标签:nbsp tor 配置文件 googl alt 全文检索 条件 lock block
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name、type、indexed与stored,这篇随笔将讲述通过设置type属性的值实现中文分词的检索功能
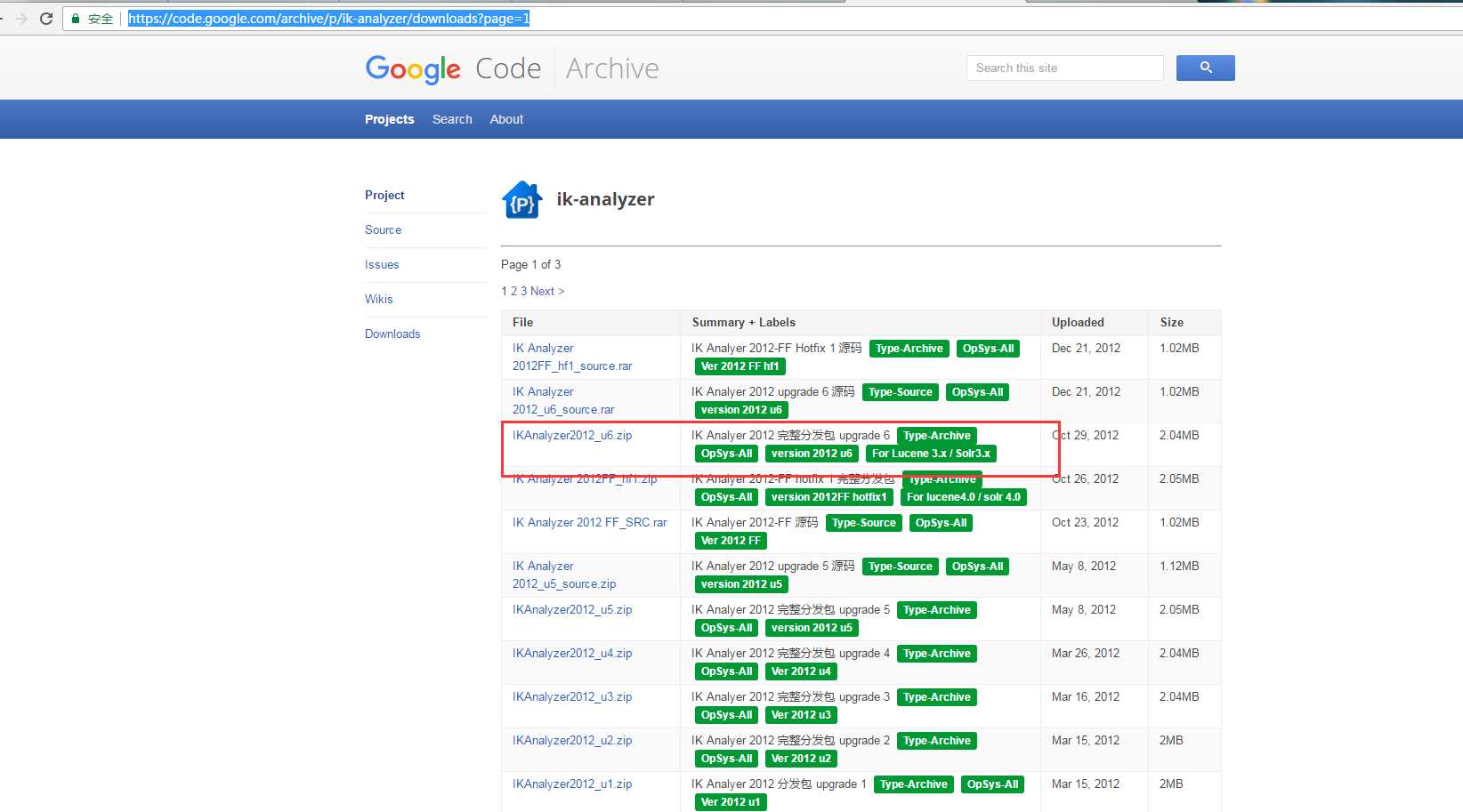
首先下载IK中文分词项目,下载地址https://code.google.com/archive/p/ik-analyzer/downloads?page=1,
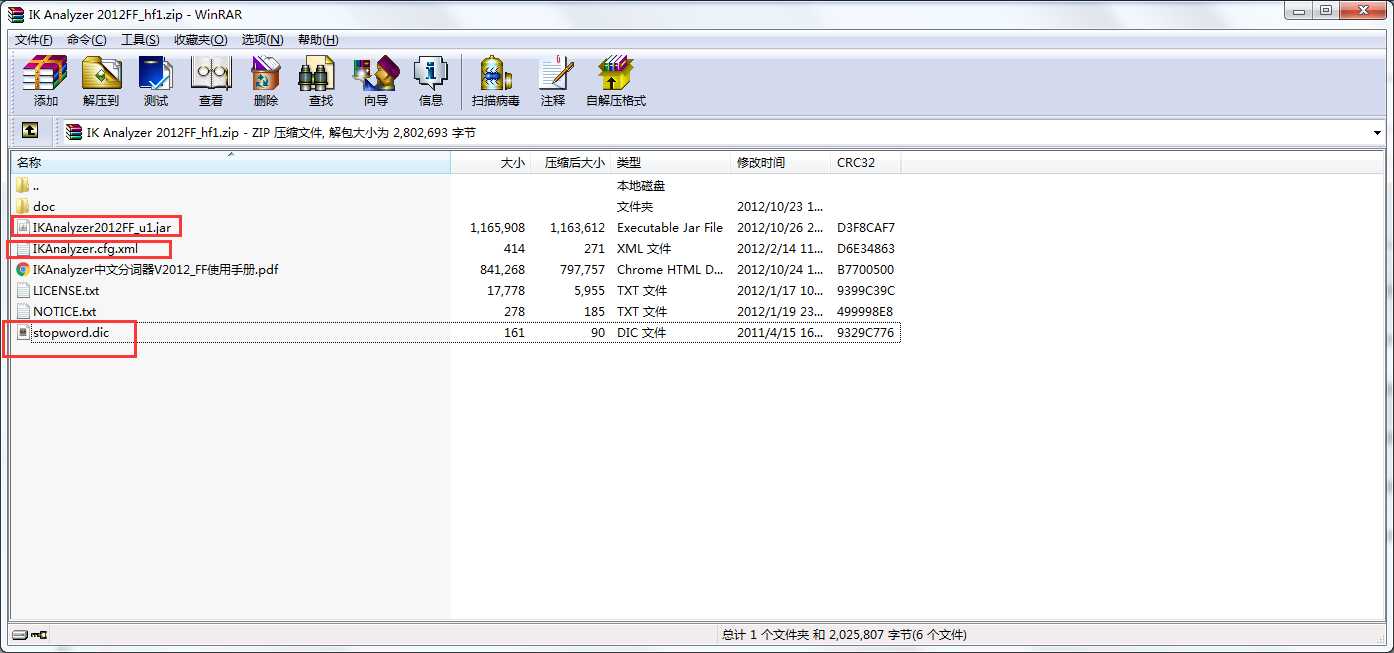
其中除了含有jar包之外,还有三个相关的配置文件
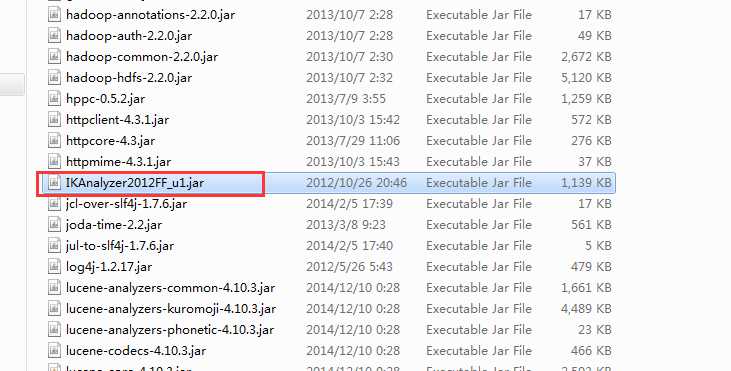
第一步,将IKAnalyzer2012FF_u1.jar添加到项目的WEB-INF\lib目录下
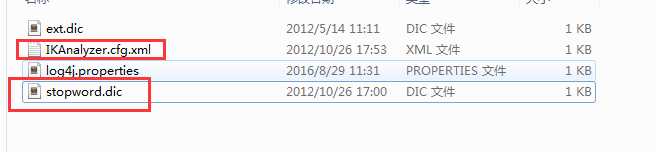
第二步,将IKAnalyzer.cfg.xml与stopword.dic添加到项目的classes目录下
其中的ext.dic文件可手动进行扩展字典配置,在IKAnalyzer.cfg.xml配置文件中,我们可以看到对应的配置
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
第三步,也就是最重要的一步,需要在schema.xml文件中配置分词类型
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
配置完成后,启动本地服务,在Analysis菜单页中可以实现分词测试
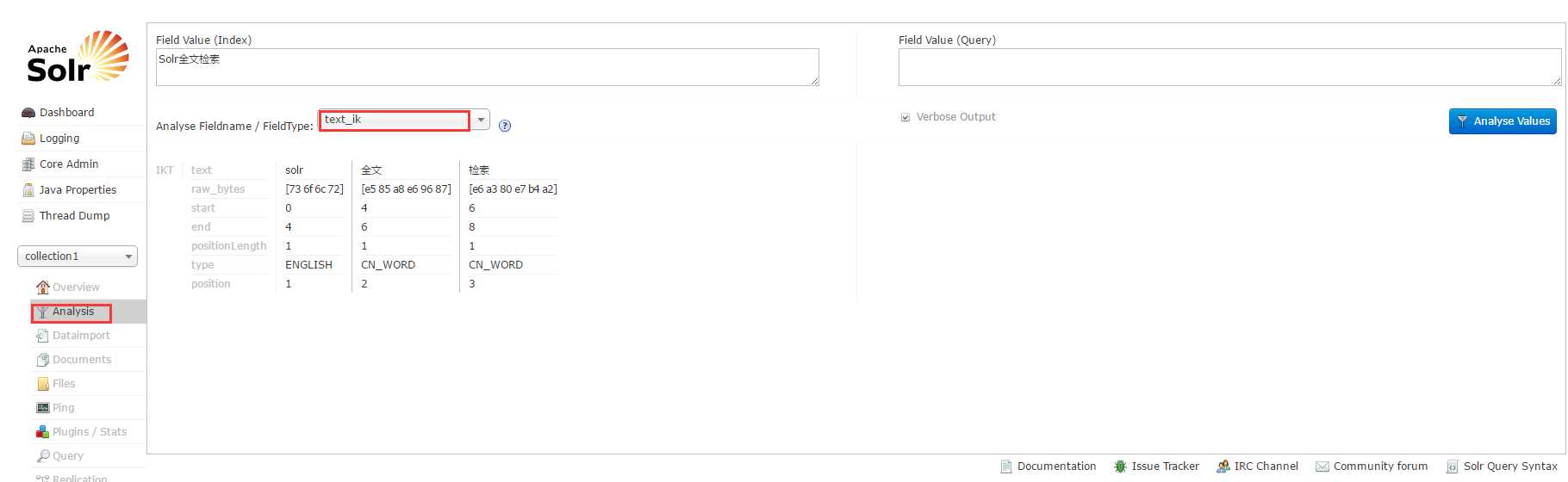
这样我们在自定义field时,对需要分词的字段,则将其type属性值设为fieldType的name值即可实现分词检索
再这里再记录下,在schema.xml中两个会用到的另外两个标签,uniqueKey与solrQueryParser


标签:nbsp tor 配置文件 googl alt 全文检索 条件 lock block
原文地址:http://www.cnblogs.com/xufan/p/6444749.html