标签:过滤 模型 recommend 帮助 font 线性 信息 lte 均值
一、基于内容的推荐系统(Content Based Recommendations)
所谓基于内容的推荐,就是知道待推荐产品的一些特征情况,将产品的这些特征作为特征变量构建模型来预测。比如,下面的电影推荐,就是电影分为"爱情电影"、“动作电影”一些特征来进行预测。

上述例子,将电影的内容特征作为特征变量X1,X2,这些电影特征是预先已知的,用户对电影的打分作为y值。比如一用户对100个电影都做了打分,那对于该用户就有了100个样本值,从而可以利用线性回归求解出该用户对应的参数Θ值,这样每一个用户都有自己参数Θ。



二、协同过滤系统(Collaborative Filtering)
像上述产品的内容特征其实往往是预先不知道的,这个是比较困难的,那怎么办呢?采用协同过滤系统,所谓协同过滤系统,就比如选出用户对电影的打分,来估出相应的的参数Θ值,进而再利用线性回归算出相应的电影特征值,根据特征值再次学习出Θ值,循环反复直到收敛,将会得到一组不错的Θ值与产品特征值。其实也就是用户帮助模型学习特征,这些特征也可以用来对其他人进行预测,另一层意思就是说大家都在为大家的利益学习出更好的特征。
当然,上述描述的循环反复不断学习实践起来会比较麻烦,有一个一劳永逸的方法,可以同时学习出Θ值与特征变量,如下图:

三、计算两个产品的相似性。

四、均值归一化
所谓均值归一化,就是把每一个电影归一化为平均评分为0。因为存在一种情况某一用户对任何一个电影都没有打过分,这个时候该用户对应的Θ学出来就全是0,因为在优化的时候,由于没有对任何电影打分,就相当于没有一个样本,只是优化了正则参数Θ1^2+Θ2^2+...+Θn^2,这样求解出最小值必然Θ=[0,0,0...,0],这样进行预测的时候,该用户对电影的评分也必然全部为0,没什么意义了。所以就需要均值归一化。具体如下图:

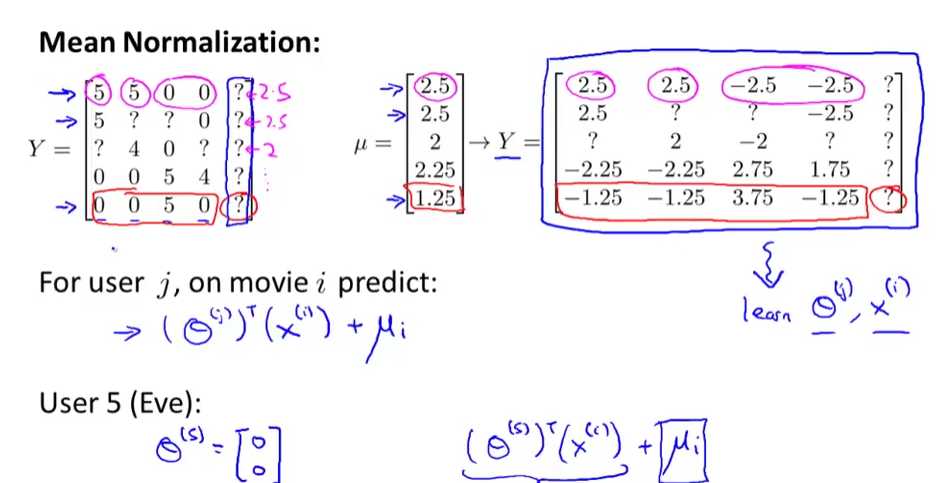
如上图所示,采用了均值归一化后,预测完成后都要再加上均值变量。这样如果遇到上述描述的没有打过分的用户,预测后即使为0,再加上均值向量后,打分就变成了均值分数了。这样从理论上也说得通,如果一个用户从没打过分,也就是没有该用户的任何兴趣倾向信息,那么我们就认为该用户对此电影的兴趣就为一个中间值比较合理。
标签:过滤 模型 recommend 帮助 font 线性 信息 lte 均值
原文地址:http://www.cnblogs.com/gczr/p/6492888.html