标签:
package main.scala
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object graph_test {
// define hadoop_home directory
System.setProperty("hadoop.home.dir","E:/zhuangji/winutil/")
def main(args:Array[String]):Unit={
val conf=new SparkConf().setMaster("local[2]").setAppName("graph_test")
val sc=new SparkContext(conf)
// VertexRDD & EdgeRDD to build graph
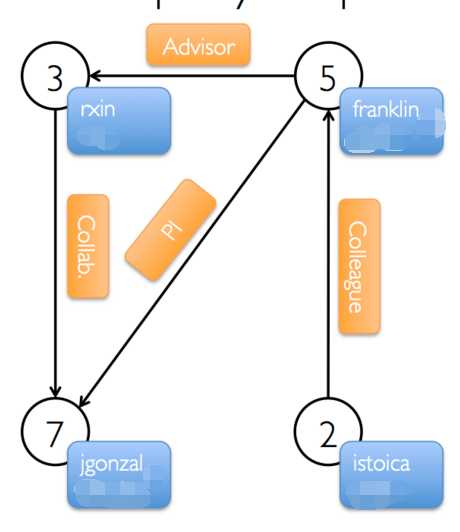
val users:RDD[(VertexId,(String,String))]=
sc.parallelize(Array((3L,("rxin","student")),(7L,("jgonzal","postdoc")),
(5L,("franklin","prof")),(2L,("istoica","prof"))))
val relationships:RDD[Edge[String]]=
sc.parallelize(Array(Edge(3L,7L,"collab"),Edge(5L,3L,"advisor"),
Edge(2L,5L,"colleague"),Edge(5L,7L,"pi")))
val defaultUser=("John Doe","Missing")
val graph=Graph(users,relationships,defaultUser)
// graph.vertices & graph.edges to query graph
println(graph.vertices.filter{case (id,(name,pos))=>pos=="prof"}.count)
println(graph.edges.filter{case Edge(s,d,r)=>s<d}.count) // 两者
println(graph.edges.filter(e=>e.srcId<e.dstId).count) // 等价
// 三元组视图 graph.triplets could also query a graph
val facts:RDD[String]=
graph.triplets.map(triplet=>
triplet.srcAttr._1 + " is the " + triplet.attr + " of " + triplet.dstAttr._1)
facts.collect.foreach(println(_))
}
}
标签:
原文地址:http://www.cnblogs.com/skyEva/p/5900183.html