标签:缺陷 roc 拓扑 统计信息 input hunk 消息 its 空间
转自:http://www.cnblogs.com/tgzhu/p/5788634.html
在配置hbase集群将 hdfs 挂接到其它镜像盘时,有不少困惑的地方,结合以前的资料再次学习; 大数据底层技术的三大基石起源于Google在2006年之前的三篇论文GFS、Map-Reduce、 Bigtable,其中GFS、Map-Reduce技术直接支持了Apache Hadoop项目的诞生,Bigtable催生了NoSQL这个崭新的数据库领域,由于map-Reduce处理框架高延时的缺陷, Google在2009年后推出的Dremel促使了实时计算系统的兴起,以此引发大数据第二波技术浪潮,一些大数据公司纷纷推出自己的大数据查询分析产 品,如:Cloudera开源了大数据查询分析引擎Impala、Hortonworks开源了 Stinger、Fackbook开源了Presto、UC Berkeley AMPLAB实验室开发了Spark计算框架,所有这些技术的数据来源均基于hdsf, 对于 hdsf 最基本的不外乎就是其读写操作
目录:
HDFS名词解释:
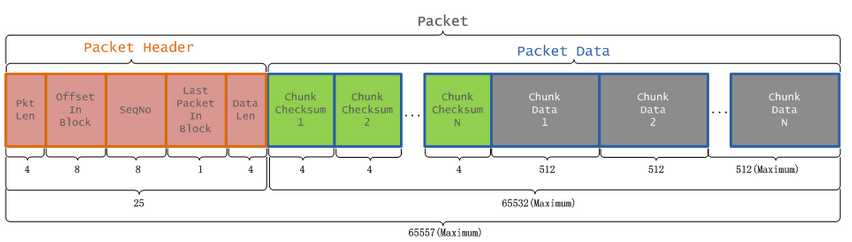
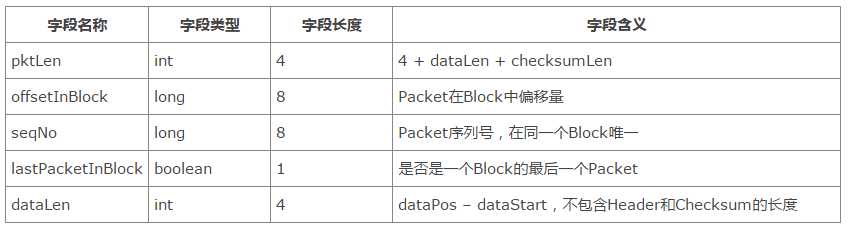
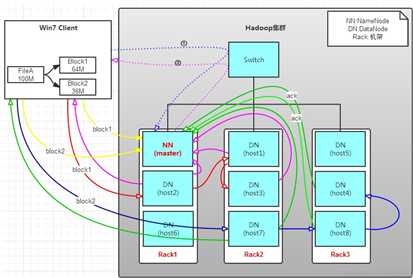
hdsf架构:
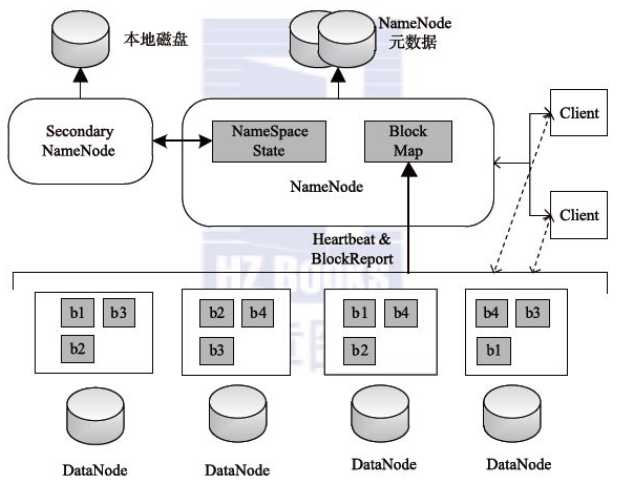
NameNode:
Secondary NameNode:在HA cluster中又称为standby node
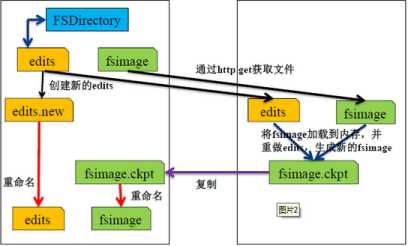
HDFS写文件:
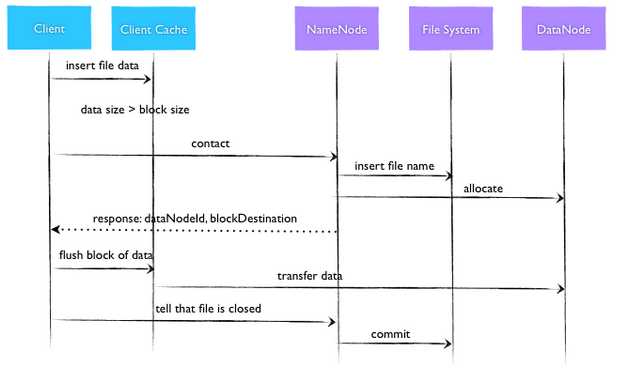
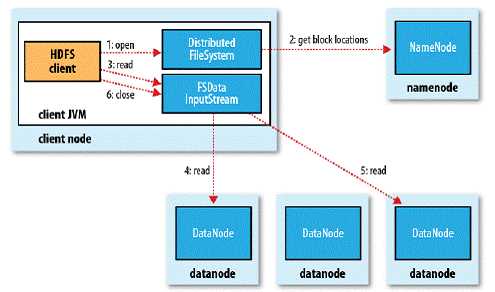
hdfs读文件:
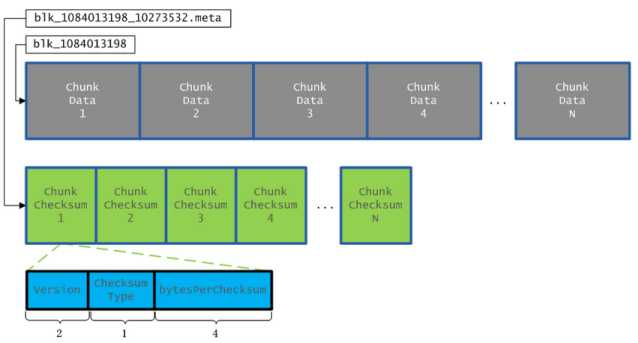
block持续化结构:
标签:缺陷 roc 拓扑 统计信息 input hunk 消息 its 空间
原文地址:http://www.cnblogs.com/Xmingzi/p/6032415.html