标签:
---恢复内容开始---
实验一、词法分析实验
专业:商软二班 姓名:黄思慧 学号:201506110189
一、 实验目的
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言进行扫描过程中将其分解为各类单词的词法分析方法。
二、 实验内容和要求
内容:
1.选择高级语言(C语言),编制它的词法分析程序。
要求:
1. 输出:二元组(种别,单词符号本身)
三、 实验方法、步骤及结果测试
可执行程序名:词法分析2.exe
主要总体设计问题。
(包括存储结构,主要算法,关键函数的实现等)
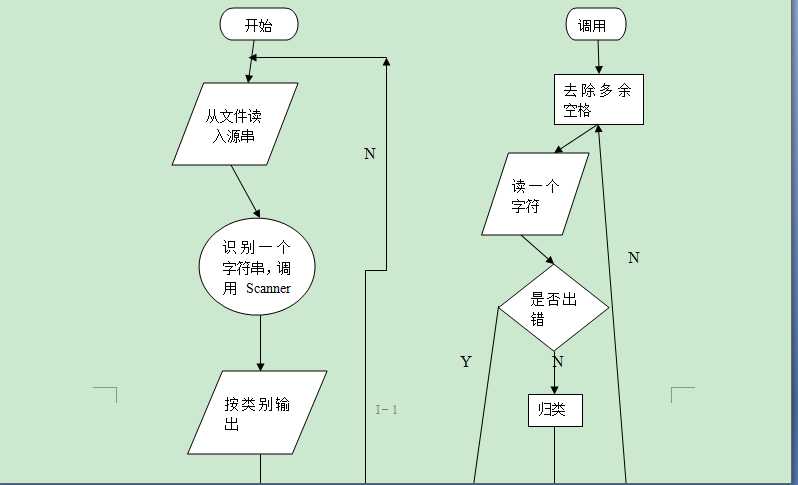
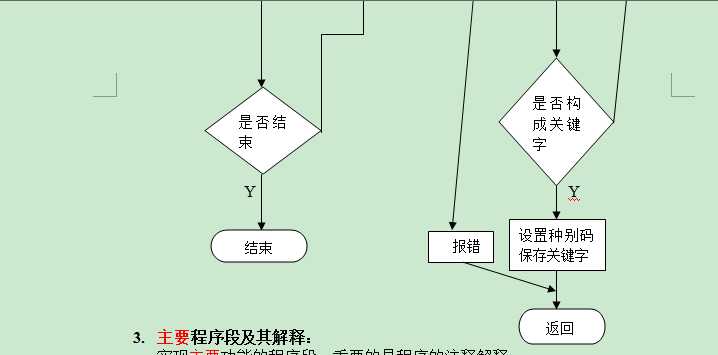
实现主要功能的程序段,重要的是程序的注释解释。
#include <stdio.h> #include <string.h> #include<stdlib.h> char prog[80],token[8],ch; int syn,p,m,n,sum; char *rwtab[6]={"begin","if","then","while","do","end"}; void scaner(); void main() { p=0; printf("\n please input a string(end with‘#‘):\n"); do{ scanf("%c",&ch); prog[p++]=ch; }while(ch!=‘#‘); p=0; do{ scaner(); switch(syn) { case 11: printf("( %-10d%5d )\n",sum,syn); break; case -1: printf("you have input a wrong string\n"); getchar(); exit(0); default: printf("( %-10s%5d )\n",token,syn); break; } }while(syn!=0); getchar(); } void scaner() { sum=0; for(m=0;m<8;m++) token[m++]=NULL; ch=prog[p++]; m=0; while((ch==‘ ‘)||(ch==‘\n‘)) //如果字符是空格或者回车,跳过 ch=prog[p++]; if(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))) //可能是标示符或者变量名或数字 { while(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))||((ch>=‘0‘)&&(ch<=‘9‘))) //找到一个变量名或者关键字,直到遇到空格为止 { token[m++]=ch; ch=prog[p++]; } p--; syn=10; for(n=0;n<6;n++) if(strcmp(token,rwtab[n])==0) { syn=n+1; break; } } else if((ch>=‘0‘)&&(ch<=‘9‘)) { while((ch>=‘0‘)&&(ch<=‘9‘)) { sum=sum*10+ch-‘0‘; ch=prog[p++]; } p--; syn=11; } else { switch(ch) { case ‘<‘:token[m++]=ch; ch=prog[p++]; if(ch==‘=‘) { syn=22; token[m++]=ch; } else { syn=20; p--; } break; case ‘>‘:token[m++]=ch; ch=prog[p++]; if(ch==‘=‘) { syn=24; token[m++]=ch; } else { syn=23; p--; } break; case ‘+‘:token[m++]=ch; ch=prog[p++]; if(ch==‘+‘) { syn=17; token[m++]=ch; } else { syn=13; p--; } break; case ‘-‘: token[m++]=ch; ch=prog[p++]; if(ch==‘-‘) { syn=29; token[m++]=ch; } else { syn=14; p--; } break; case ‘!‘: ch=prog[p++]; if(ch==‘=‘) { syn=21; token[m++]=ch; } else { syn=31; p--; } break; case ‘=‘: token[m++]=ch; ch=prog[p++]; if(ch==‘=‘) { syn=25; token[m++]=ch; } else { syn=18; p--; } break; case ‘*‘: syn=15; token[m++]=ch; break; case ‘/‘: syn=16; token[m++]=ch; break; case ‘(‘: syn=27; token[m++]=ch; break; case ‘)‘: syn=28; token[m++]=ch; break; case ‘{‘: syn=5; token[m++]=ch; break; case ‘}‘: syn=6; token[m++]=ch; break; case ‘;‘: syn=26; token[m++]=ch; break; case ‘\"‘: syn=30; token[m++]=ch; break; case ‘#‘: syn=0; token[m++]=ch; break; case ‘:‘: syn=17; token[m++]=ch; break; default: syn=-1; break; } } token[m++]=‘\0‘; }
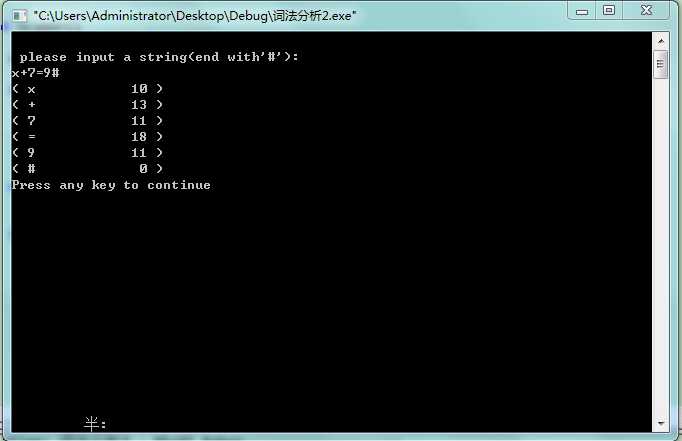
一般必须配运行结果截图,结果是否符合预期及其分析。
(截图需根据实际,截取有代表性的测试例子)
四、 实验总结
心得体会,实验过程的难点问题及其解决的方法。
此次实验对于我来说挺难的,我通过上网摸索以及跟同学讨论渐渐的了解了如何设计、编制并调试词法分析程序,加深对词法分析原理的理解。
---恢复内容结束---
标签:
原文地址:http://www.cnblogs.com/ashh/p/5961992.html