标签:
回顾一下soft margin SVM的知识:

然而从另一个角度来看,分为真的有犯错和没有犯错:
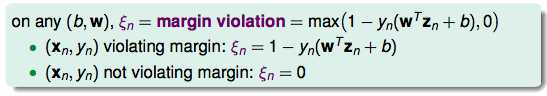
在没有犯错的时候,ξn=0就好了。于是ξn就可以写成一个求max的过程。根据这个思路,我们有了SVM的新形式:
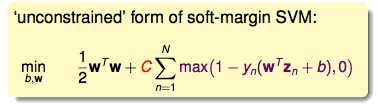
这样一来,ξn就不再是一个独立的变量,它变成了一个由b和w决定的变量,这样的话,式子又被简化了。
简化后的式子和L2的正则差不多:
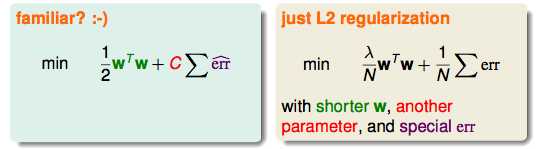
SVM和正则化有很多相似的点:

这些联系可以帮助我们以后换一种视角看待SVM。
下面从错误衡量的视角看LR和SVM:
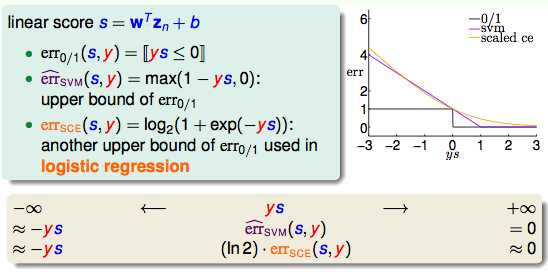
由此可以看出SVM≈L2的LR。
那么再比较一下他们在二分类问题时的优缺点:
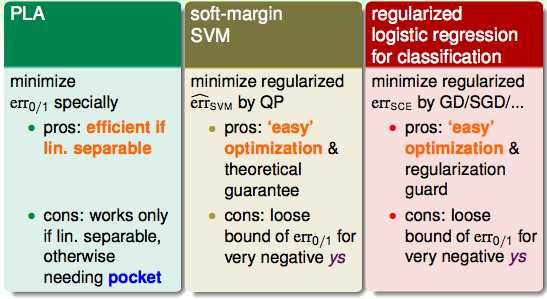
LR做二元分类比较好,因为它有个几率的概念;SVM只有固定的解,但是它有kernel这个好武器。

先跑个SVM,得到b和w;
再做一些放缩和平移的处理。
得到新的问题:
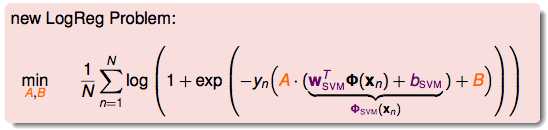
具体的步骤:

kernel的本质其实就是w可以表示成输入数据的线性组合。那么如果用这样的思路去看L2正则:

上图证明了L2正则也可以被kernel的(kernelized)。接下来就可以继续证明LR也可以被kernel:


总结:

机器学习技法(5)--Kernel Logistic Regression
标签:
原文地址:http://www.cnblogs.com/cyoutetsu/p/5922210.html