标签:extra file read import for round lxml inline call
之前用python写爬虫,都是自己用requests库请求,beautifulsoup(pyquery、lxml等)解析。没有用过高大上的框架。早就听说过Scrapy,一直想研究一下。下面记录一下我学习使用Scrapy的系列代码及笔记。
Scrapy的安装很简单,官方文档也有详细的说明 http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html 。这里不详细说明了。
我是用的是pycharm开发,打开pycharm,然后在下面的“Terminal”中输入命令“scrapy startproject freebuf”。这句话是在你的工作空间中创建一个叫“freebuf”的scrapy工程。如下图:
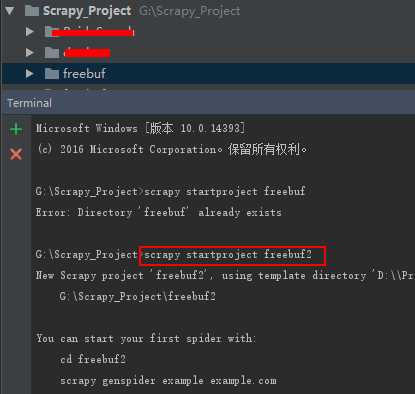
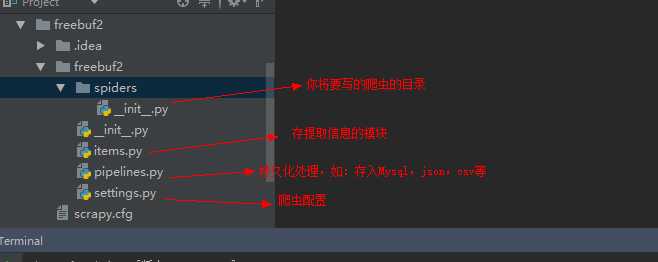
上图中,因为我的工作空间中已经存在“freebuf”所以第一次创建失败,这里我创建的名字为"freebuf2",创建成功。freebuf2的目录及说明如下:
选中“spiders”文件夹,右键“NEW”->"Python File",输入文件名“freebuf2Spider”,添加代码。如下图所示。
#coding:utf-8 import scrapy from freebuf2.items import Freebuf2Item import time from scrapy.crawler import CrawlerProcess class freebuf2Spider(scrapy.Spider): name =‘freebuf2‘ allowed_domains = [] start_urls = ["http://www.freebuf.com/"] def parse(self, response): for link in response.xpath("//div[contains(@class, ‘news_inner news-list‘)]/div/a/@href").extract(): yield scrapy.Request(link, callback=self.parse_next)#这里不好理解的朋友,先去看看yield的用法。我是按协程(就是中断执行)理解的,感觉容易理解。 next_url = response.xpath("//div[@class=‘news-more‘]/a/@href").extract()#找到下一个链接,也就是翻页。 if next_url: yield scrapy.Request(next_url[0],callback=self.parse) def parse_next(self,response): item = Freebuf2Item() item[‘title‘] = response.xpath("//h2/text()").extract() item[‘url‘] = response.url item[‘date‘] = response.xpath("//div[@class=‘property‘]/span[@class=‘time‘]/text()").extract() item[‘tags‘] = response.xpath("//span[@class=‘tags‘]/a/text()").extract() yield item
item.py
itmes对象是种简单的容器,你可以理解为dict,保存了爬取到得数据。代码如下:
import scrapy class Freebuf2Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() date = scrapy.Field() url = scrapy.Field() tags = scrapy.Field()
上面代码已经完成了一个简单的翻页爬虫,但是为了做一个优雅的爬虫。我们还需要对其设置访问间隔时间,在settings.py中添加“DOWNLOAD_DELAY = 3”。意思是,每3秒请求一次。
好了,大功告成。在pycharm中的“Terminal”(cmd也可以哈),切换倒freebuf2工程目录下(就是第一个freebuf2文件夹),输入命令“scrapy crawl freebuf2 -o freebuf2.csv”。就可以运行了。如果想停止,直接输入“shutdown”就可以了。最后看看数据吧。
数据:

标签:extra file read import for round lxml inline call
原文地址:http://www.cnblogs.com/bluesky-ivy/p/6203603.html