标签:开始 expr from attach 问题 ber tab 总结 table
The following co-expression coefficient features were attained from COXPRESdb.
http://coxpresdb.jp/download.shtml
打开这个页面我们点击bulk download
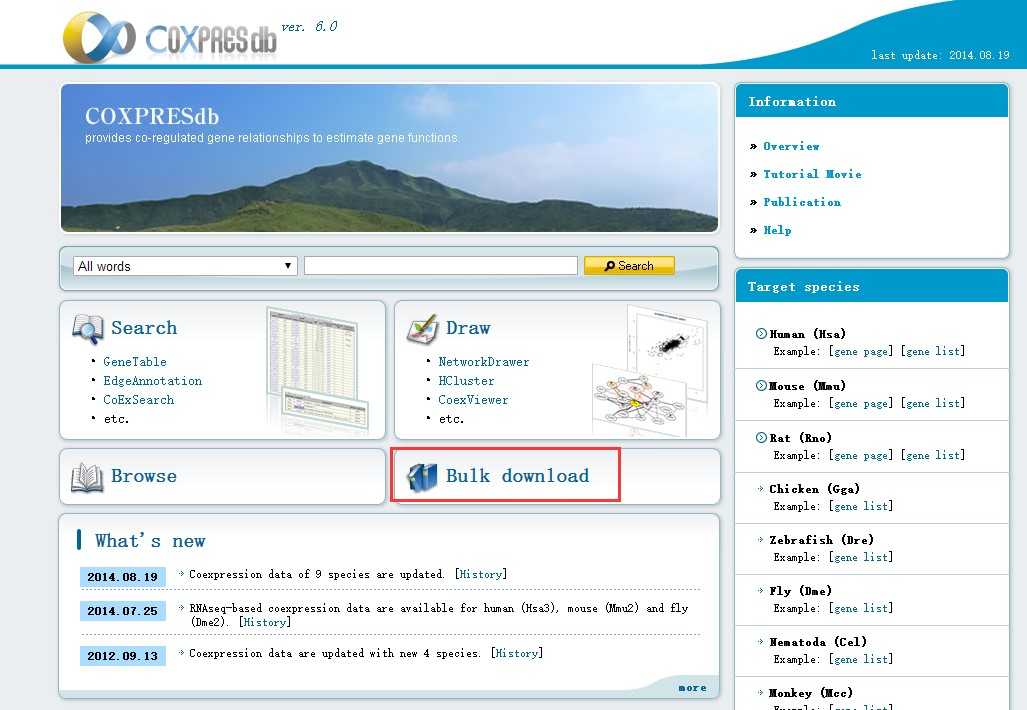

然后我们下载budding yeast 文件。
在最下面我们也可以看到文件格式的说明
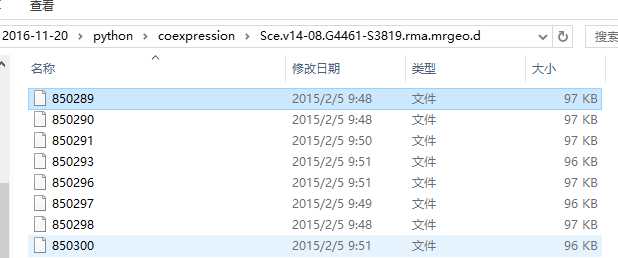
Under the directory named Hsa.coex.v6, 19777 files will appear.
Hsa.coex.v6 ----- 1
|-- 10
|-- 100
|-- ...
|-- 9997
|
|
|
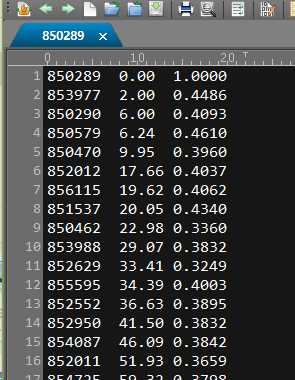
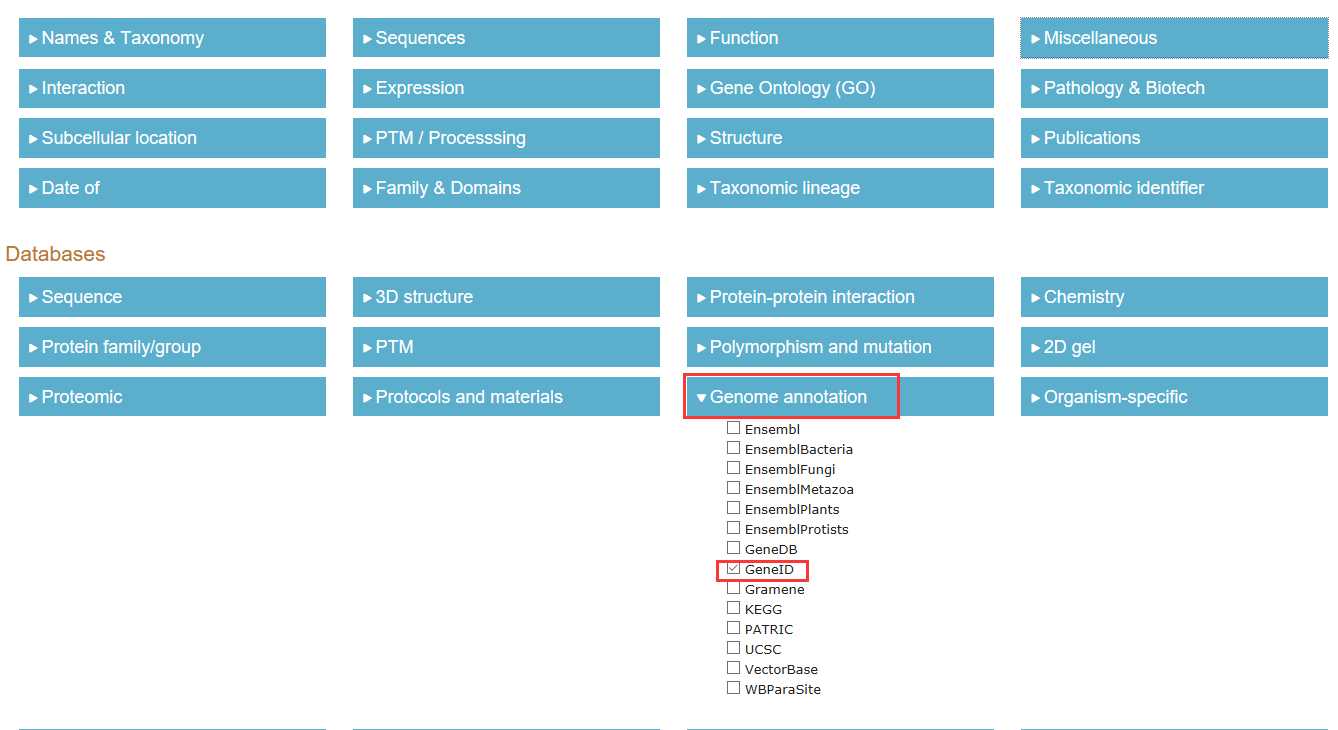
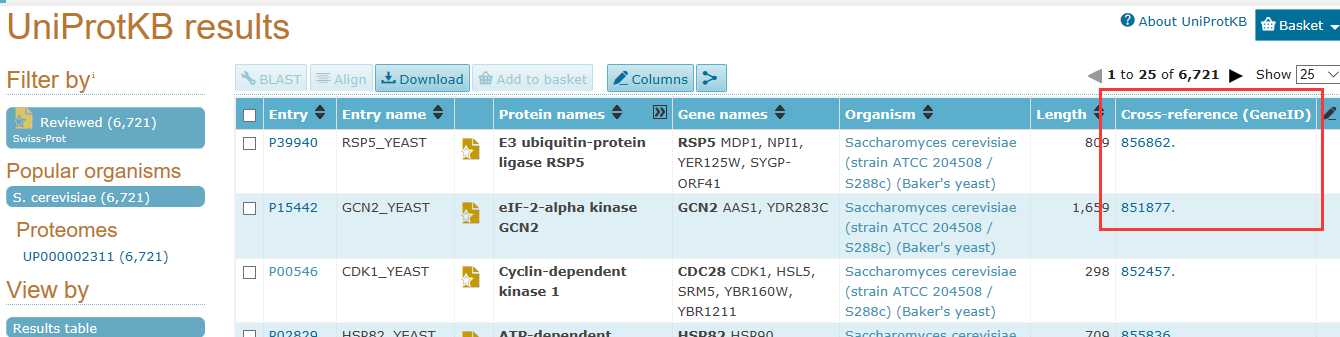

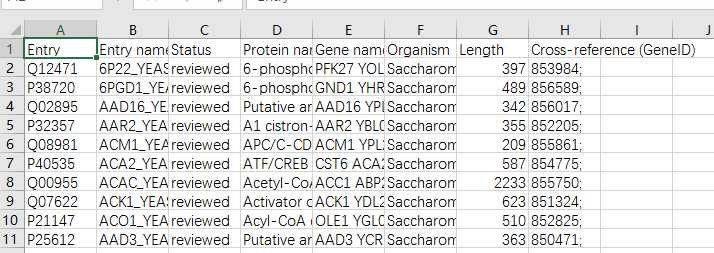
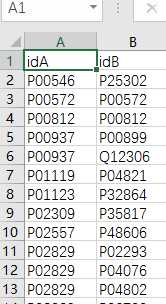
# -*- coding: utf-8 -*-"""Created on Thu Nov 10 10:49:21 2016@author: sun"""import pandas as pdimport osyeast_gold_protein_pair=pd.read_csv(‘yeast_gold_protein_pair.csv‘,usecols=[‘idA‘,‘idB‘])GeneID=pd.read_csv(‘uniprot_to_geneid.csv‘,usecols=[‘Entry‘,‘Cross-reference (GeneID)‘],index_col=0)#注loc通过标签选择数据,iloc通过位置选择数据idA=GeneID.loc[yeast_gold_protein_pair.idA,:]idB=GeneID.loc[yeast_gold_protein_pair.idB,:]idA.index=range(len(idA))idB.index=range(len(idB))mr=[]cor=[]for i in range(len(idA)):GeneIDA=str(idA.iloc[i].values)GeneIDB=str(idB.iloc[i].values)ifGeneIDB!=‘[nan]‘andGeneIDA!=‘[nan]‘:GeneIDA=GeneIDA[2:8]GeneIDB=int(GeneIDB[2:8]) path=‘Sce.v14-08.G4461-S3819.rma.mrgeo.d/‘+GeneIDAif os.path.exists(path): coex=pd.read_csv(path,header=None,sep=‘ ‘,index_col=0)ifGeneIDBin coex.index: mr.append(coex.loc[GeneIDB,1]) cor.append(coex.loc[GeneIDB,2])else: mr.append("nan") cor.append("nan")else: mr.append("nan") cor.append("nan")else: mr.append("nan") cor.append("nan")yeast_gold_protein_pair[‘MR‘]=mryeast_gold_protein_pair[‘COR‘]=coryeast_gold_protein_pair.to_csv(‘coexpression.csv‘,index=False)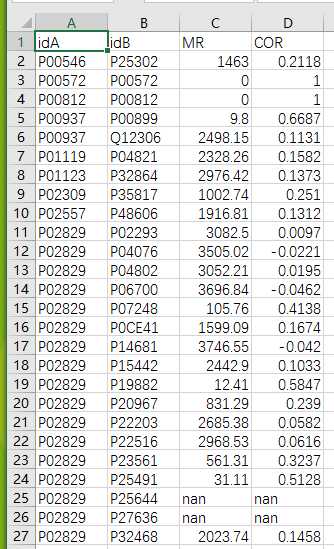
标签:开始 expr from attach 问题 ber tab 总结 table
原文地址:http://www.cnblogs.com/ahusun/p/6069073.html