标签:png nic 转换 字节 lte font 兼容 default family
1、字符编码
#ASCII码里只能存英文和特殊字符 不能存中文 存英文占1个字节 8位
#中文编码为GBK 操作系统编码也为GBK
#为了统一存储中文和英文和其他语言文字出现了万国码Unicode 所有一个字符都占2个字节 16位
#英文文档改为Unicode编码大小变大一倍 为解决这种浪费空间问题
#出现了Unicode扩展集 Utf-8 为可变长的字符编码 默认英文字符按ASCII码存储 中文按照3个字节存储
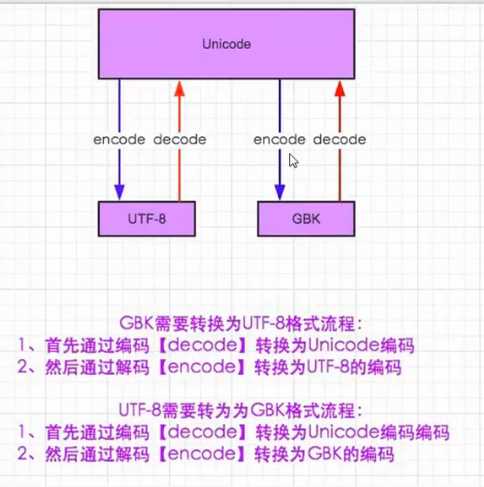
编码都要先decode成unicode再转码成目标编码

#获取默认编码
import sys
print(sys.getdefaultencoding())
#文件头声明编码
#-*- coding:gbk -*-
#文件转码都要先转换成Unicode再转换成目标编码
#转换成Unicode时需要decode("自身编码") 并且传入自身编码即可以转换成unicode
#再转换成目标编码时 要encode("目标编码")
#ptyon3里 encode的时候不仅转换了编码 还变成了bits
s="你好"
#转换成gbk编码
s_gbk=s.encode("gbk")
print(s_gbk)
#gbk转换成utf-8
s_utf8=s_gbk.decode("gbk").encode("utf-8")
print(s_utf8)
#utf-8转换为gb2312
s_gb2312=s.encode("gb2312")
print(s_gb2312)
#gb2312转换为gbk
s_gbk2=s_gb2312.decode("gb2312").encode("gbk")
print(s_gbk2)
#gb2312转换为utf-8
s_utf8_2=s_gb2312.decode("gb2312").encode()
print(s_utf8_2)
print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312"))
#gbk向下兼容gb2312和gb23180
标签:png nic 转换 字节 lte font 兼容 default family
原文地址:http://www.cnblogs.com/LastDance/p/6254371.html