标签:log map 数据 mapreduce 分布 value 产生 分析 读取数据
在大规模的数据当中,需要分发任务,需要进行分布式的并行编程。Hadoop这样一种开源的大数据分析平台。





Map阶段
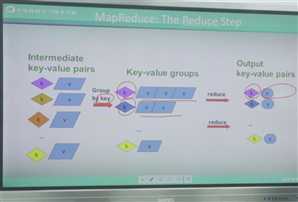
Reduce阶段:相同的键把它聚集到一起之后,然后通过Reduce方式把相同的键聚集的元素进行某种运算。比如说累加运算,比如说累乘运算。
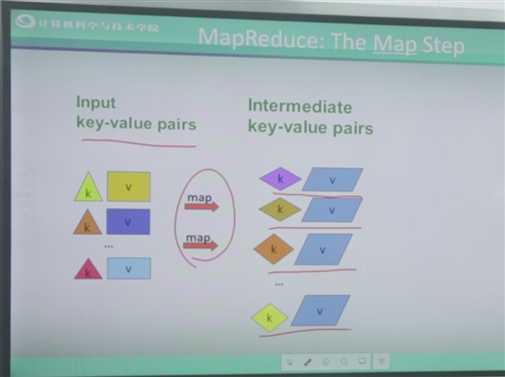
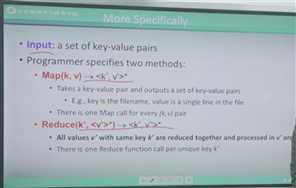
两个步骤:一、输入数据,一行一行;二、产生键值对。三、对键值对进行运算。
实际例子当中键值对是什么样子呢?
假设有一个非常大的文件,这个文件无法存到内存,用户想知道这个文件当中每个单词出现的次数。
像这种运算非常适合用Map-reduce方式来完成。

类似的问题:统计popular urls,统计哪些url被用户点击的次数越多。
Map-reduce的一个过程:
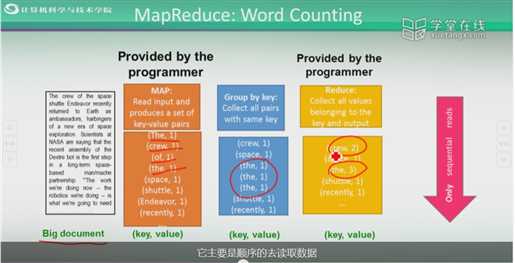
主要是顺序的去读取数据,
使用MapReduce:
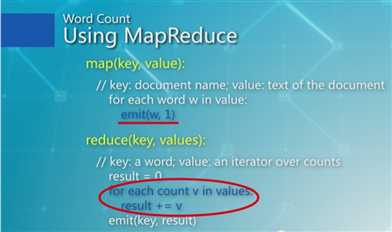
中间的Group阶段由Hadoop自己来完成。
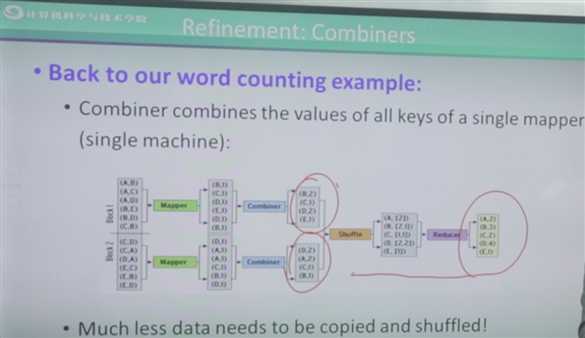
注意:Map它是分发数据,所以Map的个数一般来说是远远大于reduce的个数。

刚才直接从Map到了Reduce,实际上如果学过循环,学过这种语句的嵌套,实际上在Map里面可以做一定的Reduce,在Map和Reduce里面可以相互地进行嵌套。
再看一个例子:Naturl Join,对两个表进行自然连接。

进行自然连接使用Map-reduce怎么做呢?假设进行自然连接的两张表都非常大,无法存到内存当中。我们逐行读取数据,读到一个a1,b1,我们怎么存成key-value呢?key是什么呢?我们是用什么来实现表的连接呢?我们是用b值相同来实现表的连接,用b这一列来作为我们的key。value就是剩下的列。如果写成b1是key,value是a1,这个a1来自于哪里我也必须存在value里面。
最终形成:key是相同的列的名字,value是剩下的列和表的名字。

所以这种问题非常适合Map-reduce操作,逐行顺序读入,产生键值对,将相同的键值所在的元素进行连接操作,形成最终的自然连接的结果。
参考以下网址的内容:
标签:log map 数据 mapreduce 分布 value 产生 分析 读取数据
原文地址:http://www.cnblogs.com/ZHONGZHENHUA/p/6435195.html