标签:
6.协议编解码器:
前面说过,协议编解码器是在使用Mina 的时候你最需要关注的对象,因为在网络传输的数据都是二进制数据(byte),而你在程序中面向的是JAVA 对象,这就需要你实现在发送数据时将JAVA 对象编码二进制数据,而接收数据时将二进制数据解码为JAVA 对象(这个可不是JAVA 对象的序列化、反序列化那么简单的事情)。Mina 中的协议编解码器通过过滤器ProtocolCodecFilter 构造,这个过滤器的构造方法需要一个ProtocolCodecFactory,这从前面注册TextLineCodecFactory 的代码就可以看出来。
ProtocolCodecFactory 中有如下两个方法:
public interface ProtocolCodecFactory {
ProtocolEncoder getEncoder(IoSession session) throws Exception;
ProtocolDecoder getDecoder(IoSession session) throws Exception;
}
因此,构建一个ProtocolCodecFactory 需要ProtocolEncoder、ProtocolDecoder 两个实例。你可能要问JAVA 对象和二进制数据之间如何转换呢?这个要依据具体的通信协议,也就是Server 端要和Client 端约定网络传输的数据是什么样的格式,譬如:第一个字节表示数据长度,第二个字节是数据类型,后面的就是真正的数据(有可能是文字、有可能是图片等等),然后你可以依据长度从第三个字节向后读,直到读取到指定第一个字节指定长度的数据。
简单的说,HTTP 协议就是一种浏览器与Web 服务器之间约定好的通信协议,双方按照指定的协议编解码数据。我们再直观一点儿说,前面一直使用的TextLine 编解码器就是在读取网络上传递过来的数据时,只要发现哪个字节里存放的是ASCII 的10、13 字符(/r、/n),就认为之前的字节就是一个字符串(默认使用UTF-8 编码)。以上所说的就是各种协议实际上就是网络七层结构中的应用层协议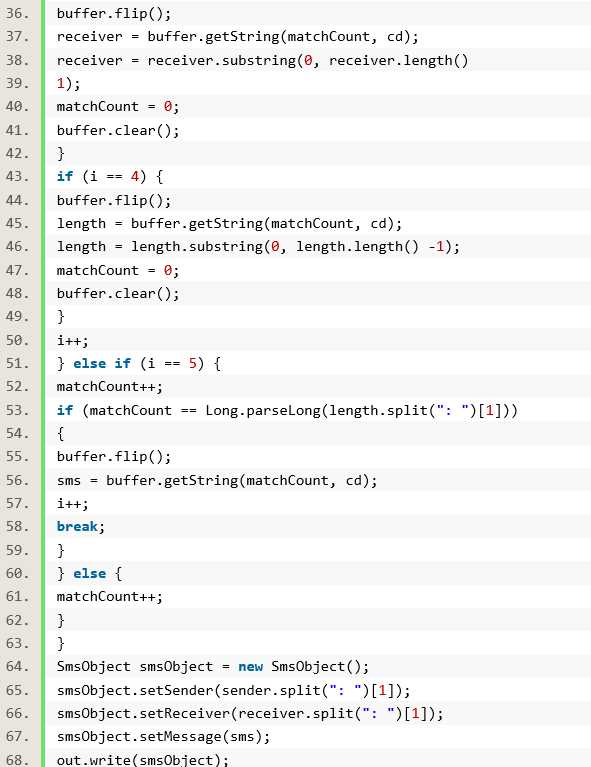
,它位于网络层(IP)、传输层(TCP)之上,Mina 的协议编解码器就是让你实现一套自己的应用层协议栈。
(6-1.)简单的编解码器示例:
下面我们举一个模拟电信运营商短信协议的编解码器实现,假设通信协议如下所示:
M sip:wap.fetion.com.cn SIP-C/2.0
S: 1580101xxxx
R: 1889020xxxx
L: 21
Hello World!
这里的第一行表示状态行,一般表示协议的名字、版本号等,第二行表示短信的发送号码,第三行表示短信接收的号码,第四行表示短信的字节数,最后的内容就是短信的内容。上面的每一行的末尾使用ASC II 的10(/n)作为换行符,因为这是纯文本数据,协议要
求双方使用UTF-8 对字符串编解码。实际上如果你熟悉HTTP 协议,上面的这个精简的短信协议和HTTP 协议的组成是非常像的,第一行是状态行,中间的是消息报头,最后面的是消息正文。在解析这个短信协议之前,你需要知晓TCP 的一个事项,那就是数据的发送没有规模性,所谓的规模性就是作为数据的接收端,不知道到底什么时候数据算是读取完毕,所以应用层协议在制定的时候,必须指定数据读取的截至点。一般来说,有如下三种方式设置数据读取的长度:
(1.)使用分隔符,譬如:TextLine 编解码器。你可以使用/r、/n、NUL 这些ASC II 中的特殊的字符来告诉数据接收端,你只要遇见分隔符,就表示数据读完了,不用在那里傻等着不知道还有没有数据没读完啊?我可不可以开始把已经读取到的字节解码为指定的数据类型了啊?
(2.)定长的字节数,这种方式是使用长度固定的数据发送,一般适用于指令发送,譬如:数据发送端规定发送的数据都是双字节,AA 表示启动、BB 表示关闭等等。
(3.)在数据中的某个位置使用一个长度域,表示数据的长度,这种处理方式最为灵活,上面的短信协议中的那个L 就是短信文字的字节数,其实HTTP 协议的消息报头中的Content-Length 也是表示消息正文的长度,这样数据的接收端就知道我到底读到多长的
字节数就表示不用再读取数据了。相比较解码(字节转为JAVA 对象,也叫做拆包)来说,编码(JAVA 对象转为字节,也叫做打包)就很简单了,你只需要把JAVA 对象转为指定格式的字节流,write()就可以了。下面我们开始对上面的短信协议进行编解码处理。
第一步,协议对象:
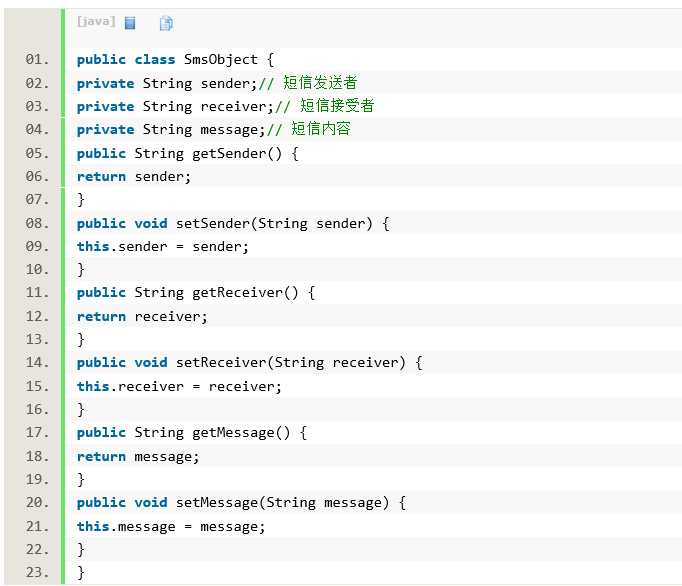
第二步,编码器:
在Mina 中编写编码器可以实现ProtocolEncoder,其中有encode()、dispose()两个方法需要实现。这里的dispose()方法用于在销毁编码器时释放关联的资源,由于这个方法一般我们并不关心,所以通常我们直接继承适配器ProtocolEncoderAdapter。
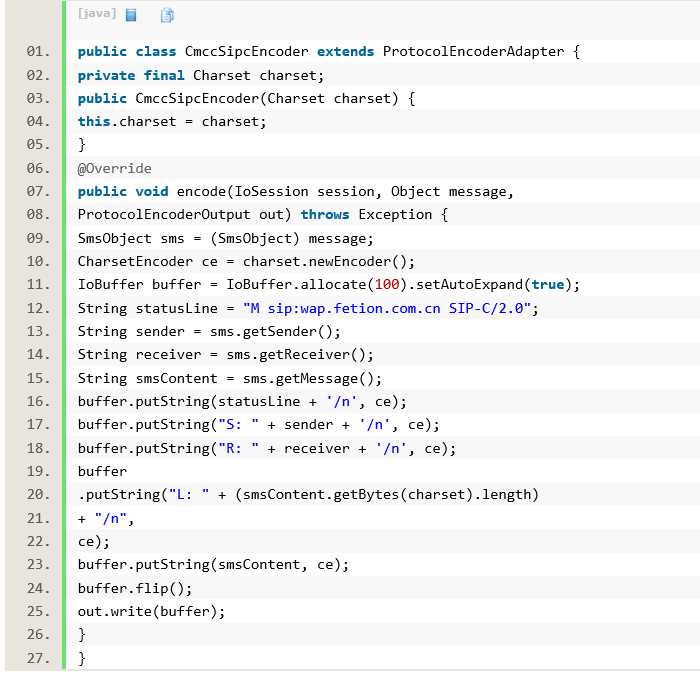
这里我们依据传入的字符集类型对message 对象进行编码,编码的方式就是按照短信协议拼装字符串到IoBuffer 缓冲区,然后调用ProtocolEncoderOutput 的write()方法输出字节流。这里要注意生成短信内容长度时的红色代码,我们使用String 类与Byte[]类型之间的转换方法获得转为字节流后的字节数。
解码器的编写有以下几个步骤:
A. 将 encode()方法中的message 对象强制转换为指定的对象类型;
B. 创建IoBuffer 缓冲区对象,并设置为自动扩展;
C. 将转换后的message 对象中的各个部分按照指定的应用层协议进行组装,并put()到IoBuffer 缓冲区;
D. 当你组装数据完毕之后,调用flip()方法,为输出做好准备,切记在write()方法之前,要调用IoBuffer 的flip()方法,否则缓冲区的position 的后面是没有数据可以用来输出的,你必须调用flip()方法将position 移至0,limit 移至刚才的position。这个flip()方法的含义请参看java.nio.ByteBuffer。
E. 最后调用ProtocolEncoderOutput 的write()方法输出IoBuffer 缓冲区实例。
第三步,解码器:
在Mina 中编写解码器,可以实现ProtocolDecoder 接口,其中有decode()、finishDecode()、dispose()三个方法。这里的finishDecode()方法可以用于处理在IoSession 关闭时剩余的未读取数据,一般这个方法并不会被使用到,除非协议中未定义任何标识数据什么时候截止的约定,譬如:Http 响应的Content-Length 未设定,那么在你认为读取完数据后,关闭TCP连接(IoSession 的关闭)后,就可以调用这个方法处理剩余的数据,当然你也可以忽略调剩余的数据。同样的,一般情况下,我们只需要继承适配器ProtocolDecoderAdapter,关注decode()方法即可。但前面说过解码器相对编码器来说,最麻烦的是数据发送过来的规模,以聊天室为例,一个TCP 连接建立之后,那么隔一段时间就会有聊天内容发送过来,也就是decode()方法会被往复调用,这样处理起来就会非常麻烦。那么Mina 中幸好提供了CumulativeProtocolDecoder类,从名字上可以看出累积性的协议解码器,也就是说只要有数据发送过来,这个类就会去读取数据,然后累积到内部的IoBuffer 缓冲区,但是具体的拆包(把累积到缓冲区的数据解码为JAVA 对象)交由子类的doDecode()方法完成,实际上CumulativeProtocolDecoder就是在decode()反复的调用暴漏给子类实现的doDecode()方法。
具体执行过程如下所示:
A. 你的doDecode()方法返回true 时,CumulativeProtocolDecoder 的decode()方法会首先判断你是否在doDecode()方法中从内部的IoBuffer 缓冲区读取了数据,如果没有,则会抛出非法的状态异常,也就是你的doDecode()方法返回true 就表示你已经消费了本次数据(相当于聊天室中一个完整的消息已经读取完毕),进一步说,也就是此时你必须已经消费过内部的IoBuffer 缓冲区的数据(哪怕是消费了一个字节的数据)。如果验证过通过,那么CumulativeProtocolDecoder 会检查缓冲区内是否还有数据未读取,如果有就继续调用doDecode()方法,没有就停止对doDecode()方法的调用,直到有新的数据被缓冲。
B. 当你的doDecode()方法返回false 时,CumulativeProtocolDecoder 会停止对doDecode()方法的调用,但此时如果本次数据还有未读取完的,就将含有剩余数据的IoBuffer 缓冲区保存到IoSession 中,以便下一次数据到来时可以从IoSession 中提取合并。如果发现本次数据全都读取完毕,则清空IoBuffer 缓冲区。简而言之,当你认为读取到的数据已经够解码了,那么就返回true,否则就返回false。这个CumulativeProtocolDecoder 其实最重要的工作就是帮你完成了数据的累积,因为这个工作是很烦琐的。
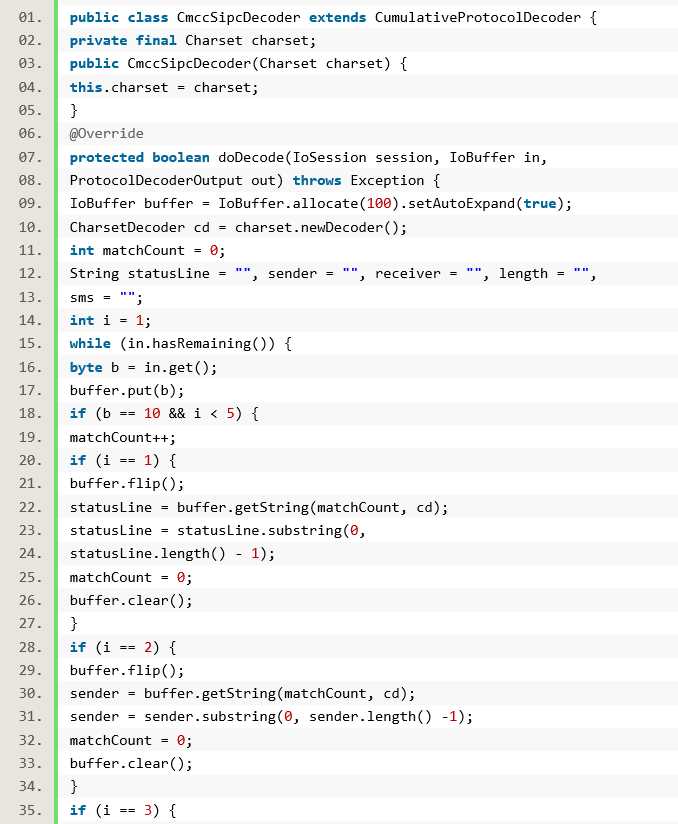
我们的这个短信协议解码器使用/n(ASCII 的10 字符)作为分解点,一个字节一个字节的读取,那么第一次发现/n 的字节位置之前的部分,必然就是短信协议的状态行,依次类推,你就可以解析出来发送者、接受者、短信内容长度。然后我们在解析短信内容时,使用获取到的长度进行读取。全部读取完毕之后, 然后构造SmsObject 短信对象, 使用ProtocolDecoderOutput 的write()方法输出,最后返回false,也就是本次数据全部读取完毕,告知CumulativeProtocolDecoder 在本次数据读取中不需要再调用doDecode()方法了。这里需要注意的是两个状态变量i、matchCount,i 用于记录解析到了短信协议中的哪一行(/n),matchCount 记录在当前行中读取到了哪一个字节。状态变量在解码器中经常被使用,我们这里的情况比较简单,因为我们假定短信发送是在一次数据发送中完成的,所以状态变量的使用也比较简单。假如数据的发送被拆成了多次(譬如:短信协议的短信内容、消息报头被拆成了两次数据发送),那么上面的代码势必就会存在问题,因为当第二次调用doDecode()方法时,状态变量i、matchCount 势必会被重置,也就是原来的状态值并没有被保存。那么我们如何解决状态保存的问题呢?答案就是将状态变量保存在IoSession 中或者是Decoder 实例自身,但推荐使用前者,因为虽然Decoder 是单例的,其中的实例变量保存的状态在Decoder 实例销毁前始终保持,但Mina 并不保证每次调用doDecode()方法时都是同一个线程(这也就是说第一次调用doDecode()是IoProcessor-1 线程,第二次有可能就是IoProcessor-2 线程),这就会产生多线程中的实例变量的可视性(Visibility,具体请参考JAVA 的多线程知识)问题。IoSession中使用一个同步的HashMap 保存对象,所以你不需要担心多线程带来的问题。使用IoSession 保存解码器的状态变量通常的写法如下所示:
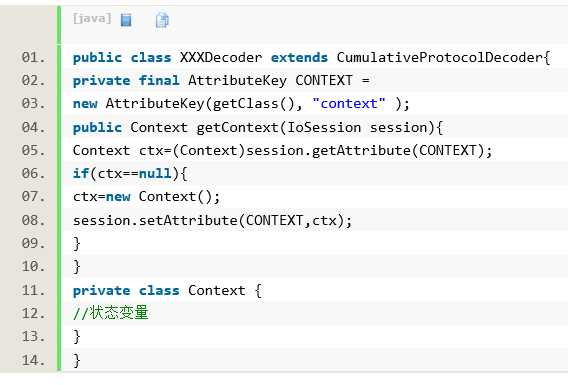
A. 在解码器中定义私有的内部类Context,然后将需要保存的状态变量定义在Context 中存储。
B. 在解码器中定义方法获取这个Context 的实例,这个方法的实现要优先从IoSession 中获取Context。
具体代码示例如下所示:
// 上下文作为保存状态的内部类的名字,意思很明显,就是让状态跟随上下文,在整个调用过程中都可以被保持。
注意这里我们使用了Mina 自带的AttributeKey 类来定义保存在IoSession 中的对象的键值,这样可以有效的防止键值重复。另外,要注意在全部处理完毕之后,状态要复位,譬如:聊天室中的一条消息读取完毕之后,状态变量要变为初始值,以便下次处理时重新使用。
第四步,编解码工厂:

实际上这个工厂类就是包装了编码器、解码器,通过接口中的getEncoder()、getDecoder()方法向ProtocolCodecFilter 过滤器返回编解码器实例,以便在过滤器中对数据进行编解码处理。
第五步,运行示例:
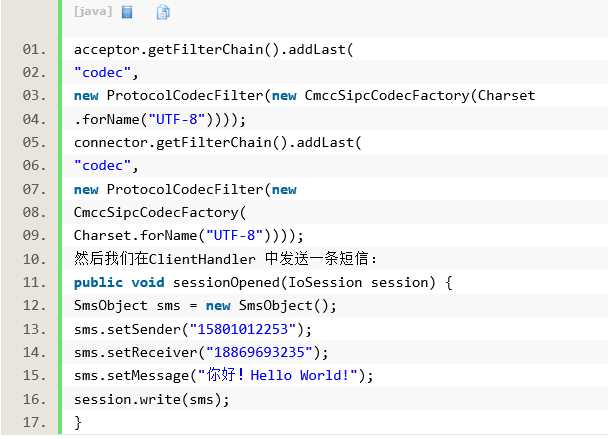
下面我们修改最一开始的示例中的MyServer、MyClient 的代码,如下所示:

标签:
原文地址:http://www.cnblogs.com/chenxqNo01/p/5787438.html