标签:

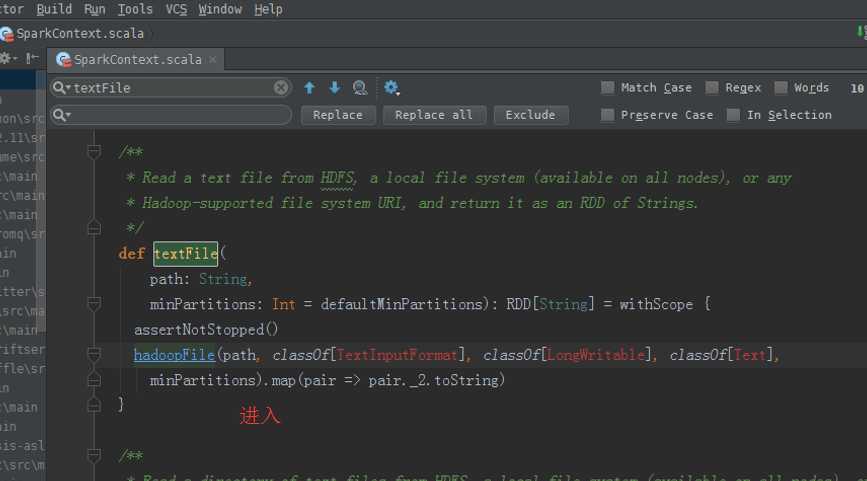
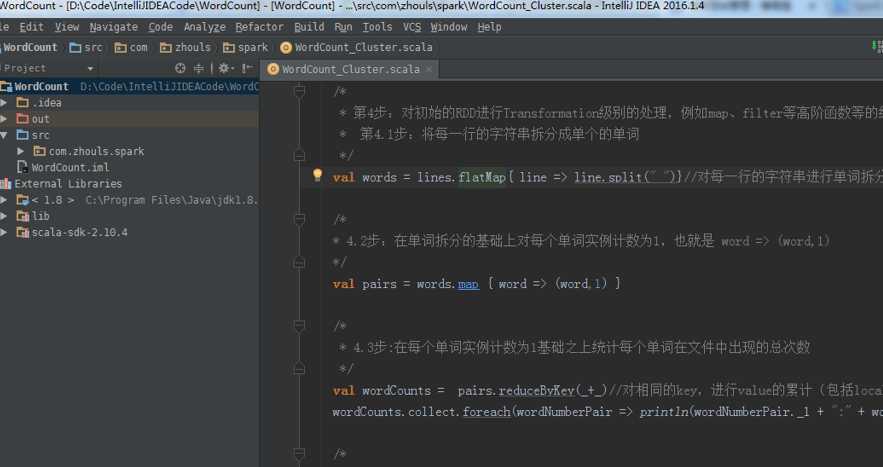
sc.textFile("README.md").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_ + _).collect
sc.textFile("README.md").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => a + b).collect

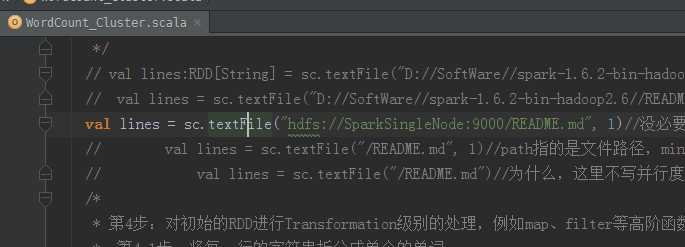


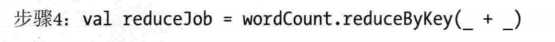

总结:
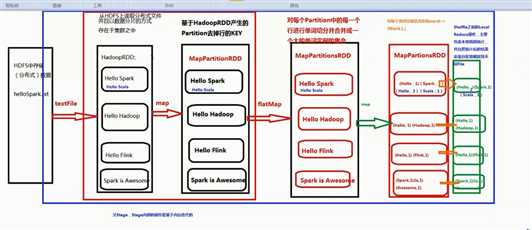
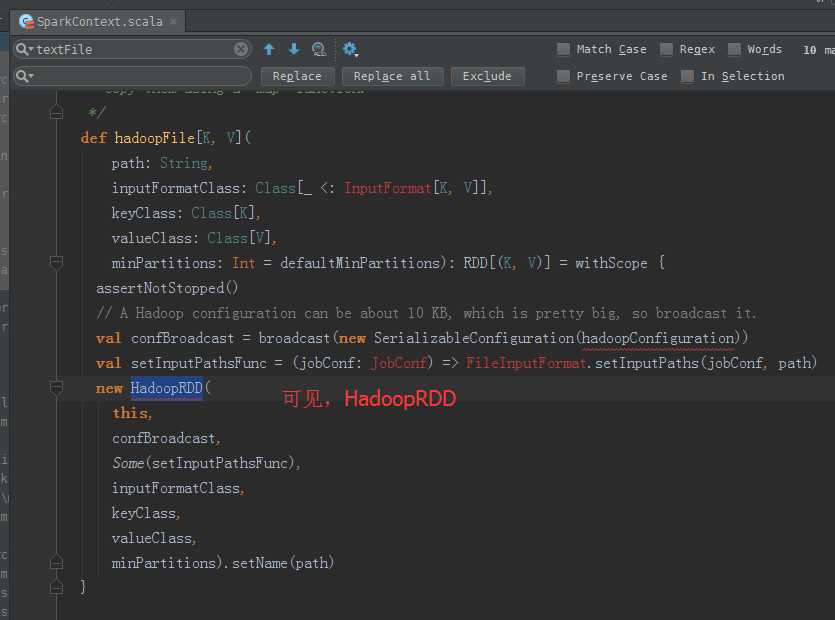
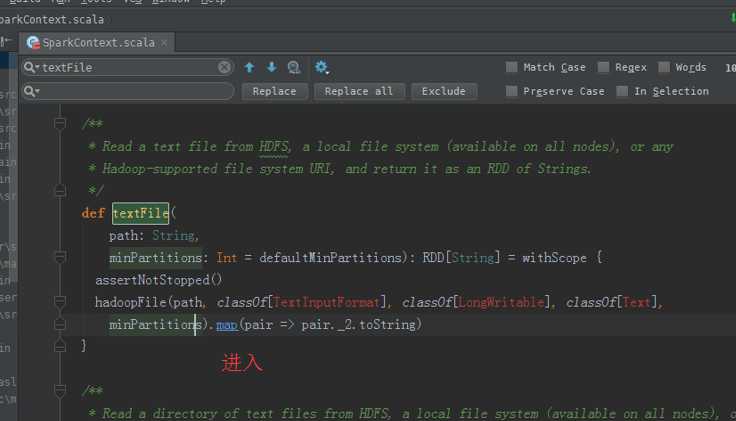
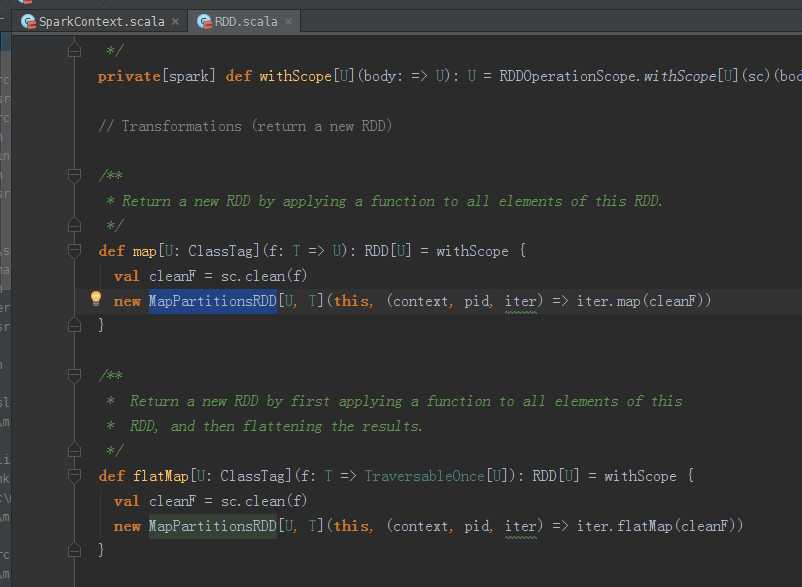
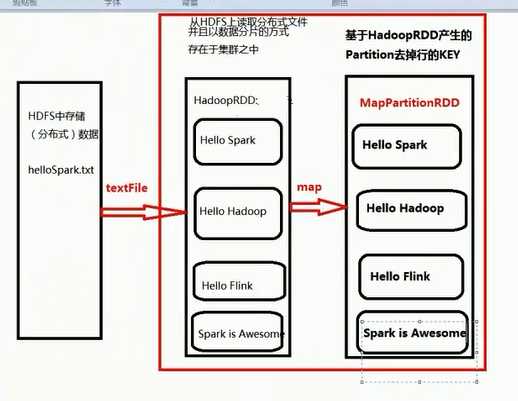
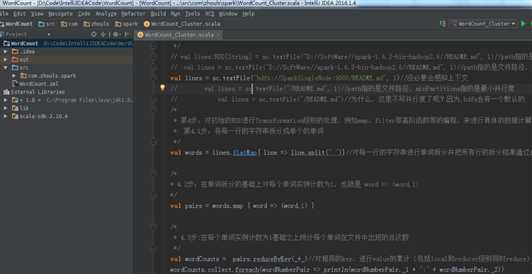
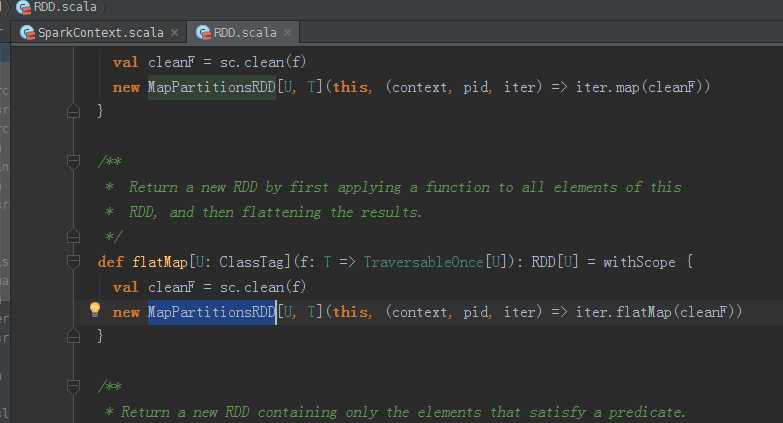
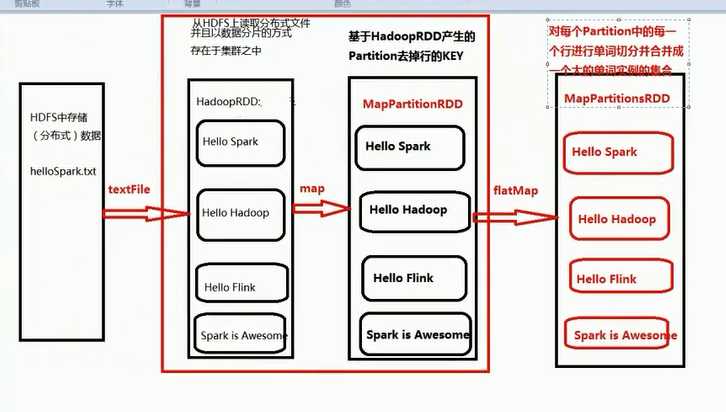
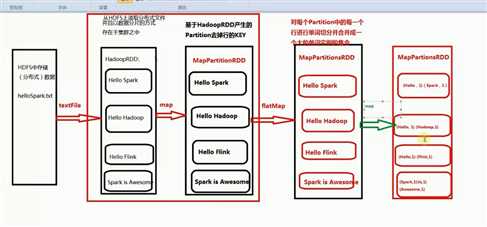
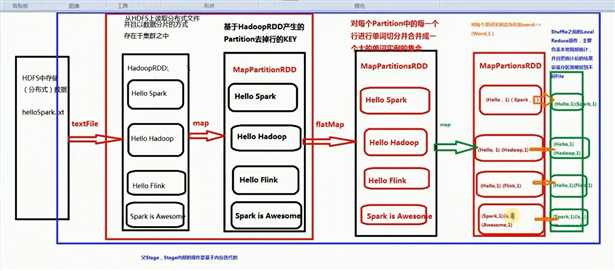
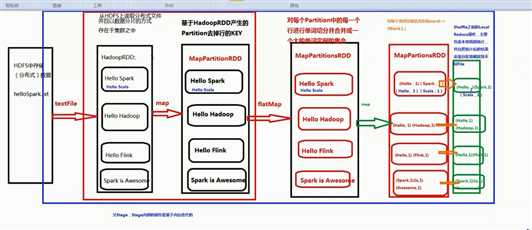
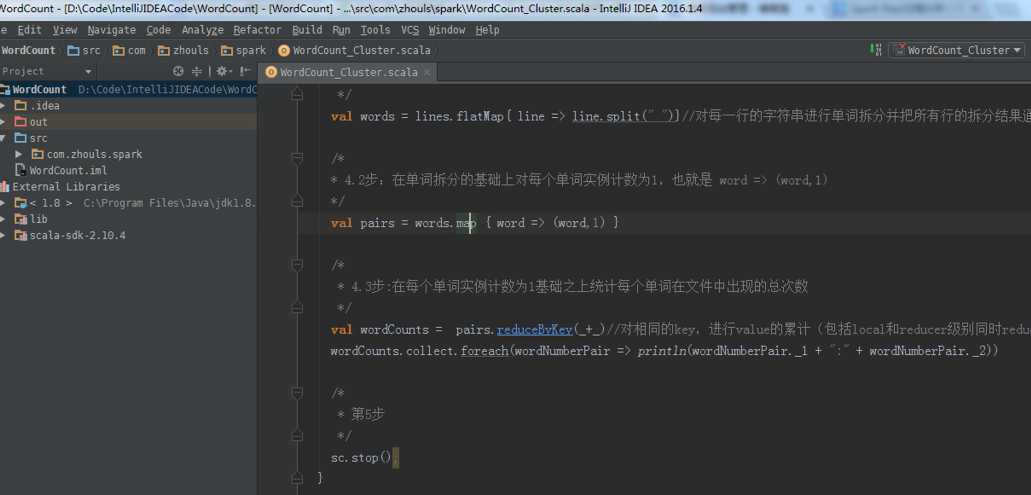
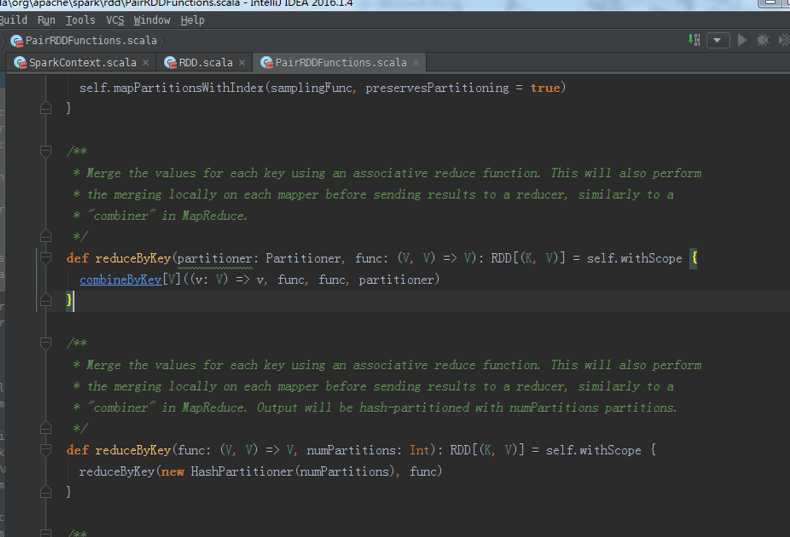
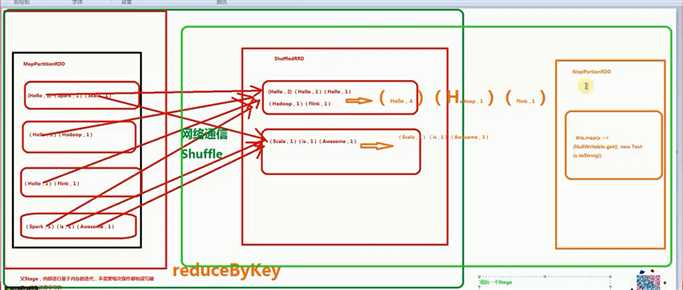
第一个stage :
HadoopRDD -> MapPartitionRDD -> MapPartitionsRDD -> MapPartitionsRDD -> MapPartitionsRDD
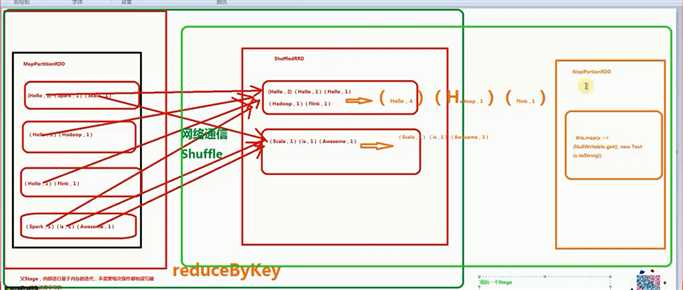
第二个stage :
Stage shuffledRDD -> MapPartitionsRDD










标签:
原文地址:http://www.cnblogs.com/zlslch/p/5906198.html