标签:
本博文的主要内容是:
1. Hive本质解析
2. Hive安装实战
3. 使用Hive操作搜索引擎数据实战
SparkSQL前身是Shark,Shark强烈依赖于Hive。Spark原来没有做SQL多维度数据查询工具,后来开发了Shark,Shark依赖于Hive的解释引擎,部分在Spark中运行,还有一部分在Hadoop中运行。所以讲SparkSQL必须讲Hive。
1. Hive本质解析
1. Hive是分布式数据仓库,同时又是查询引擎,所以SparkSQL取代的只是Hive的查询引擎,在企业实际生产环境下,Hive+SparkSQL是目前最为经典的数据分析组合。
2. Hive本身就是一个简单单机版本的软件,主要负责:
a) 把HQL翻译成Mapper(s)-Reducer-Mapper(s)的代码,并且可能产生很多MapReduce的Job。
b) 把生成的MapReduce代码及相关资源打包成jar并发布到Hadoop集群中运行(这一切都是自动的)
3.Hive本身的架构如下所示:
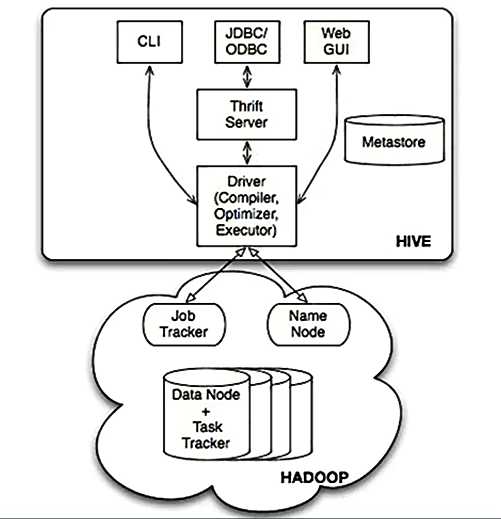
可以通过CLI(命令终端)、JDBC/ODBC、Web GUI访问Hive。
JavaEE或.net程序可以通过Hive处理,再把处理的结果展示给用户。
也可以直接通过Web页面操作Hive。
※ Hive本身只是一个单机版本的的软件,怎么访问HDFS的呢?
=> 在Hive用Table的方式插入数据、检索数据等,这就需要知道数据放在HDFS的什么地方以及什么地方属于什么数据,Metastore就是保存这些元数据信息的。Hive通过访问元数据信息再去访问HDFS上的数据。
可以看出HDFS不是一个真实的文件系统,是虚拟的,是逻辑上的,HDFS只是一套软件而已,它是管理不同机器上的数据的,所以需要NameNode去管理元数据。DataNode去管理数据。
Hive通过Metastore和NameNode打交道。
2、Hive安装和配置实战
由于,我这里,Spark的版本是1.5.2。
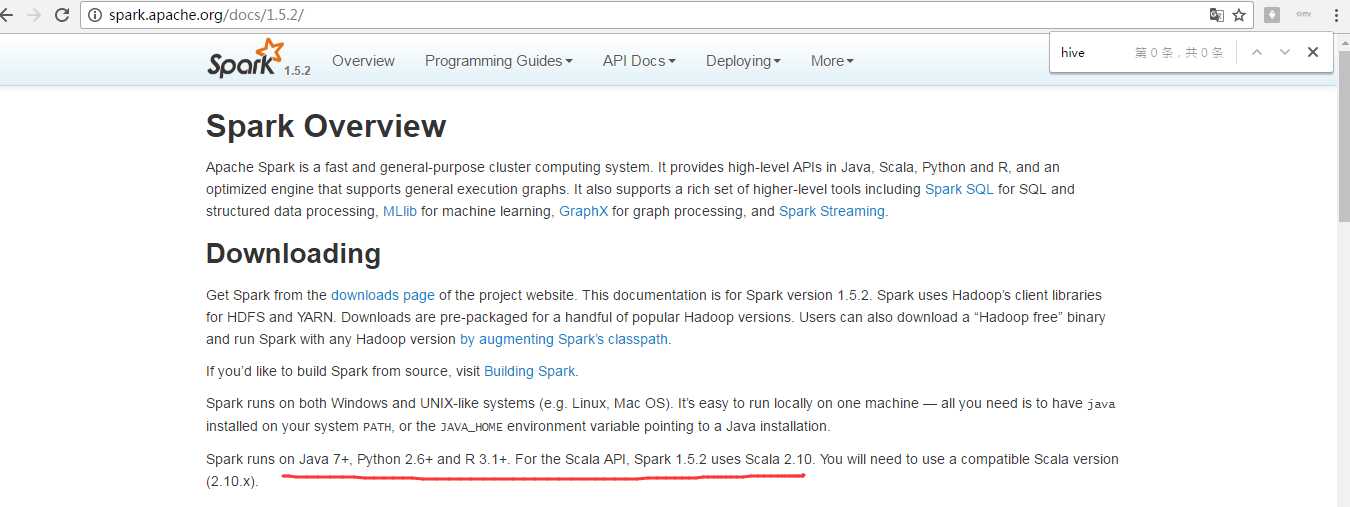
Spark1.5.2中SparkSQL可以指定具体的Hive的版本。
1. 从apache官网下载hive-1.2.1
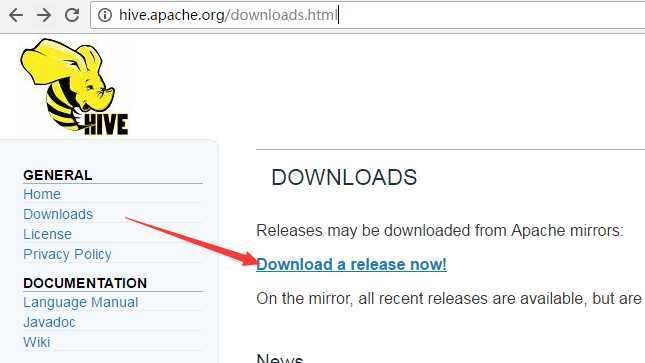
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/

2、apache-hive-1.2.1-bin.tar.gz的上传
3、现在,新建/usr/loca/下的hive目录
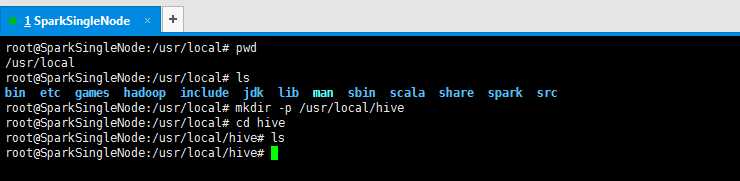
root@SparkSingleNode:/usr/local# pwd
/usr/local
root@SparkSingleNode:/usr/local# ls
bin etc games hadoop include jdk lib man sbin scala share spark src
root@SparkSingleNode:/usr/local# mkdir -p /usr/local/hive
root@SparkSingleNode:/usr/local# cd hive
root@SparkSingleNode:/usr/local/hive# ls
root@SparkSingleNode:/usr/local/hive#
4、将下载的hive文件移到刚刚创建的/usr/local/hive下

root@SparkSingleNode:/usr/local/hive# ls
root@SparkSingleNode:/usr/local/hive# sudo cp /home/spark/Downloads/Spark_Cluster_Software/apache-hive-1.2.1-bin.tar.gz /usr/local/hive/
root@SparkSingleNode:/usr/local/hive# ls
apache-hive-1.2.1-bin.tar.gz
root@SparkSingleNode:/usr/local/hive#
最好用cp,不要轻易要mv
5、解压hive文件

root@SparkSingleNode:/usr/local/hive# ls
apache-hive-1.2.1-bin.tar.gz
root@SparkSingleNode:/usr/local/hive# tar -zxvf apache-hive-1.2.1-bin.tar.gz
6、删除解压包,留下解压完成的文件目录,并修改权限(这是最重要的!!!),其中,还重命名
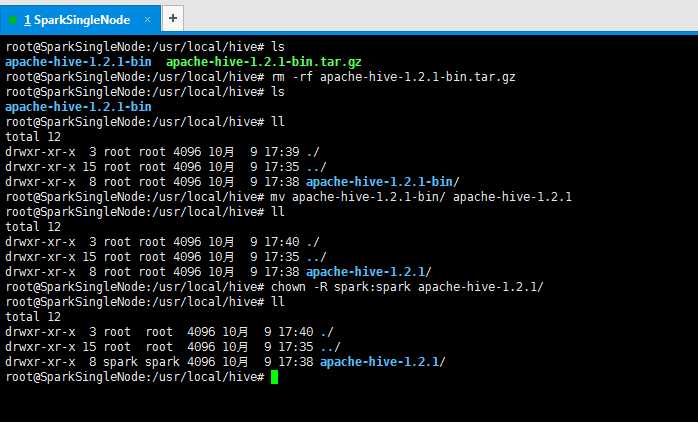
root@SparkSingleNode:/usr/local/hive# ls
apache-hive-1.2.1-bin apache-hive-1.2.1-bin.tar.gz
root@SparkSingleNode:/usr/local/hive# rm -rf apache-hive-1.2.1-bin.tar.gz
root@SparkSingleNode:/usr/local/hive# ls
apache-hive-1.2.1-bin
root@SparkSingleNode:/usr/local/hive# ll
total 12
drwxr-xr-x 3 root root 4096 10月 9 17:39 ./
drwxr-xr-x 15 root root 4096 10月 9 17:35 ../
drwxr-xr-x 8 root root 4096 10月 9 17:38 apache-hive-1.2.1-bin/
root@SparkSingleNode:/usr/local/hive# mv apache-hive-1.2.1-bin/ apache-hive-1.2.1
root@SparkSingleNode:/usr/local/hive# ll
total 12
drwxr-xr-x 3 root root 4096 10月 9 17:40 ./
drwxr-xr-x 15 root root 4096 10月 9 17:35 ../
drwxr-xr-x 8 root root 4096 10月 9 17:38 apache-hive-1.2.1/
root@SparkSingleNode:/usr/local/hive# chown -R spark:spark apache-hive-1.2.1/
root@SparkSingleNode:/usr/local/hive# ll
total 12
drwxr-xr-x 3 root root 4096 10月 9 17:40 ./
drwxr-xr-x 15 root root 4096 10月 9 17:35 ../
drwxr-xr-x 8 spark spark 4096 10月 9 17:38 apache-hive-1.2.1/
root@SparkSingleNode:/usr/local/hive#
7、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile
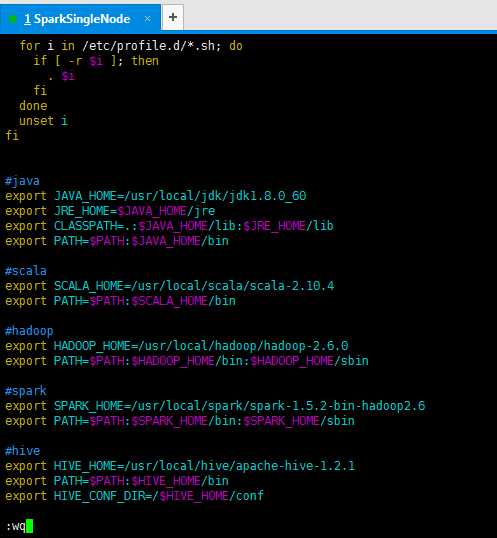
#hive
export HIVE_HOME=/usr/local/hive/apache-hive-1.2.1
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_CONF_DIR=/$HIVE_HOME/conf

root@SparkSingleNode:/usr/local/hive# vim /etc/profile
root@SparkSingleNode:/usr/local/hive# source /etc/profile
继续...
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5943189.html