标签:查看 平台 设立 上电 时间戳 10g link 多次 soap
原博客地址http://f.dataguru.cn/article-9116-1.html
不久前,数人云联合清华大学交叉信息研究院 OCP 实验室通过 10 台 OCP 服务器成功承载了百万并发 HTTP 请求。
此次实验设立的目标是在物理资源最小值的情况下完成 100 万并发处理,通过此次实验,最大化验证了基于 Mesos 和 Docker 技术的数人云 DCOS (数据中心操作系统)承载高压的能力。
百万压测工具与硬件
压测工具
本次选择的加压工具是分布式压测工具 Locust + Tsung。
Locust (http://locust.io/)是一个简单易用的分布式负载测试工具,主要用来对网站进行负载压力测试。
Locust 官网在比较自己与 Apache JMeter 和 Tsung 的优劣中提到
我们评估过 JMeter 和 Tsung,它们都还不错,我们也曾多次使用过 JMeter,但它的测试场景需要通过点击界面生成比较麻烦,另外它需要给每个测试用户创建一个线程,因此很难模拟海量并发用户。
Tsung 虽然没有上面的线程问题,它使用 Erlang 中的轻量级进程,因此可以发起海量并发请求。但是在定义测试场景方面它面临和 JMeter 同样的不足。它使用 XML 来定义测试用户的行为,你可以想象它有多恐怖。如果要查看任何测试结果,你需要你自己去先去整理一堆测试结果日志文件……
Tsung 是基于 Erlang 的一个开源分布式多协议的负载测试工具,支持 HTTP, WebDAV, SOAP,
PostgreSQL, MySQL, LDAP 和 Jabber/XMPP。访问 http://tsung.erlang-projects.org/ 可以进一步了解。
硬件配置
OCP 是 Facebook 公司创办的( Open Compute Project )开放计算项目,目的是利用开源硬件技术推动 IT 基础设施不断发展,来满足数据中心的硬件需求。
本次实验 OCP 硬件配置如下:
CPU 类型:主频 2.20
双 CPU 24 核 转发端
双 CPU 20 核 加压端
双 CPU 16 核 承压端
内存:DDR3 1600 / 128G
网络:万兆网络
这次压测使用用开源的容器虚拟化技术,将系统和软件环境打平,把软件层所有的系统依赖软件全都封装在 Docker 中。
服务器基础环境无需配置上面承载服务的复杂依赖环境,而把应用程序和依赖环境都封装在容器里,在需要迁移的时候非常方便,应用程序的可移植性得到大大提高,非常便于迁移和扩展。
如何做百万压测
前文已经说到,本次实验的目标是在物理资源最小值的情况下完成 100 万并发处理。遇到了以下几个挑战:
如何加压到 100 万?也就是说,用什么加压方法?
最终需要多少物理资源?架构中每种模块的处理能力是怎样的?
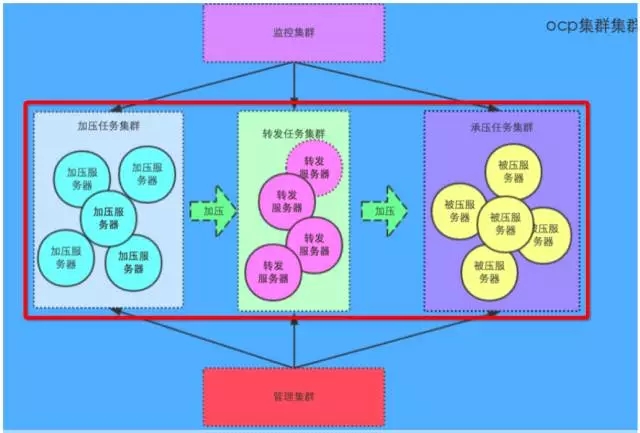
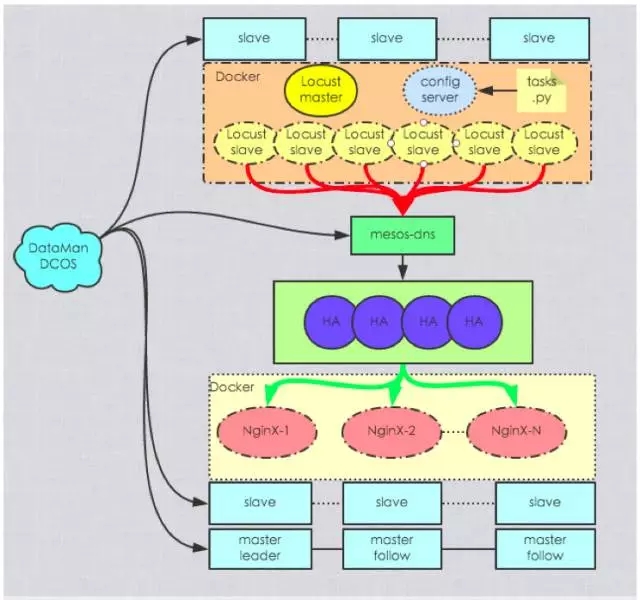
(图1:压测架构图,点击图片可以全屏缩放)
红框内是此次压测实验用到的工作集群,而红框外面的是本次实验的辅助功能集群。需要说明的是,10 台 OCP 服务器承载 100 万 HTTP 请求中的 10 台硬件,指的是转发端加上承压端的机器,不包括加压端的机器,因为在真实场景中加压端是访问用户本身。
下面对这这次压测进行详细说明。
基础环境
基础部署
实验用 OCP 硬件上架、上电、网络构建、系统安装;
使用的系统是 CentOS 7.1,需要升级内核升级到 3.19;
使用 Ansible 部署机器其他底层用软件,包括安装 Docker 1.9.1(ext4 + overlay),打开系统默认约束(文件句柄,系统内核和中断优化)等。
部署云集群
装了标准的系统以及 Docker 之后,机器就可以装数人云了。庞铮在现场展示了数人云集群平台的建立步骤,在两分钟之内完成安装。
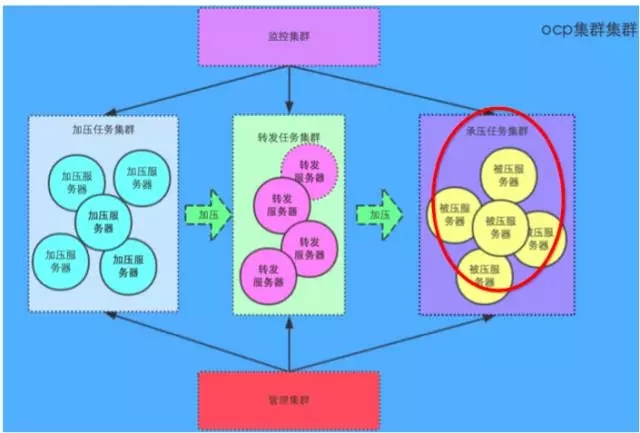
(图2:承压端,点击图片可以全屏缩放)
承压端设计:秒杀项目
云集群安装完之后,就可以发布压测应用了。
首先发布承压端,使用 Nginx + Lua 的组合,它们是高压系统的常用组合,也是数人云秒杀项目原生模组,返回结果是动态无缓存数据,保证压测准确性。由于秒杀模块不是本文重点,下文只做简单描述。
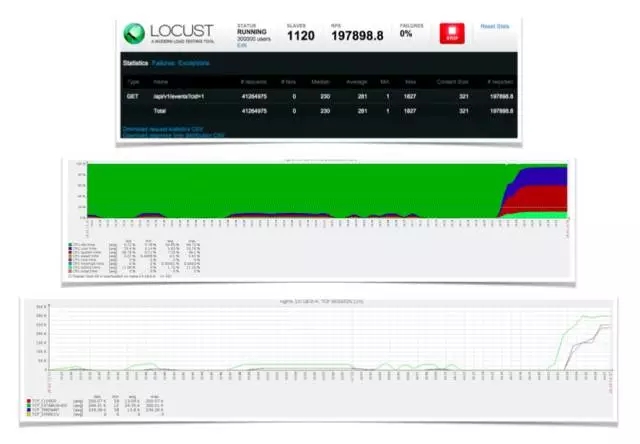
(图3:程序返回结果分析)
在秒杀模块中,Time 是自动从服务器取到的时间戳,events 是秒杀服务的数据;event1 是秒杀活动的项目,48 万是秒杀活动需要持续多少时间。
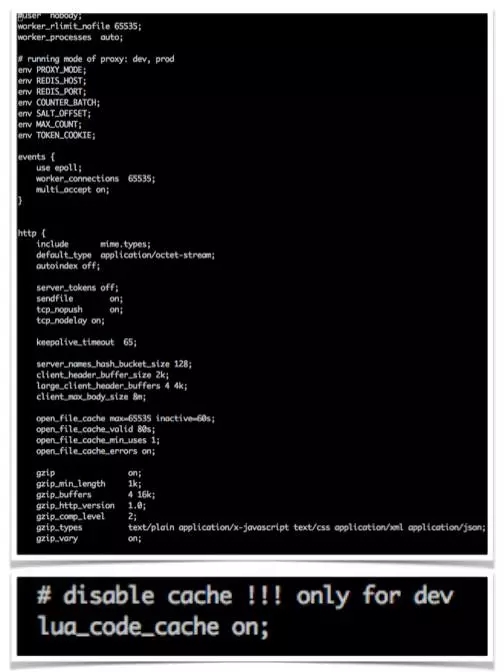
(图:nginx + Lua 优化)
上边是 Nginx 优化方案,也取自网络方案。下边第 2 个框是 Lua 自带优化,对 Lua 的处理能力至关重要。
方案 A 压测
承压端发布完成后,就可以开始部署加压端。Locust 具有分布式、安装简单以及 Web-UI 界面三个特点。
(图:方案A,点击图片可全屏缩放)
选择 Locust 在进行测试过程中遇到的问题
Locust 不能对多个服务端进行压测,所以在它的上面加了 Mesos-DNS,用来汇聚压力提供统一的接口给 Locust slave。Locust 的压测用力文件是 tasks.py,每个 slave 都需要在启动前先去 config server 拉一下 tasks.py。
紧接着就是转发层 HA,再接下来就是 Nginx。
测试 Locust 步骤
测试单核性能:约等于 500/s 处理
测试单机性能:40 核超线程,约等于1w/s 处理
通过测试,发现 Locust 有三个缺点:
单核加压能力低、支持超线程能力差,以及在大量 slave 节点连接的情况下,Master 端不稳定。
(图:Locust-Slave 动用资源)
如上图可以看到,压测资源分为两个组,A 组 20 个物理核机器有 20 台,slave 能压到的能力是 20W/S。B 组 16 个物理核机器有 15 台,可以压到 12W/S,整个加压组的能力为 32W/S。
(图:单机 nginx + Lua HOST)
压测第一步
得到承压单机 Nginx + Lua(HOST) 能力是 19.7 万/s
在考虑 HA 的优化,然后是单台测试,最终选择了keepalive。
压测第二步
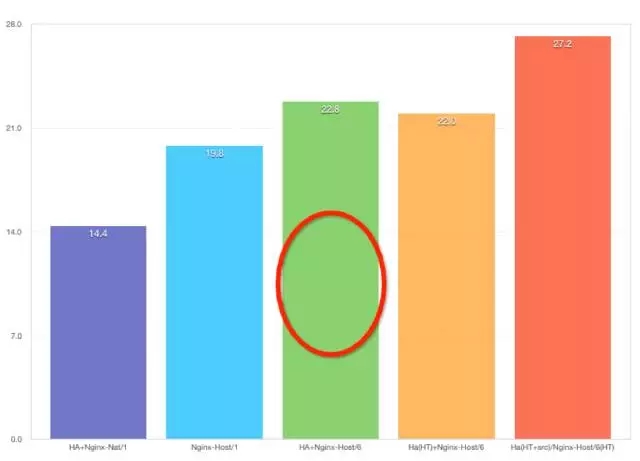
单机非超线程最后测出来的结果是 22.7 万,95% 做到 1 秒之内的响应。测试时候发现,HA 的排队现象非常多,可持续加压能力非常差,几分钟之内就出现严重的堵塞。同时,CPU 有几个是持满的,说明它的分配不均匀,有一些模块是需要有统一的模块调度,导致 HA 无法持续保持高性能处理。
单机超线程比非超线程有一些衰减,测出来的结果是 21.9 万,95%可以做到一秒内响应,但 HA 的排队请求少很多,CPU 的压力也平均了很多,测试结果非常稳定。
HA 超线程的非 Docker,测出的结果是 27 万。Docker 情况下确实有一定衰减,可以明显的看到 99% 的请求在 1 秒内处理了,已经可以达到企业级使用的标准。
现在,已知加压总能力是 32w/s,单机 Nginx + Lua 是 19w/s,转发层单机 Haproxy 最大能力 27w/s,那么,单机 Nginx + Lua NAT 模式的能力是怎样的呢?
可以看出之前单机 Nginx HOST 网络模式下发测试结果是 19.7 万。Nginx 模式加了 HA 再加 NAT 模式,衰减之后是 14.3 万,CPU 压力几乎是100%。
(图:整体测试结果,点击图片可全屏缩放)
由于之前使用的 Locust 对于超线程支持以及本身性能问题,无法在现有硬件资源基础上达到需求,改用 Tsung 进行测试。
方案 B 压测
测试整套文档可参阅:http://doc.shurenyun.com/practice/tsung_dataman.html
更换成方案 B,继续进军百万并发
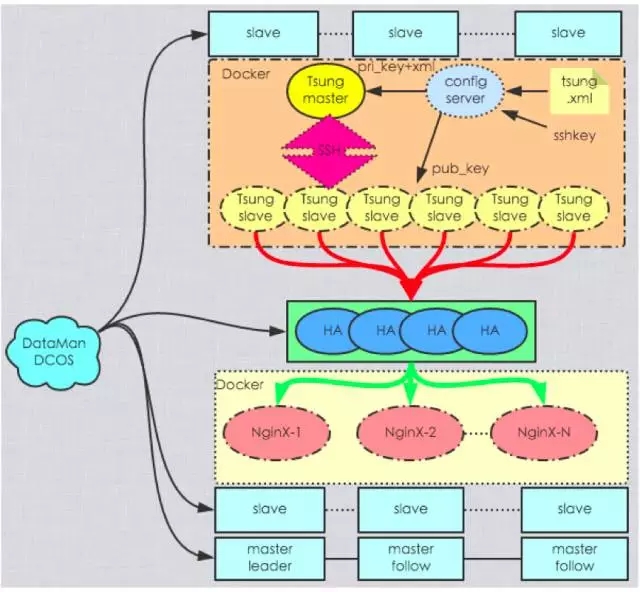
(图:方案B,点击图片可全屏缩放)
架构图解释:Tsung maste 通过 ssh 对 slave 操作,集群之间通讯使用的是 erlang 的 epmd.
执行步骤:
首先将 Tsung 进行 Docker Mesos 化
安装 ssh、安装 Tsung
配置文件 Mesos 化
调用数人云 API 将 Tsung 发布
API 调用脚本 A
方案 B 压测配置
加压端: Tsung 客户端加压机
数量 20
cpu 40 核超线程,cpu 消耗 不到瓶颈
mem 128G
network 万兆网络
docker host模式 、docker 下发20个(每台1个)
Tsung 控制器:本机配置可以缩小很多,测试实体机,随便选了一个
数量 1
cpu 40 核超线程
mem 128G
network 万兆网络
docker host模式、docker 下发1个
转发端: haproxy
数量 4
cpu 48 核超线程、cpu 消耗超高-瓶颈
mem 128G,内存消耗接近 20g
network 万兆网络
docker host 模式、docker 下发 4 个(每台 1 个)
承压 nginx
数量 6
CPU 32 核超线程、cpu 消耗超高-瓶颈
mem 128G、内存消接近耗 10g
network 万兆网络
docker nat 模式、docker 下发 48 个(每台 8 个,折算 48w 并发连接能力,处理每台 14w 左右,总数量 80 万左右)
方案 B 详细报告下载
百万压力测试报告:
http://qinghua.dataman-inc.com/report.html
最终,数人云在 Tsung 的基础上顺利的完成了百万压力测试,业内可以充分参考数人云此次的百万并发实践进行高压系统的设计。点击阅读原文可以了解详细测试参数。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:
Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
兴趣范围包括:Hadoop源代码解读,改进,优化,
分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
基于Locust、Tsung的百万并发秒杀压测案例[转发]
标签:查看 平台 设立 上电 时间戳 10g link 多次 soap
原文地址:http://www.cnblogs.com/mu-shi-shi/p/6441110.html