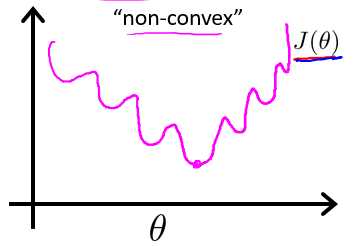
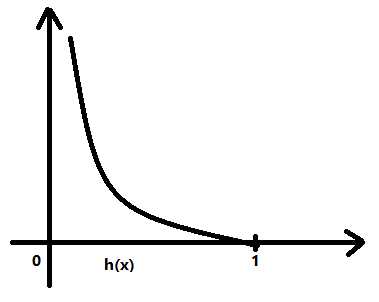
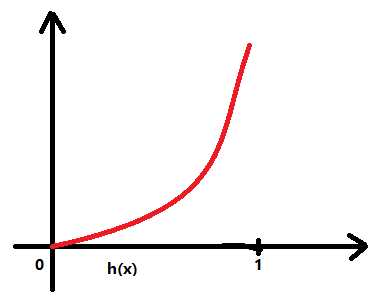
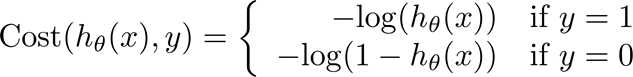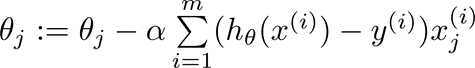标签:tle bsp height 回归 同步 lin 产生 rgb ica
Logistic Regression‘s Cost Function & Classification (2)
原文地址:http://www.cnblogs.com/zhkmxx930/p/adda3641d983f3e10e68278be8b0964e.html