标签:ace 区分 pac .class int gen pen rate 文件
第一部分 分区简述(比如国家由省市来划分)
分区:map的输出经过partitioner分区进行下一步的reducer。一个分区对应一个reducer,就会使得reducer并行化处理任务。默认为1
1. Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类。
2. HashPartitioner是mapreduce的默认partitioner。计算方法是 which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。
/** Partition keys by their {@link Object#hashCode()}. */ @InterfaceAudience.Public @InterfaceStability.Stable public class HashPartitioner<K, V> extends Partitioner<K, V> { /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value, //这里的key是指的是key2 int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; //numReduceTasks为reduce任务数量
//这里返回值int指的是位置,并非实际意义的数字,如果numReduceTasks为1,则整个结果恒等于0
//也就是说自定义分区返回的是索引或标记
} }
第二部分 分区编程
项目:1.观察数据,如下
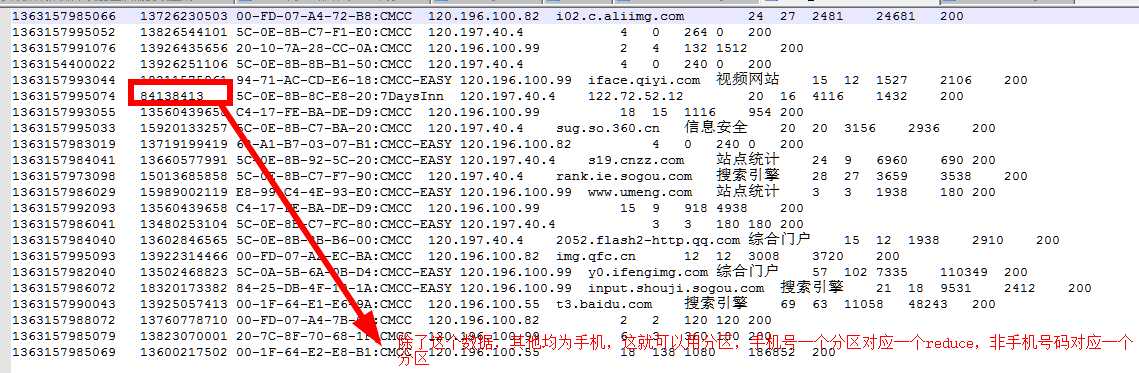
2.不自定义分区的情况
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; /如果不自定义分区,则默认使用的代码为 job.setPartitionerClass(HashPartitioner.class);
3.自定义分区情况
//自定义分区 job.setPartitionerClass(MyPartitioner.class); job.setNumReduceTasks(2);//根据业务需要将手机和非手机用户区分需要做两个分区,对应两个reduce
MyPartition类
//自定义分区代码 private static class MyPartitioner extends Partitioner<Text, TrafficWritable>{ //手机号根据位数判断 @Override public int getPartition(Text key, TrafficWritable value,int numPartitions) { return key.toString().length()==11?0:1; } }
实例代码:

1 package Mapreduce; 2 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.io.Writable; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.Mapper; 14 import org.apache.hadoop.mapreduce.Partitioner; 15 import org.apache.hadoop.mapreduce.Reducer; 16 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 17 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 18 import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; 19 20 public class MyPartitionerTest { 21 public static void main(String[] args) throws Exception { 22 Job job = Job.getInstance(new Configuration(), MyPartitionerTest.class.getSimpleName()); 23 job.setJarByClass(MyPartitionerTest.class); 24 //1.自定义输入路径 25 FileInputFormat.setInputPaths(job, new Path(args[0])); 26 //2.自定义mapper 27 //job.setInputFormatClass(TextInputFormat.class); 28 job.setMapperClass(MyMapper.class); 29 //job.setMapOutputKeyClass(Text.class); 30 //job.setMapOutputValueClass(TrafficWritable.class); 31 32 //如果不自定义分区,则默认使用的代码为 33 //job.setPartitionerClass(HashPartitioner.class); 34 //自定义分区 35 job.setPartitionerClass(MyPartitioner.class); 36 job.setNumReduceTasks(2);//根据业务需要将手机和非手机用户区分需要做两个分区,对应两个reduce 37 38 //3.自定义reduce 39 job.setReducerClass(MyReducer.class); 40 job.setOutputKeyClass(Text.class); 41 job.setOutputValueClass(TrafficWritable.class); 42 //4.自定义输出路径 43 FileOutputFormat.setOutputPath(job, new Path(args[1])); 44 //job.setOutputFormatClass(TextOutputFormat.class);//对输出的数据格式化并写入磁盘 45 46 job.waitForCompletion(true); 47 48 } 49 //自定义分区代码 50 private static class MyPartitioner extends Partitioner<Text, TrafficWritable>{ 51 //手机号根据位数判断 52 @Override 53 public int getPartition(Text key, TrafficWritable value,int numPartitions) { 54 return key.toString().length()==11?0:1; 55 } 56 } 57 58 private static class MyMapper extends Mapper<LongWritable, Text, Text, TrafficWritable>{ 59 Text k2 =new Text(); //k2为第二个字段,手机号码 60 TrafficWritable v2 = new TrafficWritable(); 61 @Override 62 protected void map( 63 LongWritable key, 64 Text value, 65 Mapper<LongWritable, Text, Text, TrafficWritable>.Context context) 66 throws IOException, InterruptedException { 67 // TODO Auto-generated method stub 68 String line = value.toString(); 69 String[] splited = line.split("\t"); 70 //手机号码,第二个字段为手机号 71 k2.set(splited[1]); 72 //流量,注:写代码的时候先写方法名在写方法的实现(测试驱动开发s) 73 v2.set(splited[6],splited[7],splited[8],splited[9]); 74 context.write(k2, v2); 75 } 76 } 77 private static class MyReducer extends Reducer<Text, TrafficWritable, Text, TrafficWritable>{ 78 TrafficWritable v3 = new TrafficWritable(); 79 @Override 80 protected void reduce( 81 Text k2, //表示手机号码 82 Iterable<TrafficWritable> v2s, //相同手机号码流量之和 83 Reducer<Text, TrafficWritable, Text, TrafficWritable>.Context context) 84 throws IOException, InterruptedException { 85 //迭代v2s,将里面的植相加即可 86 long t1 =0L; 87 long t2 =0L; 88 long t3 =0L; 89 long t4 =0L; 90 for (TrafficWritable v2 : v2s) { 91 t1+=v2.t1; 92 t2+=v2.t2; 93 t3+=v2.t3; 94 t4+=v2.t4; 95 } 96 v3.set(t1, t2, t3, t4); 97 context.write(k2, v3);//如果执行没有输出的话,可能reduce没有往外写,或mapper没有写,或源文件没有数据 98 } 99 } 100 //自定义类型 101 private static class TrafficWritable implements Writable{ 102 public long t1; 103 public long t2; 104 public long t3; 105 public long t4; 106 public void write(DataOutput out) throws IOException { 107 out.writeLong(t1); 108 out.writeLong(t2); 109 out.writeLong(t3); 110 out.writeLong(t4); 111 } 112 //t1-4原来是TrafficWritable类型,在set中进行转换 113 public void set(long t1, long t2, long t3, long t4) { 114 // TODO Auto-generated method stub 115 this.t1=t1; 116 this.t2=t2; 117 this.t3=t3; 118 this.t4=t4; 119 } 120 121 public void set(String t1, String t2, String t3,String t4) { 122 // v2的set方法 123 this.t1=Long.parseLong(t1); 124 this.t2=Long.parseLong(t2); 125 this.t3=Long.parseLong(t3); 126 this.t4=Long.parseLong(t4); 127 } 128 129 public void readFields(DataInput in) throws IOException { 130 //顺序不可颠倒,和写出去的顺序需要一致 131 this.t1=in.readLong(); 132 this.t2=in.readLong(); 133 this.t3=in.readLong(); 134 this.t4=in.readLong(); 135 } 136 @Override 137 public String toString() { 138 return Long.toString(t1)+"\t"+Long.toString(t2)+"\t"+Long.toString(t3)+"\t"+Long.toString(t4); 139 } 140 } 141 }
打包并运行:
[root@neusoft-master filecontent]# hadoop jar MyPartitionerTest.jar /data/HTTP_20130313143750.dat /out4
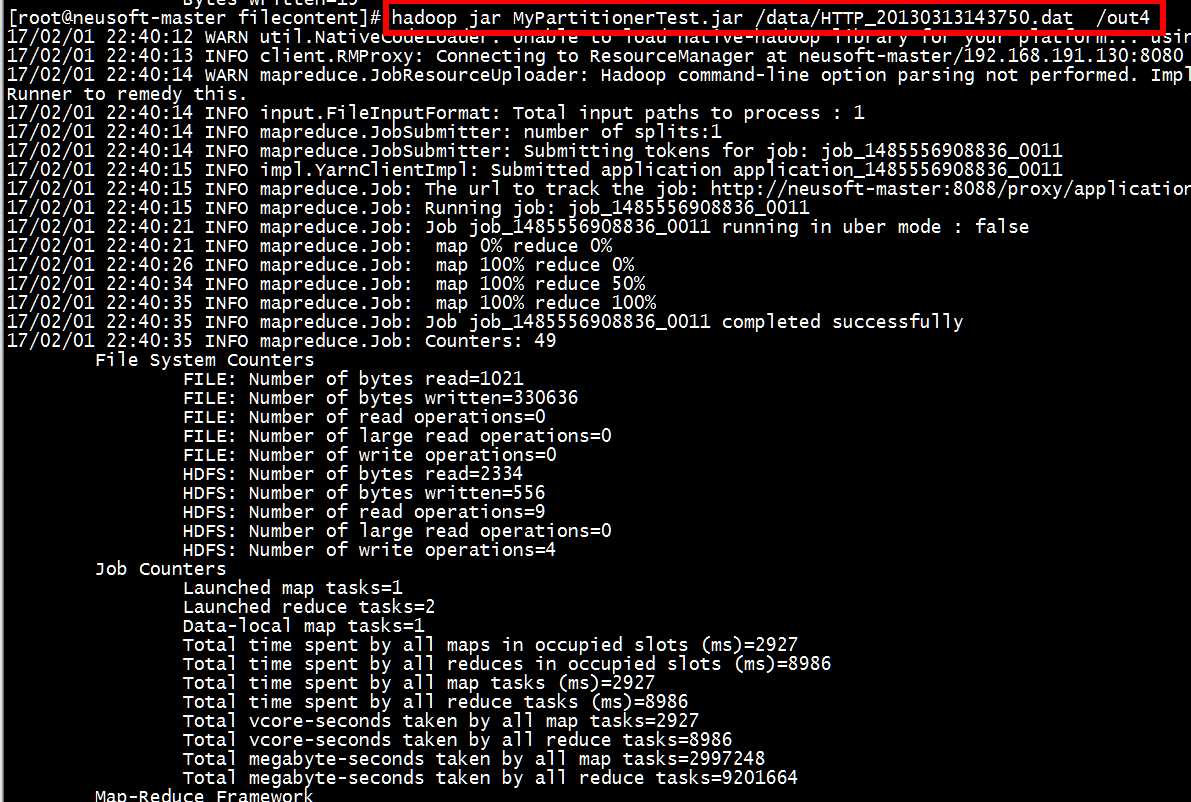
[root@neusoft-master filecontent]hadoop dfs -ls /out4
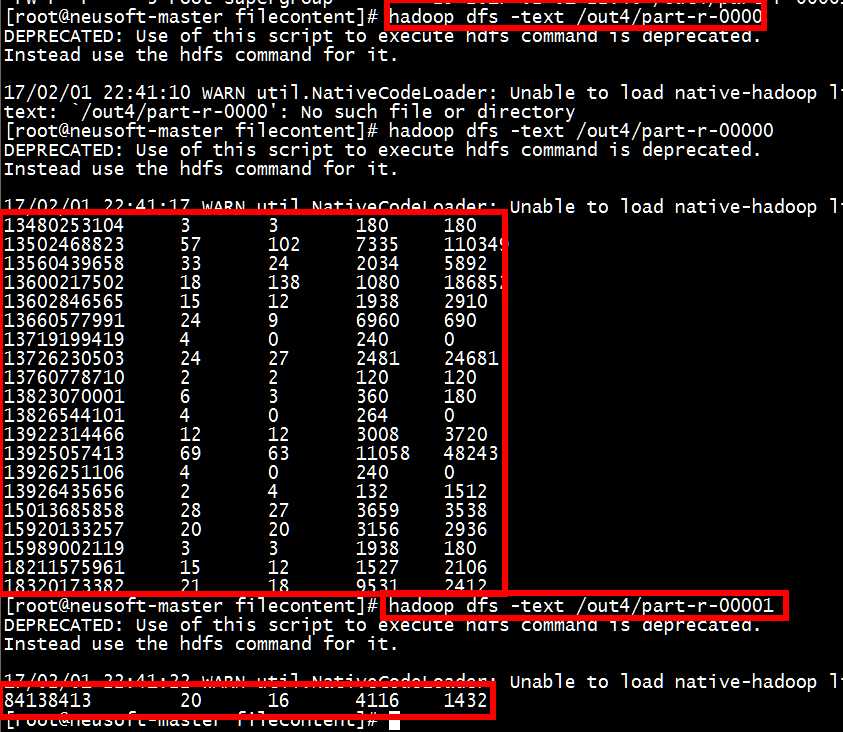
[root@neusoft-master filecontent]# hadoop dfs -text /out4/part-r-00000
[root@neusoft-master filecontent]# hadoop dfs -text /out4/part-r-00001
问题:如果分区数量大于reduce数量,如果分区数量小于educe数量?
实验:更改代码如下,让reduce数量作为参数传入程序中
job.setNumReduceTasks(Integer.parseInt(args[2]));
(1) 一个reduce,两个分区的情况:
[root@neusoft-master filecontent]# hadoop jar MyPartitionerTest2.jar /data/HTTP_20130313143750.dat /out5 1
[root@neusoft-master filecontent]# hadoop dfs -ls /out5
衹有一個輸出:
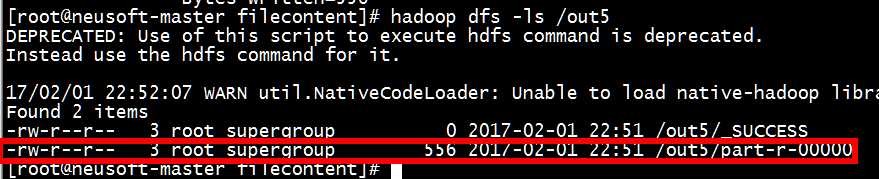
[root@neusoft-master filecontent]# hadoop dfs -text /out5/part-r-00000 ,从结果分析可得,这种情况没有区分两种数据,手机和非手机
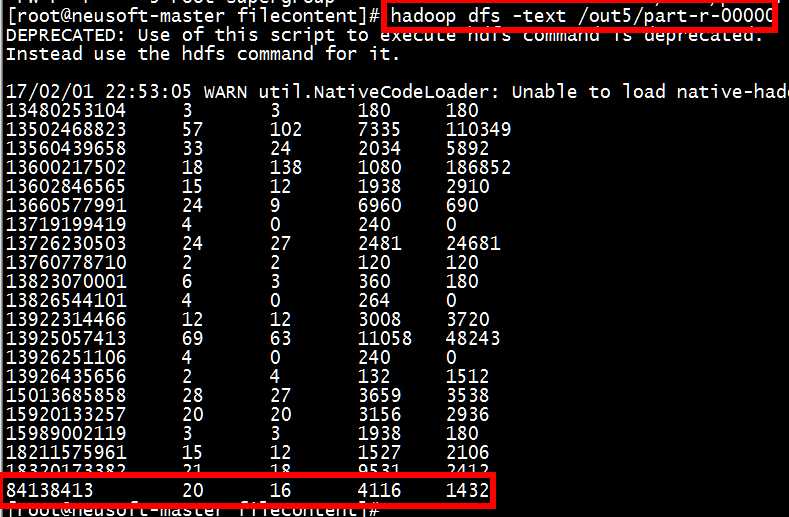
总结:在hadoop2中reduce数量少于partitioner分区数量的时候,程序依然可以执行,但是结果有误。在hadoop1中会报错。
(2) 3个reduce,两个分区的情况:
[root@neusoft-master filecontent]# hadoop jar MyPartitionerTest2.jar /data/HTTP_20130313143750.dat /out6 3
[root@neusoft-master filecontent]# hadoop dfs -ls /out6
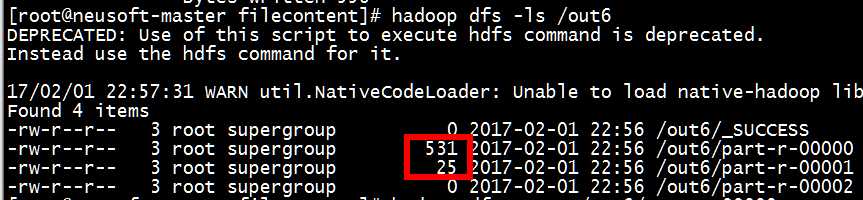
多余的reduce是没有数据的,前面两个是正确的。
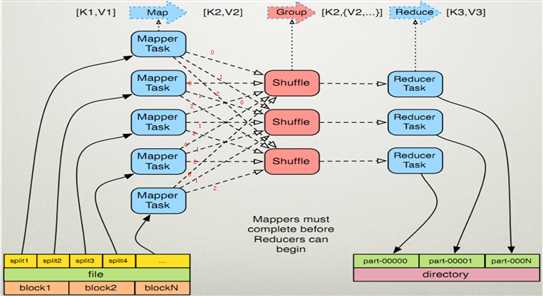
总结:对下图进行分析每一个mapper task都有三个分支,也就是三个任务,如果对每一个任务标号的话,编号为0 的将会分到一个区,编号
为1的分到同一个区,编号为2的分到同一个区。也就是说相同分区的都会给到同一个reduce任务进行处理。
标签:ace 区分 pac .class int gen pen rate 文件
原文地址:http://www.cnblogs.com/jackchen-Net/p/6409724.html
