标签:lang blog 方法 work reg image 配置方法 信息 cin
我是要在另一台新服务器上搭建ESXi,部署了5个虚拟机,用 vSphere Client 管理。(注:如果选择CD/DVD驱动器的时候,一直显示正在连接,则需要重启客户端)
这里我选用的是Cloudera公司的CDH版本,问题少一些,并且可以配套下载,避免遇到各种兼容问题。
系统配置
相关软件全放到/opt目录下,而且环境变量全在各自的安装目录配置文件中设定(也可以在~/.bashrc 中统一设置)
环境变量
配置文件
192.168.0.155 NameNode1
192.168.0.156 NameNode2
192.168.0.157 DataNode1
192.168.0.158 DataNode2
192.168.0.159 DataNode3
127.0.0.1 localhost #这个必须要有
节点配置图

为了以后的模块化管理,打算hadoop,hbase,hive等等都单独建用户
因为这5台机器创建用户,配置权限等的操作是一样的,我们要不就是在五个机器上都敲一遍命令,要不就是在一台机器上配完了再把文件复制过去,都比较繁琐。
因为我用的是Xshell,使用 【Alt + t , k】或者【工具】->【发送键输入到所有会话】,这样只要在一个会话中输入命令,所有打开的会话都会执行,就像是同时在这5台机器上敲命令一样。
su #使用root用户 useradd -m hadoop -s /bin/bash #用同样方式创建hbase,hive,zookeeper,sqoop用户 passwd hadoop #给用户设置密码 visudo #给用户设定权限 :98 在98行新加hadoop的权限即可
接下来就是安装SSH、配置SSH无密码登陆
首先更新一下系统软件
yum upgrade
设置本机公钥、私钥
cd ~/.ssh/ # 若没有该目录,请先执行一次 mkdir ~/.ssh
ssh-keygen -t rsa #一路回车
cat id_rsa.pub >> authorized_keys # 将公钥加入服务器
chmod 600 ./authorized_keys # 修改文件权限
-----------------------------------如果是非root用户,下面这一步必须要做----------------------------------------------------
chmod 700 ~/.ssh #修改文件夹权限 mkdir生成的文件夹默认是775,必须改成700;用ssh localhost生成的文件夹也可以
上面介绍的SSH免密登录本机的,而我们的登录关系是这样的
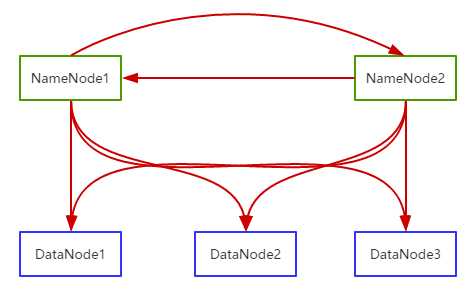
所以 还要分别赋予公钥
使用yum安装java(每一台虚拟机)
sudo yum install java-1.7.0-openjdk java-1.7.0-openjdk-devel
默认安装路径: /usr/lib/jvm/java-1.7.0-openjdk
然后在 /etc/environment 中保存JAVA_HOME变量
sudo vi /etc/environment
内容如下

mv conf/zoo_example.cfg conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/data/zookeeper
dataLogDir=/home/hadoop/logs/zookeeper
clientPort=2181
server.0=NameNode1:2888:3888
server.1=NameNode2:2888:3888
server.2=DataNode1:2888:3888
server.3=DataNode2:2888:3888
server.4=DataNode3:2888:3888
# sudo yum install ntpdate #如果没有安装ntpdate的话,需要先安装
sudo ntpdate time.nist.gov
bin/zkServer.sh start
bin/zkServer.sh status
在/opt下面创建一个文件夹 software并更改用户组
cd /opt sudo mkdir software sudo chown -R hadoop:hadoop software
然后所有大数据相关程序都放到这个文件夹中
export SOFTWARE_HOME=/opt/software
export HADOOP_HOME=/opt/hadoop/hadoop-2.5.0-cdh5.3.6 export HADOOP_PID_DIR=$SOFTWARE_HOME/data/hadoop/pid export HADOOP_LOG_DIR=$SOFTWARE_HOME/logs/hadoop
export YARN_LOG_DIR=$SOFTWARE_HOME/logs/yarn export YARN_PID_DIR=$SOFTWARE_HOME/data/yarn
export HADOOP_MAPRED_LOG_DIR=$SOFTWARE_HOME/logs/mapred export HADOOP_MAPRED_PID_DIR=$SOFTWARE_HOME/data/mapred
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://sardoop</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.users</name> <value>hadoop</value> </property> <property> <name>fs.trash.interval</name> <value>4230</value> </property> <property> <name>io.file.buffer.size</name> <value>65536</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/software/hadoop-2.5.0-cdh5.3.6/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>NameNode1,NameNode2,DataNode1,DataNode2,DataNode3</value> </property> </configuration>
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.nameservices</name> <value>sardoop</value> </property> <property> <name>dfs.ha.namenodes.sardoop</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.sardoop.nn1</name> <value>NameNode1:9820</value> </property> <property> <name>dfs.namenode.rpc-address.sardoop.nn2</name> <value>NameNode2:9820</value> </property> <property> <name>dfs.namenode.http-address.sardoop.nn1</name> <value>NameNode1:9870</value> </property> <property> <name>dfs.namenode.http-address.sardoop.nn2</name> <value>NameNode2:9870</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value> qjournal://DataNode1:8485;DataNode2:8485;DataNode3:8485/sardoop</value> </property> <property> <name>dfs.client.failover.proxy.provider.sardoop</name> <value> org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/software/hadoop-2.5.0-cdh5.3.6/tmp/journal</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.datanode.max.transfer.threads</name> <value>4096</value> </property>
<!--这里必须要加上前缀 file:// 否则会出现警告 should be specified as a URI in configuration files.并无法启动DataNode--> <property> <name>dfs.namenode.name.dir</name> <value>file:///opt/hdfsdata/namenode,file:///home/hadoop/data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///opt/hdfsdata/datanode,file:///home/hadoop/data/hdfs/datanode</value> </property> </configuration>
DataNode1
DataNode2
DataNode3
<configuration> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>NameNode1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>NameNode2</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarnha</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>NameNode1,NameNode2,DataNode1,DataNode2,DataNode3</value> </property> <property> <name>yarn.web-proxy.address</name> <value>NameNode2:9180</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property> </configuration>
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>NameNode1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>NameNode1:19888</value> </property> </configuration>
bin/hdfs dfsadmin -safemode leave
检查HDFS
bin/hdfs fsck / -files -blocks
NameNode2
#主要修改这三项
export HBASE_PID_DIR=${HOME}/data/hbase
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=${HOME}/logs/hbase
<configuration> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.rootdir</name> <!--这里应该是要使用nameservice的,但是用了之后IP解析不正确,只能暂时换成HostName;还要注意一点 这里的必须使用当前处于Active的NameNode--> <!--HBase如果要做HA,这里以后必须要改成Nameservice,否则NameNode发生变化的时候还要手动修改Hbase配置--> <value>hdfs://NameNode1:9820/hbase</value> <!--<value>hdfs://sardoop/hbase</value>--> </property> <property> <name>hbase.zookeeper.quorum</name> <value>NameNode1,NameNode2,DataNode1,DataNode2,DataNode3</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/data/zookeeper</value> </property> </configuration>
NameNode2
DataNode1
DataNode2
DataNode3
注意:有时候启动HBase的时候会出现【org.apache.Hadoop.hbase.TableExistsException: hbase:namespace】
或者什么【Znode already exists】相关的问题,一般都是因为之前的HBase信息已经在Zookeeper目录下已经存在引起的。
解决方法:
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/software/hadoop-2.5.0-cdh5.3.6
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/software/hadoop-2.5.0-cdh5.3.6
#set the path to where bin/hbase is available
export HBASE_HOME=/opt/software/hbase-0.98.6-cdh5.3.6
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/software/hive-0.13.1-cdh5.3.6
#Set the path for where zookeper config dir is (如果有独立的ZooKeeper集群,才需要配置这个)
export ZOOCFGDIR=/opt/software/zookeeper-3.4.5-cdh5.3.6/

cp mysql-connector-java-5.1.40-bin.jar /opt/software/sqoop-1.4.5-cdh5.3.6/lib/
--复制到所有虚拟机的Hadoop目录
cp mysql-connector-java-5.1.40-bin.jar /opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp mysql-connector-java-5.1.40-bin.jar hadoop@NameNode2:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp mysql-connector-java-5.1.40-bin.jar hadoop@DataNode1:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp mysql-connector-java-5.1.40-bin.jar hadoop@DataNode2:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp mysql-connector-java-5.1.40-bin.jar hadoop@DataNode3:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
cp sqljdbc4.jar /opt/software/sqoop-1.4.5-cdh5.3.6/lib/
cp sqljdbc4.jar /opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp sqljdbc4.jar hadoop@NameNode2:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp sqljdbc4.jar hadoop@DataNode1:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp sqljdbc4.jar hadoop@DataNode2:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
scp sqljdbc4.jar hadoop@DataNode3:/opt/software/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/
bin/sqoop help
** 查看sqlserver数据库列表 bin/sqoop list-databases --connect ‘jdbc:sqlserver://192.168.0.154:1433;username=sa;password=123‘
** 查看数据库表
bin/sqoop list-tables --connect ‘jdbc:mysql://192.168.0.154:3306/Test‘ --username sa --password 123
** 直接导表数据到HBase
bin/sqoop import --connect ‘jdbc:sqlserver://192.168.0.154:1433;username=sa;password=123;database=Test‘ --table Cities --split-by Id --hbase-table sqoop_Cities --column-family c --hbase-create-table --hbase-row-key Id
**用sql语句导入
bin/sqoop import --connect ‘jdbc:sqlserver://192.168.0.154:1433;username=sa;password=123;database=Test‘\
--query ‘SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS‘ -m 1
--split-by Id --hbase-table sqoop_Cities --column-family c --hbase-create-table --hbase-row-key Id
** 导入HDFS(因为这是通过MapReduce处理的,所有这个目标路径必须不存在)
./sqoop import --connect ‘jdbc:sqlserver://192.168.0.154:1433;username=sa;password=123;database=Test‘ --table Cities --target-dir /input/Cities
insert into mysql.user(Host,User,Password) values("localhost","hive",password("123"));
create database hive;
grant all on hive*.* to hive@‘%‘ identified by ‘hive‘;
flush privileges;
#为了操作方便,可以选择创建软链接(非必须)
ln -s apache-hive-1.1.0-bin hive
hive-default.xml.template --> hive-site.xml
hive-log4j.properties.template --> hive-log4j.properties
hive-exec-log4j.properties.template --> hive-exec-log4j.properties
hive-env.sh.template --> hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/software/hadoop-2.5.0-cdh5.3.6/
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/software/hive-0.13.1-cdh5.3.6/conf/
# Folder containing extra ibraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/opt/software/hive-0.13.1-cdh5.3.6/lib/
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://NameNode1:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123</value> <description>password to use against metastore database</description> </property>
附:
① 批处理执行脚本(当前节点为NameNode1)
重新格式化时,需要删除数据的脚本
echo --remove hdfs data rm -rf /opt/hdfsdata/datanode/* rm -rf /opt/hdfsdata/namenode/* rm -rf /home/hadoop/data/hdfs/namenode/* rm -rf /home/hadoop/data/hdfs/datanode/* ssh NameNode2 ‘rm -rf /opt/hdfsdata/datanode/*‘ ssh NameNode2 ‘rm -rf /opt/hdfsdata/namenode/*‘ ssh NameNode2 ‘rm -rf /home/hadoop/data/hdfs/namenode/*‘ ssh NameNode2 ‘rm -rf /home/hadoop/data/hdfs/datanode/*‘ ssh DataNode1 ‘rm -rf /opt/hdfsdata/datanode/*‘ ssh DataNode1 ‘rm -rf /opt/hdfsdata/namenode/*‘ ssh DataNode1 ‘rm -rf /home/hadoop/data/hdfs/namenode/*‘ ssh DataNode1 ‘rm -rf /home/hadoop/data/hdfs/datanode/*‘ ssh DataNode2 ‘rm -rf /opt/hdfsdata/datanode/*‘ ssh DataNode2 ‘rm -rf /opt/hdfsdata/namenode/*‘ ssh DataNode2 ‘rm -rf /home/hadoop/data/hdfs/namenode/*‘ ssh DataNode2 ‘rm -rf /home/hadoop/data/hdfs/datanode/*‘ ssh DataNode3 ‘rm -rf /opt/hdfsdata/datanode/*‘ ssh DataNode3 ‘rm -rf /opt/hdfsdata/namenode/*‘ ssh DataNode3 ‘rm -rf /home/hadoop/data/hdfs/namenode/*‘ ssh DataNode3 ‘rm -rf /home/hadoop/data/hdfs/datanode/*‘ echo --remove zookeeper data rm -rf ~/data/zookeeper/version-2/* rm -rf ~/data/zookeeper/zookeeper_server.pid ssh NameNode2 ‘rm -rf ~/data/zookeeper/version-2/*‘ ssh NameNode2 ‘rm -rf ~/data/zookeeper/zookeeper_server.pid‘ ssh DataNode1 ‘rm -rf ~/data/zookeeper/version-2/*‘ ssh DataNode1 ‘rm -rf ~/data/zookeeper/zookeeper_server.pid‘ ssh DataNode2 ‘rm -rf ~/data/zookeeper/version-2/*‘ ssh DataNode2 ‘rm -rf ~/data/zookeeper/zookeeper_server.pid‘ ssh DataNode3 ‘rm -rf ~/data/zookeeper/version-2/*‘ ssh DataNode3 ‘rm -rf ~/data/zookeeper/zookeeper_server.pid‘ echo --remove hadoop logs rm -rf /opt/software/hadoop-2.5.0-cdh5.3.6/tmp rm -rf /home/hadoop/logs/hadoop ssh NameNode2 ‘rm -rf /opt/software/hadoop-2.5.0-cdh5.3.6/tmp‘ ssh NameNode2 ‘rm -rf /home/hadoop/logs/hadoop‘ ssh DataNode1 ‘rm -rf /opt/software/hadoop-2.5.0-cdh5.3.6/tmp‘ ssh DataNode1 ‘rm -rf /home/hadoop/logs/hadoop‘ ssh DataNode2 ‘rm -rf /opt/software/hadoop-2.5.0-cdh5.3.6/tmp‘ ssh DataNode2 ‘rm -rf /home/hadoop/logs/hadoop‘ ssh DataNode3 ‘rm -rf /opt/software/hadoop-2.5.0-cdh5.3.6/tmp‘ ssh DataNode3 ‘rm -rf /home/hadoop/logs/hadoop‘ echo --remove hbase logs rm -rf ~/logs/hbase/* ssh NameNode2 ‘rm -rf ~/logs/hbase/*‘ ssh DataNode1 ‘rm -rf ~/logs/hbase/*‘ ssh DataNode2 ‘rm -rf ~/logs/hbase/*‘ ssh DataNode3 ‘rm -rf ~/logs/hbase/*‘
启动过程的脚本
echo --start zookeeper /opt/software/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start ssh NameNode2 ‘/opt/software/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start‘ ssh DataNode1 ‘/opt/software/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start‘ ssh DataNode2 ‘/opt/software/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start‘ ssh DataNode3 ‘/opt/software/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start‘ echo --start journalnodes cluster ssh DataNode1 ‘/opt/software/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start journalnode‘ ssh DataNode2 ‘/opt/software/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start journalnode‘ ssh DataNode3 ‘/opt/software/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start journalnode‘ echo --format one namenode /opt/software/hadoop-2.5.0-cdh5.3.6/bin/hdfs namenode -format /opt/software/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start namenode echo --format another namenode ssh NameNode2 ‘/opt/software/hadoop-2.5.0-cdh5.3.6/bin/hdfs namenode -bootstrapStandby‘ sleep 10 ssh NameNode2 ‘/opt/software/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start namenode‘ sleep 10 #echo --start all datanodes /opt/software/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemons.sh start datanode echo --zookeeper init /opt/software/hadoop-2.5.0-cdh5.3.6/bin/hdfs zkfc -formatZK echo --start hdfs /opt/software/hadoop-2.5.0-cdh5.3.6/sbin/start-dfs.sh echo --start yarn /opt/software/hadoop-2.5.0-cdh5.3.6/sbin/start-yarn.sh ssh NameNode2 ‘/opt/software/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start resourcemanager‘ /opt/software/hadoop-2.5.0-cdh5.3.6/sbin/mr-jobhistory-daemon.sh start historyserver /opt/software/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start proxyserver
②MySql的安装
因为我使用的是最小版本的CentOS,里面没有Mysql,但是却有部分mysql数据,这会导致再次安装的时候失败。
对安装有帮助的几篇文章
CentOS安装mysql*.rpm提示conflicts with file from package的解决办法
③用MapReduce操作HBase
默认情况下,在MapReduce中操作HBase的时候 会出现各种 java.lang.NoClassDefFoundError 问题,这是因为没有提供相关jar包。解决方法:
HBase官网文档中的路径是错误的,把jar包放到lib下面是没有用的

标签:lang blog 方法 work reg image 配置方法 信息 cin
原文地址:http://www.cnblogs.com/TiestoRay/p/5997353.html
