标签:
1.词法分析程序的功能
从左至右地对源程序进行扫描,按照语言的词法规则识别各类单词,并产生相应单词的属性字
2.符号与种别码对照表
| 单词符号 | 种别码 | 单词符号 | 种别码 |
| begin | 1 | : | 17 |
| if | 2 | := | 18 |
| then | 3 | > | 20 |
| while | 4 | <> | 21 |
| do | 5 | <= | 22 |
| end | 6 | < | 23 |
| letter(letter|digit)* | 10 | >= | 24 |
| digit digit* | 11 | = | 25 |
| * | 13 | ; | 26 |
| / | 14 | ( | 27 |
| + | 15 | ) | 28 |
| - | 16 | # | 0 |
3.用文法描述词法规则
A→aa|Aaa 以aa开头,每次循环增加aa
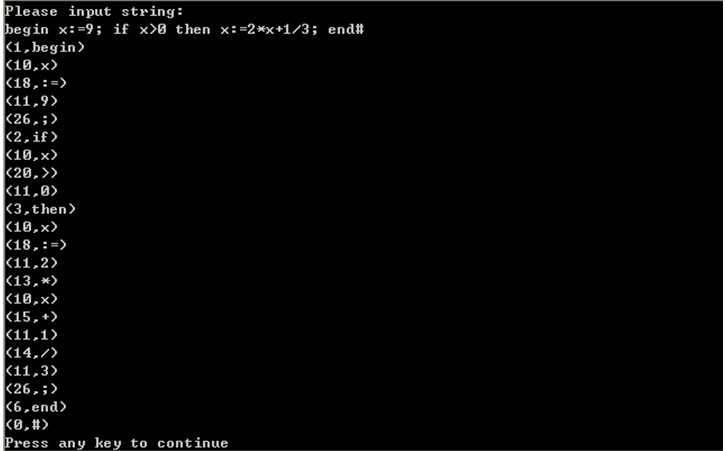
4.已完成代码及运行结果截图
#include<stdio.h>
#include<string.h>
#include<iostream.h>
char prog[80],token[8];
char ch;
int syn,p,m=0,n,row,sum=0;
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner()
{
for(n=0;n<8;n++) token[n]=NULL;
ch=prog[p++];
while(ch==‘ ‘)
{
ch=prog[p];
p++;
}
if((ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))
{
m=0;
while((ch>=‘0‘&&ch<=‘9‘)||(ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))
{
token[m++]=ch;
ch=prog[p++];
}
token[m++]=‘\0‘;
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>=‘0‘&&ch<=‘9‘))
{
{
sum=0;
while((ch>=‘0‘&&ch<=‘9‘))
{
sum=sum*10+ch-‘0‘;
ch=prog[p++];
}
}
p--;
syn=11;
if(sum>32767)
syn=-1;
}
else switch(ch)
{
case‘<‘:m=0;token[m++]=ch;
ch=prog[p++];
if(ch==‘>‘)
{
syn=21;
token[m++]=ch;
}
else if(ch==‘=‘)
{
syn=22;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case‘>‘:m=0;token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=24;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case‘:‘:m=0;token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
p--;
}
break;
case‘*‘:syn=13;token[0]=ch;break;
case‘/‘:syn=14;token[0]=ch;break;
case‘+‘:syn=15;token[0]=ch;break;
case‘-‘:syn=16;token[0]=ch;break;
case‘=‘:syn=25;token[0]=ch;break;
case‘;‘:syn=26;token[0]=ch;break;
case‘(‘:syn=27;token[0]=ch;break;
case‘)‘:syn=28;token[0]=ch;break;
case‘#‘:syn=0;token[0]=ch;break;
case‘\n‘:syn=-2;break;
default: syn=-1;break;
}
}
int main()
{
p=0;
row=1;
cout<<"please input string:"<<endl;
do
{
cin.get(ch);
prog[p++]=ch;
}
while(ch!=‘#‘);
p=0;
do
{
scaner();
switch(syn)
{
case 11: cout<<"("<<syn<<","<<sum<<")"<<endl; break;
case -1: cout<<"Error in row "<<row<<"!"<<endl; break;
case -2: row=row++;break;
default: cout<<"("<<syn<<","<<token<<")"<<endl;break;
}
}
while (syn!=0);
}
标签:
原文地址:http://www.cnblogs.com/wha000/p/5924740.html