标签:
在深度学习中,当数据量不够大时候,常常采用下面4中方法:
不同的任务背景下, 我们可以通过图像的几何变换, 使用以下一种或多种组合数据增强变换来增加输入数据的量. 这里具体的方法都来自数字图像处理的内容, 相关的知识点介绍, 网上都有, 就不一一介绍了.
[p1,p2,p3][α1λ1,α2λ2,α3λ3]T
其中:αi是满足均值为0,方差为0.1的随机变量.
作为实现部分, 这里介绍一下在python 环境下, 利用已有的开源代码库Keras作为实践:
1 # -*- coding: utf-8 -*- 2 __author__ = ‘Administrator‘ 3 4 # import packages 5 from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img 6 7 datagen = ImageDataGenerator( 8 rotation_range=0.2, 9 width_shift_range=0.2, 10 height_shift_range=0.2, 11 shear_range=0.2, 12 zoom_range=0.2, 13 horizontal_flip=True, 14 fill_mode=‘nearest‘) 15 16 img = load_img(‘C:\Users\Administrator\Desktop\dataA\lena.jpg‘) # this is a PIL image, please replace to your own file path 17 x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150) 18 x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150) 19 20 # the .flow() command below generates batches of randomly transformed images 21 # and saves the results to the `preview/` directory 22 23 i = 0 24 for batch in datagen.flow(x, 25 batch_size=1, 26 save_to_dir=‘C:\Users\Administrator\Desktop\dataA\pre‘,#生成后的图像保存路径 27 save_prefix=‘lena‘, 28 save_format=‘jpg‘): 29 i += 1 30 if i > 20: 31 break # otherwise the generator would loop indefinitely
主要函数:ImageDataGenerator 实现了大多数上文中提到的图像几何变换方法.
效果如下图所示:
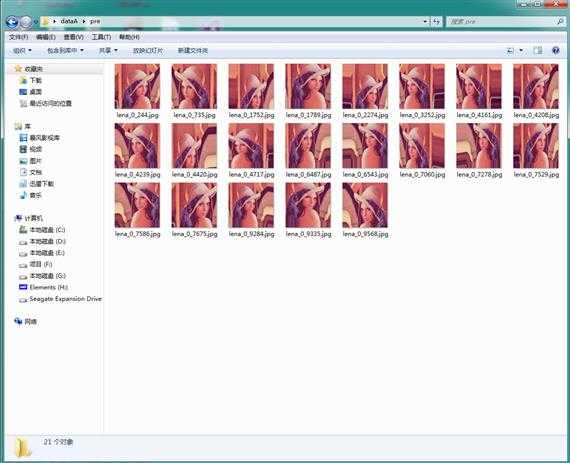
转载于:http://blog.csdn.net/mduanfire/article/details/51674098
深度学习中的Data Augmentation方法(转)基于keras
标签:
原文地址:http://www.cnblogs.com/love6tao/p/5841648.html