标签:参考 平台 ++ cm4 windows 主机 images 型号 位置
参考网站:
http://blog.163.com/yang_jianli/blog/static/1619900062010391127338/ (Linux配置查看命令)
https://developer.nvidia.com/cudnn (cuDNN)
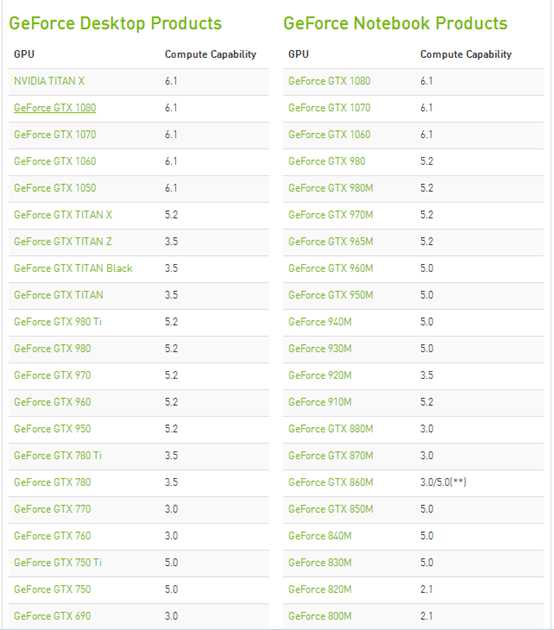
http://developer.nvidia.com/cuda-gpus (显卡计算能力)
http://www.geforce.com/hardware/10series/geforce-store (NVIDIA store)
www.jd.com (京东)
型号: 曙光天阔I950r-G
CPU: 128核 Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
内存: 1TB
显卡: Matrox Graphics, Inc. MGA G200eW WPCM450 (rev 0a)
显存: Memory at ce000000 (32-bit, prefetchable) [size=16M]
Memory at cf800000 (32-bit, non-prefetchable) [size=16K]
Memory at cf000000 (32-bit, non-prefetchable) [size=8M]
系统1: Red Hat Enterprise Linux Server release 6.2 (Santiago)
内核: Linux ict 2.6.32-220.el6.x86_64
系统2: windows server 2008 R2 X64
位置: 10楼机房南门,进门左手边玻璃门进入,主机柜D-09中间位置
负责人:秦立格老师 qinlige@ict.ac.cn 房间:1054
CPU: 8核Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz
显卡: NVIDIA Corporation GK106 [GeForce GTX 660] (rev a1)
显存: Memory at f6000000 (32-bit, non-prefetchable) [size=16M]
Memory at e8000000 (64-bit, prefetchable) [size=128M]
Memory at f0000000 (64-bit, prefetchable) [size=32M]
内核: Linux shirui-All-Series 3.16.0-41-generic
CPU: 双核Intel(R) Core(TM)2 CPU 6600 @2.40GHz
显卡: NVIDIA GeForce 8800 GTS 512
由Google实验室的Corinna Cortes和纽约大学柯朗研究所的Yann LeCun建立。
训练库有60,000张手写数字图像,测试库有10,000张。为28×28的二值图像。

网上大家的测试结果,Caffe cuDNN模式相比CPU模式加速15.64倍,相比GPU模式加速7.7倍。
我的电脑GeForce 8800 GTS 计算能力1.1
诗锐电脑GeForce GTX 660 计算能力3.0
产品 | 显存 | 显存频率 | 主频 | 处理单元 | 电源 | 京东报价 | 官网报价 |
NV IDIA TITAN X | 12G | 3584 | 600W | ¥11200 | $1200 | ||
GeForce GTX 1080 | 8G | 10010MHz | 1800MHz | 2560 | 550W | ¥4999 | $699 |
GeForce GTX 1070 | 8G | 8058MHz | 1700MHz | 1920 | 550W | ¥3199 | $440 |
GeForce GTX 1060 | 6G | 8008MHz | 1700MHz | 1280 | 450W | ¥1999 | $299 |
GeForce GTX 1050 | 4G | 7008MHz | 1400MHz | 768 | 400W | ¥1199 | 停售 |
目前来看,对于神经网络训练的性能GPU要远高于CPU。通过目前的了解,caffe平台似乎并不支持多机训练,还需要进一步调研。Mxnet可以支持多机多卡的训练,TensorFlow也有分布式的训练的版本。
标签:参考 平台 ++ cm4 windows 主机 images 型号 位置
原文地址:http://www.cnblogs.com/yizhichun/p/6339714.html