标签:Lucene blog http java 使用 for 2014 art
在前一篇中的倒排索引介绍中, 我们了解到要把一篇文档(或者在电商业务中一个商品相关信息)放入索引系统中, 要对该文档的关键词进行提取分析出来后建立相应的倒排列表. 现在问题来了, 我们怎么从一篇文档中抽出所有以前可能要索引的词. 比如一个显示器的标题是 "三星显示器S22D300NY 21.5寸 LED液晶显示器完美屏 替代S22C150N", 那么用户可能在系统中通过输入"三星显示器"或者"S22D300NY"或者"21.5寸"后, 都能正确返回这个显示器的信息. 这就是所谓的分词, 或者词条化技术.
基于分词在不同的语言中, 所要解决的难点问题是不同的. 拿我们知道的英语和汉语来说. 英语的分词看起来简单, 比如 "i love you! " , 我们完全可以根据空格抽出三个词: i, love, you. 但是也有一些复杂的情况要考虑, 如果 i , me ,my 其实他们表达的意思差不多, 用户希望输入 i 的时候, 相关的文档也可以查询出来. 还有一些单复数, 名词/形容词/副词 的形式转化, 而汉语分词的难道是断词, 因为我们的语言是没有空格的, 一句话所有的字全挤在一起, 如"工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作" , 如果让计算机分词的话, 通过怎么样的算法能抽取出满足我们需求的词项呢? 如果分析出一些敏感词(你懂的)肯定不是我们想要的. 所以针对不同的语言, 因为语言自身的特性, 导致它们的难点完全不同(有的文字还是从右往左写的). 我们也只重点关注英文和汉语的问题.
在英语中, 对词的不同形态进行统一, 叫做词干还原(stemmin), 实现这有很多算法, 被证实效率较高, 使用较广的是Porter算法. 可以在lucene中找到相关的java实现代码: org.apache.lucene.analysis.en.PorterStemmer.
汉语的分词其实也是比较复杂的, 也有很多不同的方法, google下"中文分词"会有很多介绍. lucene中也有相关的实现: analyzers-smartcn. 这里我们以: jieba分词 来介绍下中文分词的思路. 可以分为三步: 准备词典; 抽取所有组成词语的组合; 找出最优(最好)的一组.
既然中文语法是没有空格加以断词, 那么我们肯定事先把可能的所有词语都准备好. jieba中通过Trie树结构保存所有的词语, 这样可以在分析句子时高速扫描出所有包含的词语.

用夏变夷 3 nz 用天因地 3 l 用头巾包 3 l 用奴用 3 n 用字 29 n 用字不当 3 l 用学 10 n 用家 3 n 用尽 110 v 用尽心机 3 l 用尽方法 3 l 用工 117 n 用工夫 5 n 用布 241 v 用度 49 n 用当其用 3 l
每一个词语载入Trie树的逻辑如下:
def load(word):
p = trie
for c in word:
if c not in p:
p[c] ={}
p = p[c]
有了Trie树, 解析一个句子中所有的词组合是很容易的, 在jieba分词中用一个DAG(有向图)来表达这个结构. 我们举例说明下, 现在有一个这样的句子: "买水果然后来世博园". 通过扫描前面的Trie树, 可以得到如下词语组合:
买 / 水果 / 果然 / 然后 / 后来 / 来世 / 世博 / 世博园 / 博园
接着上面的例子, 我们得到"买 / 水果 / 果然 / 然后 / 后来 / 来世 / 世博 / 世博园 / 博园"这些词, 但是显然这只是简单的把所有可能的词全部罗列出来, 但是根据这个句子的语境, 其实我们更想得到这样的组合:
买 / 水果 / 然后 / 来 / 世博园
在jieba分词, 使用的原理是: 通过每个词的出现概率, 来计算基于这个句子的所有切分组合中总概率最大的一个组合, 这是典型的动态规划计算模型. 用个图来说明下这个模型:
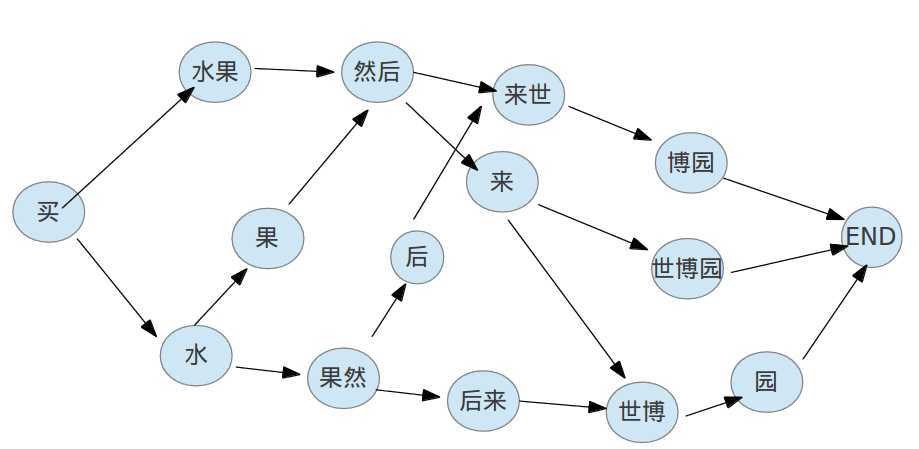
我们通过动态规划算法计算一条最大概率的路径即是最优组合:
def calc(sentence,DAG,idx,route):
N = len(sentence)
route[N] = (0.0,‘‘)
for idx in xrange(N-1,-1,-1):
candidates = [ ( FREQ.get(sentence[idx:x+1],min_freq) + route[x+1][0],x ) for x in DAG[idx] ]
route[idx] = max(candidates)
这是jieba分词中动态规划的逻辑代码, 也算很简洁了(python写的代码果然很牛). 到止我们已经完成了分析的基本功能.
------------------------EOF
标签:Lucene blog http java 使用 for 2014 art
原文地址:http://www.cnblogs.com/jcli/p/3902788.html