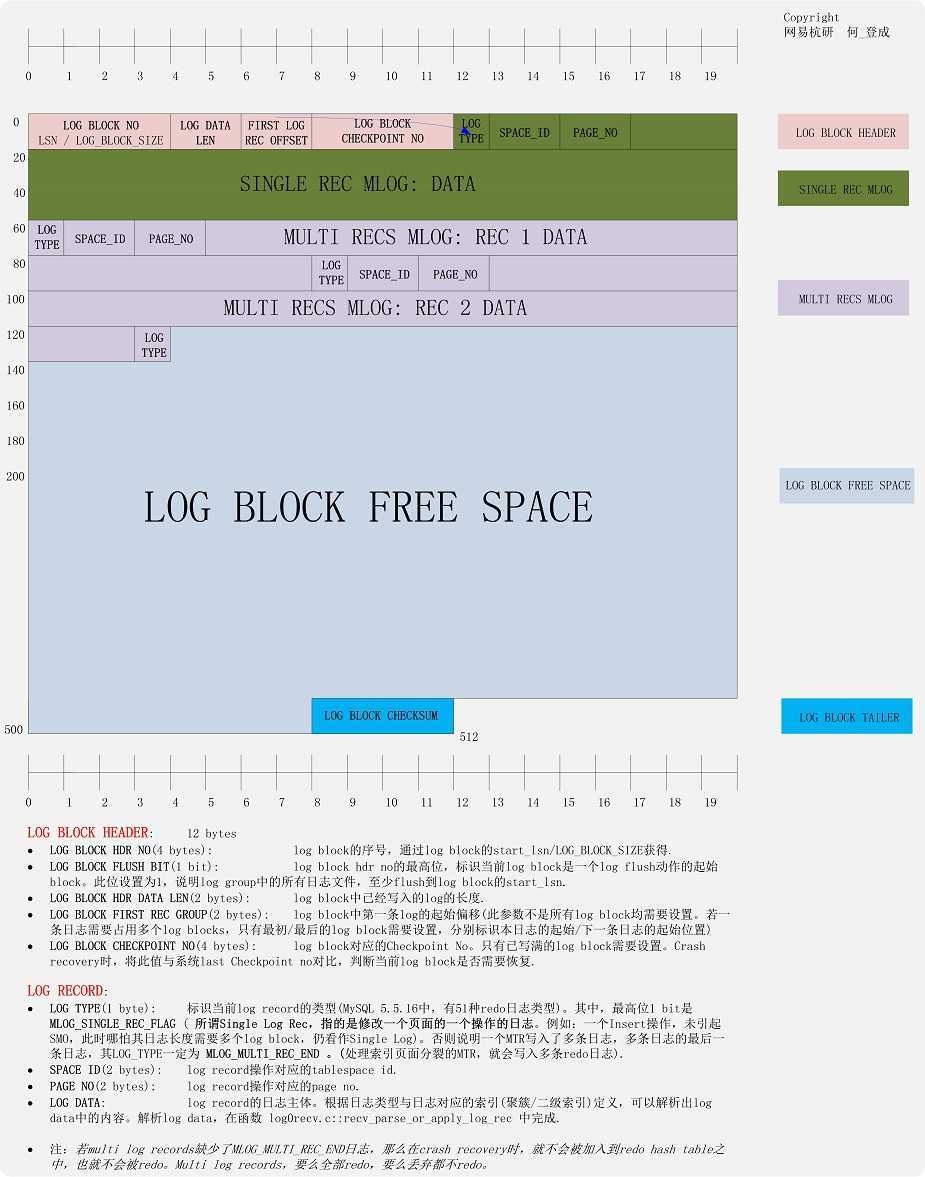
580 /* Offsets of a log block header */ 581 #define LOG_BLOCK_HDR_NO 0 /* block number which must be > 0 and 582 is allowed to wrap around at 2G; the 583 highest bit is set to 1 if this is the 584 first log block in a log flush write 585 segment */ 586 #define LOG_BLOCK_FLUSH_BIT_MASK 0x80000000UL 587 /* mask used to get the highest bit in 588 the preceding field */ 589 #define LOG_BLOCK_HDR_DATA_LEN 4 /* number of bytes of log written to 590 this block */ 591 #define LOG_BLOCK_FIRST_REC_GROUP 6 /* offset of the first start of an 592 mtr log record group in this log block, 593 0 if none; if the value is the same 594 as LOG_BLOCK_HDR_DATA_LEN, it means 595 that the first rec group has not yet 596 been catenated to this log block, but 597 if it will, it will start at this 598 offset; an archive recovery can 599 start parsing the log records starting 600 from this offset in this log block, 601 if value not 0 */ 602 #define LOG_BLOCK_CHECKPOINT_NO 8 /* 4 lower bytes of the value of 603 log_sys->next_checkpoint_no when the 604 log block was last written to: if the 605 block has not yet been written full, 606 this value is only updated before a 607 log buffer flush */ 608 #define LOG_BLOCK_HDR_SIZE 12 /* size of the log block header in 609 bytes */ 610 611 /* Offsets of a log block trailer from the end of the block */ 612 #define LOG_BLOCK_CHECKSUM 4 /* 4 byte checksum of the log block 613 contents; in InnoDB versions 614 < 3.23.52 this did not contain the 615 checksum but the same value as 616 .._HDR_NO */ 617 #define LOG_BLOCK_TRL_SIZE 4 /* trailer size in bytes */
| log_sys->lsn | 接下来将要生成的log record使用此lsn的值 |
|
log_sys->flushed_do_disk_lsn |
redo log file已经被刷新到此lsn。比该lsn值小的日志记录已经被安全的记录在磁盘上 |
|
log_sys->write_lsn |
当前正在执行的写操作使用的临界lsn值; |
|
log_sys->current_flush_lsn |
当前正在执行的write + flush操作使用的临界lsn值,一般和log_sys->write_lsn相等; |
|
log_sys->buf |
内存中全局的log buffer,和每个mtr自己的buffer有所区别; |
|
log_sys->buf_size |
log_sys->buf的size |
|
log_sys->buf_free |
写入buffer的起始偏移量 |
|
log_sys->buf_next_to_write |
buffer中还未写到log file的起始偏移量。下次执行write+flush操作时,将会从此偏移量开始 |
|
log_sys->max_buf_free |
确定flush操作执行的时间点,当log_sys->buf_free比此值大时需要执行flush操作,具体看log_check_margins函数
|
376 /* Mini-transaction handle and buffer */ 377 struct mtr_t{ 378 #ifdef UNIV_DEBUG 379 ulint state; /*!< MTR_ACTIVE, MTR_COMMITTING, MTR_COMMITTED */ 380 #endif 381 dyn_array_t memo; /*!< memo stack for locks etc. */ 382 dyn_array_t log; /*!< mini-transaction log */ 383 unsigned inside_ibuf:1; 384 /*!< TRUE if inside ibuf changes */ 385 unsigned modifications:1; 386 /*!< TRUE if the mini-transaction 387 modified buffer pool pages */ 388 unsigned made_dirty:1; 389 /*!< TRUE if mtr has made at least 390 one buffer pool page dirty */ 391 ulint n_log_recs; 392 /* count of how many page initial log records 393 have been written to the mtr log */ 394 ulint n_freed_pages; 395 /* number of pages that have been freed in 396 this mini-transaction */ 397 ulint log_mode; /* specifies which operations should be 398 logged; default value MTR_LOG_ALL */ 399 lsn_t start_lsn;/* start lsn of the possible log entry for 400 this mtr */ 401 lsn_t end_lsn;/* end lsn of the possible log entry for 402 this mtr */ 403 #ifdef UNIV_DEBUG 404 ulint magic_n; 405 #endif /* UNIV_DEBUG */ 406 };
(trx_commit_in_memory() / trx_commit_complete_for_mysql() / trx_prepare() e.t.c)-> trx_flush_log_if_needed()-> trx_flush_log_if_needed_low()-> log_write_up_to()-> log_group_write_buf().
srv_master_thread()-> (srv_master_do_active_tasks() / srv_master_do_idle_tasks() / srv_master_do_shutdown_tasks())-> srv_sync_log_buffer_in_background()-> log_buffer_sync_in_background()->log_write_up_to()->... .
146 /** Wrapper for recv_recovery_from_checkpoint_start_func(). 147 Recovers from a checkpoint. When this function returns, the database is able 148 to start processing of new user transactions, but the function 149 recv_recovery_from_checkpoint_finish should be called later to complete 150 the recovery and free the resources used in it. 151 @param type in: LOG_CHECKPOINT or LOG_ARCHIVE 152 @param lim in: recover up to this log sequence number if possible 153 @param min in: minimum flushed log sequence number from data files 154 @param max in: maximum flushed log sequence number from data files 155 @return error code or DB_SUCCESS */ 156 # define recv_recovery_from_checkpoint_start(type,lim,min,max) 157 recv_recovery_from_checkpoint_start_func(type,lim,min,max)
|
recv_sys->limit_lsn |
恢复应该执行到的最大的LSN值,这里赋值为LSN_MAX(uint64_t的最大值) |
|
recv_sys->parse_start_lsn |
恢复解析日志阶段所使用的最起始的LSN值,这里等于最后一次执行checkpoint对应的LSN值 |
|
recv_sys->scanned_lsn |
当前扫描到的LSN值 |
|
recv_sys->recovered_lsn |
当前恢复到的LSN值,此值小于等于recv_sys->scanned_lsn |
2908 /*******************************************************//** 2909 Scans log from a buffer and stores new log data to the parsing buffer. Parses 2910 and hashes the log records if new data found. */ 2911 static 2912 void 2913 recv_group_scan_log_recs( 2914 /*=====================*/ 2915 log_group_t* group, /*!< in: log group */ 2916 lsn_t* contiguous_lsn, /*!< in/out: it is known that all log 2917 groups contain contiguous log data up 2918 to this lsn */ 2919 lsn_t* group_scanned_lsn)/*!< out: scanning succeeded up to 2920 this lsn */ 2930 while (!finished) { 2931 end_lsn = start_lsn + RECV_SCAN_SIZE; 2932 2933 log_group_read_log_seg(LOG_RECOVER, log_sys->buf, 2934 group, start_lsn, end_lsn); 2935 2936 finished = recv_scan_log_recs( 2937 (buf_pool_get_n_pages() 2938 - (recv_n_pool_free_frames * srv_buf_pool_instances)) 2939 * UNIV_PAGE_SIZE, 2940 TRUE, log_sys->buf, RECV_SCAN_SIZE, 2941 start_lsn, contiguous_lsn, group_scanned_lsn); 2942 start_lsn = end_lsn; 2943 }
105 /** Wrapper for recv_recover_page_func(). 106 Applies the hashed log records to the page, if the page lsn is less than the 107 lsn of a log record. This can be called when a buffer page has just been 108 read in, or also for a page already in the buffer pool. 109 @param jri in: TRUE if just read in (the i/o handler calls this for 110 a freshly read page) 111 @param block in/out: the buffer block 112 */ 113 # define recv_recover_page(jri, block) recv_recover_page_func(jri, block)
MySQL redo log及recover过程浅析,布布扣,bubuko.com
标签:style blog class code java tar
原文地址:http://www.cnblogs.com/liuhao/p/3714012.html