标签:stay poi arrays attr sam could distrib ebs packages
Table of Contents
Note: pandas is a powerfull open source Python data analysis library that is used for data cleaning. A complete documentation can be found here. Please also check the video of 10-minute tour of pandas from Wes McKinney.
If you are using Python for data analysis, we recommend the Anaconda Scientific Python Distribution. It is completely free, and ideal for processing data and doing predictive analysis and scientific computing. You can get the latest the version of Anaconda at https://www.continuum.io/downloads. For more information about getting started with Anaconda and other supports, please refer to the links under LOOKING FOR MORE at http://continuum.io/downloads.
After you download the Anaconda distribution to your local machine, install it and run spyder in the command line. You will be prompted to a similar interface as below: the left part is a text editor where you can write scripts, and the right part is the Console where your analysis results will show when you run your scripts.

Note: you can personalize the font, background color, theme, etc. through Tools -> Preferences. Also, you’ll find the tutorial helpful if you are new to Spyder.
Data analysis packages in Python
For data analysis in Python, we recommend several packages (all included in the Spyder platform):
You’ll also find the book Python for Data Analysis (http://shop.oreilly.com/product/0636920023784.do) helpful.
Here is a simple example (from loading data till handling missing values) for how to clean data using Python.
Note: the dataset we use here is the Canadian Community Health Survey (CCHS), 2012: Mental Health Component. For how to download this dataset from odesi, please refer to this guide: https://data.library.utoronto.ca/finding-and-working-microdata#4d
After you run the program, you can type the below scripts in the console to load dataset into the program. Note that the csv file has to be in the current working directory, otherwise an error will be raised.

We can also see the dimension of the dataset using the shape method (in this case, the dataset has 25113 rows and 586 columns)

We can see the descrptive stat of columns with numeric values, using describe() method:

If say one of the columns which is expected to contain numbers include letters by mistake, you can set them to NaN (missing data) at the time of reading the data.
Suppose the letter included is ‘g‘:
In[8]: cchs = pd.read_csv("cchs2012.csv", header=0, na_values=[‘g‘])
If the data contains missing data indicated by ‘NA‘, you can read the data in as follows:
In[9]: cchs = pd.read_csv("cchs2012.csv", header=0, na_values=[‘NA‘])
You can find all the rows where a specific column holds NaN values as follows:
In[10]: cchs[ pd.isnull(cchs[‘GEO_PRV‘])]
By observations: e.g. get the first 100 observations (rows)

By variables: e.g. get the first 100 variables (columns)

By both: e.g. get the first 100*100 of the original dataset

By variable name: e.g. get column “VERDATE”, “ADM_RNO”, and “GEO_PRV”

Drop observations: e.g. drop the row with index 1 and 3

Drop variables: e.g. drop variables "GEOGCMA1" and "ADM_N09"

Remove duplicates, if any (in this case not)

Replace values: e.g. replace 1 with 7 for the whole dataset (the dimension doesn’t change – only all the 1’s are replaced with 7)

Rename index: e.g. change index from 0 to "person1"

Discretization and binning: set up serveral bins (groups)

Detect and filter outlier: e.g. 5900 -> upper bound

E.g. create a new col “CITIZEN” and make the value for all observations 1

E.g. rename two columns: "ADM_RNO" to "ADM"; "GEO_PRV" to "GEO" (the dimension doesn’t change – only the two column names are changed)

E.g. merge on the unique shared key: subset_7 is the first 10 observations with first columns 0- 99; subset_8 is the first 10 observations with column 1, 100, 101 and 102; the column subset_7 and subset_8 share is column 1, based on which we’ll merge the two subsets.
The merged dataset should have dimension 10*103 (column 0-102)

We use a subset (10*10) of the dataset for this task

Drop missing values: drop the obeservation with missing values


Fill missing values: with column mean


This concludes the Cleaning Data in Python tutorials but it’s only the beginning for aspiring Data Analyst. Here we list some resources that you might find helpful along the way:
Enjoy analyzing data!
You will probably already know that Excel is a spreadsheet application developed by Microsoft. You can use this easily accessible tool to organize, analyze and store your data in tables. What’s more, this software is widely used in many different application fields all over the world.
And, whether you like it or not, this applies to data science.
You’ll need to deal with these spreadsheets at some point, but you won’t always want to continue working in it either. That’s why Python developers have implemented ways to read, write and manipulate not only these files, but also many other types of files.
Today’s tutorial will give you some insights into how you can work with Excel and Python. It will provide you with an overview of packages that you can use to load and write these spreadsheets to files with the help of Python. You’ll learn how to work with packages such as pandas, openpyxl, xlrd, xlutils and pyexcel.
(Try this interactive course: Importing Data in Python, to work with CSV and Excel files in Python.)
When you’re starting a data science project, you will often work from data that you have gathered maybe from web scraping, but probably mostly from datasets that you download from other places, such as Kaggle, Quandl, etc.
But more often than not, you’ll also find data on Google or on repositories that are shared by other users. This data might be in an Excel file or saved to a file with .csv extension, … The possibilities can seem endless sometimes. But whenever you have data, your first step should be to make sure that you’re working with a qualitative data.
In the case of a spreadsheet, you should corroborate that it‘s qualitative because you might not only want to check if this data can answer the research question that you have in mind but also if you can trust the data that the spreadsheet holds.
To check the overall quality of your spreadsheet, you can go over the following checklist:
This list of questions is to make sure that your spreadsheet doesn’t ‘sin’ against the best practices that are generally accepted in the industry. Of course, the above list is not exhaustive: there are many more general rules that you can follow to make sure your spreadsheet is not an ugly duckling. However, the questions that have been formulated above are most relevant for when you want to make sure if the spreadsheet is qualitative.
Previous to reading in your spreadsheet in Python, you also want to consider adjusting your file to meet some basic principles, such as:
?, $,%, ^, &, *, (,),-,#, ?,,,<,>, /, |, \, [ ,] ,{, and };Next, after you have made the necessary changes or when you have taken a thorough look at your data, make sure that you save your changes if you have made any. By doing this, you can revisit the data later to edit it, to add more data or to change them, while you preserve the formulas that you maybe used to calculate the data, etc.
If you’re working with Microsoft Excel, you’ll see that there are a considerable amount of options to save your file: besides the default extension .xls or .xlsx, you can go to the “File” tab, click on “Save As” and select one of the extensions that are listed as the “Save as Type” options. The most commonly used extensions to save datasets for data science are .csv and .txt(as tab-delimited text file). Depending on the saving option that you choose, your data set’s fields are separated by tabs or commas, which will make up the “field separator characters” of your data set.
Now that have checked and saves your data, you can start with the preparation of your workspace!
Preparing your workspace is one of the first things that you can do to make sure that you start off well. The first step is to check your working directory.
When you’re working in the terminal, you might first navigate to the directory that your file is located in and then start up Python. That also means that you have to make sure that your file is located in the directory that you want to work from!
But perhaps more importantly, if you have already started your Python session and you’ve got no clue of the directory that you’re working in, you should consider executing the following commands:
# Import `os`
import os
# Retrieve current working directory (`cwd`)
cwd = os.getcwd()
cwd
# Change directory
os.chdir("/path/to/your/folder")
# List all files and directories in current directory
os.listdir(‘.‘)Great, huh?
You’ll see that these commands are pretty vital not only for loading your data but also for further analysis. For now, let’s just continue: you have gone through all the checkups, you have saved your data and prepped your workspace.
Can you already start with reading the data in Python?
Unfortunately, you’ll still need to do one more last thing.
Even though you don’t have an idea yet of the packages that you’ll need to import your data, you do have to make sure that you have everything ready to install those packages when the time comes.
pipThat’s why you need to have pip and setuptools installed. If you have Python 2 >=2.7.9 or Python 3 >=3.4 installed, you won’t need to worry because then you’ll normally already have it ready. In such cases, just make sure you have upgraded to the latest version.
To do this, run the following command in your terminal:
# For Linux/OS X
pip install -U pip setuptools
# For Windows
python -m pip install -U pip setuptoolsIn case you haven’t installed pip installed yet, run the python get-pip.py script that you can find here. Additionally, you can follow the installation instructions on the page if you need more help to get everything installed properly.
Another option that you could consider if you’re using Python for data science is installing the Anaconda Python distribution. By doing this, you’ll have an easy and quick way to get started with doing data science because you don’t need to worry about separately installing the packages that you need to do data science.
This is especially handy if you’re a beginner, but even for more seasoned developers, it’s a way to quickly test out some stuff without having to install each package separately.
Anaconda includes 100 of the most popular Python, R and Scala packages for data science and several open source development environments such as Jupyter and Spyder. If you’d like to start working with Jupyter Notebook after this tutorial, go to this page.
You can go here to install Anaconda. Follow the instructions to install and you’re ready to start!
That was all you needed to do to set up your environment!
Now, you’re set to start importing your files.
One of the ways that you’ll often use to import your files when you’re working with them for data science is with the help of the Pandas package. The Pandas library is built on NumPy and provides easy-to-use data structures and data analysis tools for the Python programming language.
This powerful and flexible library is very frequently used by (aspiring) data scientists to get their data into data structures that are highly expressive for their analyses.
If you already have Pandas available through Anaconda, you can just load your files in Pandas DataFrames with pd.Excelfile():
# Import pandas
import pandas as pd
# Assign spreadsheet filename to `file`
file = ‘example.xlsx‘
# Load spreadsheet
xl = pd.ExcelFile(file)
# Print the sheet names
print(xl.sheet_names)
# Load a sheet into a DataFrame by name: df1
df1 = xl.parse(‘Sheet1‘)If you didn’t install Anaconda, just execute pip install pandas to install the Pandas package in your environment and then execute the commands that are included in the code chunk above.
A piece of cake, right?
To read in .csv files, you have a similar function to load the data in a DataFrame: read_csv(). Here’s an example of how you can use this function:
# Import pandas
import pandas as pd
# Load csv
df = pd.read_csv("example.csv") The delimiter that this function will take into account is a comma by default, but you can specify an alternative delimiter if you want to. Go to the documentation to find out which other arguments you can specify to make your import successful!
Note that there are also read_table() and read_fwf() functions to read in general delimited files and tables of fixed-width formatted lines into DataFrames. For the first function, the default delimiter is the tab, but you can again override this and also specify an alternative separator character. What’s more, there are also other functions that you can use to get your data in DataFrames: you can find them here.
Let’s say that after your analysis of the data, you want to write the data back to a new file. There’s also a way to write your Pandas DataFrames back to files with the to_excel() function.
But, before you use this function, make sure that you have the XlsxWriter installed if you want to write your data to multiple worksheets in an .xlsx file:
# Install `XlsxWriter`
pip install XlsxWriter
# Specify a writer
writer = pd.ExcelWriter(‘example.xlsx‘, engine=‘xlsxwriter‘)
# Write your DataFrame to a file
yourData.to_excel(writer, ‘Sheet1‘)
# Save the result
writer.save()Note that in the code chunk above, you use an ExcelWriter object to output the DataFrame.
Stated differently, you pass the writer variable to the to_excel() function and you also specify the sheet name. This way, you add a sheet with the data to an existing workbook: you can use the ExcelWriter to save multiple, (slightly) different DataFrames to one workbook.
This all means that if you just want to save one DataFrame to a file, you can also go without installing the XlsxWriter package. Then, you just don’t specify the engine argument that you would pass to the pd.ExcelWriter() function. The rest of the steps stay the same.
Similarly to the functions that you used to read in .csv files, you also have a function to_csv() to write the results back to a comma separated file. It again works much in the same way as when you used it to read in the file:
# Write the DataFrame to csv
df.to_csv("example.csv")If you want to have a tab separated file, you can also pass a \t to the sep argument to make this clear. Note that there are various other functions that you can use to output your files. You can find all of them here.
Besides the Pandas package, which you will probably use very often to load in your data, you can also use other packages to get your data in Python. Our overview of the available packages is based on this page, which includes a list of packages that you can use to work with Excel files in Python.
In what follows, you’ll see how to use these packages with the help of some real-life but simplified examples.
The general advice for installing these packages is to do it in a Python virtualenv without system packages. you can use virtualenv to create isolated Python environments: it creates a folder which contains all the necessary executables to use the packages that a Python project would need.
To start working with virtualenv, you first need to install it. Then, go to the directory in which you want to put your project. Create a virtualenv in this folder and load in a specific Python version if you need it. Then, you activate the virtual environment. After that, you can start loading in other packages, start working with them, etc.
Tip: don’t forget to deactivate the environment when you’re done!
# Install virtualenv
$ pip install virtualenv
# Go to the folder of your project
$ cd my_folder
# Create a virtual environment `venv`
$ virtualenv venv
# Indicate the Python interpreter to use for `venv`
$ virtualenv -p /usr/bin/python2.7 venv
# Activate `venv`
$ source venv/bin/activate
# Deactivate `venv`
$ deactivateNote that the virtual environment might seem a bit troublesome at first when you’re just starting out with your data science project with Python. And, especially when you have only one project to think about, you might not see clearly why you would need a virtual environment at all.
But consider how easy it will be when you have multiple projects running at the same time and you don’t want them to share the same Python installation. Or when your projects have conflicting requirements, then the virtual environment will come in handy!
Now you can finally start installing and importing the packages that you have read about to load in your spreadsheet data.
openpyxlThis package is generally recommended if you want to read and write .xlsx, xlsm, xltx, and xltm files.
Install openpyxl using pip: you saw how to do it in the previous section!
The general advice for installing this package is to do it in a Python virtual environment without system packages. you can use virtual environment to create isolated Python environments: it creates a folder which contains all the necessary executables to use the packages that a Python project would need.
Go to the directory in which your project is located and re-activate the virtual environment venv. Then proceed to install openpyxl with pip to make sure that you can read and write files with it:
# Activate virtualenv
$ source activate venv
# Install `openpyxl` in `venv`
$ pip install openpyxlNow that you have installed openpyxl, you can start loading in the data.
But what is that data exactly?
The workbook with the data that you’re trying to get in Python has the following sheets:
|
Sheet 1
|
Sheet 2
|
Sheet 3
|
The load_workbook() function takes, as you can see, the filename as an argument and return a workbook object, which represents the file. You can check this by running type(wb). Remember to make sure that you’re in the right directory where your spreadsheet is located. Otherwise, you will get an error while importing!
# Import `load_workbook` module from `openpyxl`
from openpyxl import load_workbook
# Load in the workbook
wb = load_workbook(‘./test.xlsx‘)
# Get sheet names
print(wb.get_sheet_names())Remember that you can change the working directory with the help of os.chdir().
You see that the code chunk above returns the sheet names of the workbook that you loaded in Python. Next, you can use this information to also retrieve separate sheets of the workbook.
You can also check which sheet is currently active with wb.active. As you can see in the code below, you can also use it to load in another sheet from your workbook:
# Get a sheet by name
sheet = wb.get_sheet_by_name(‘Sheet3‘)
# Print the sheet title
sheet.title
# Get currently active sheet
anotherSheet = wb.active
# Check `anotherSheet`
anotherSheetYou’ll see that with these Worksheet objects, you won’t be able to do much at first sight. However, you can retrieve values from certain cells in your workbook‘s sheet by using square brackets [], to which you pass the exact cell from which you want to retrieve the value.
Note that this seems very similar to selecting, getting and indexing NumPy arrays and Pandas DataFrames, yet this is not all that you need to do to get the value; You need to add the attribute value:
# Retrieve the value of a certain cell
sheet[‘A1‘].value
# Select element ‘B2‘ of your sheet
c = sheet[‘B2‘]
# Retrieve the row number of your element
c.row
# Retrieve the column letter of your element
c.column
# Retrieve the coordinates of the cell
c.coordinateAs you can see that besides value, there are also other attributes that you can use to inspect your cell, namely row, column and coordinate.
row attribute will give back 2;column attribute to c will give you ‘B‘, andcoordinate will give back ‘B2‘.You can also retrieve cell values by using the cell() function. Pass the row and the column arguments and add values to these arguments that correspond to the values of the cell that you want to retrieve and, of course, don’t forget to add the attribute value:
# Retrieve cell value
sheet.cell(row=1, column=2).value
# Print out values in column 2
for i in range(1, 4):
print(i, sheet.cell(row=i, column=2).value)Note that if you don’t specify the attribute value, you’ll get back <Cell Sheet3.B1>, which doesn’t tell you anything about the value that is contained within that particular cell.
You see that you use a for loop with the help of the range() function to help you to print out the values of the rows that have values in column 2. If those particular cells are empty, you’ll just get back None. If you want to know more about for loops, consider taking our Intermediate Python for Data Science course.
What’s more, there are also special functions that you can call to get certain other values back, like get_column_letter() and column_index_from_string.
The two functions already state more or less what you can retrieve by using them, but for clarity it’s best to make them explicit: while you can retrieve the letter of the column with the former, you can do the reverse or get the index of a column when you pass a letter to the latter. You can see how it works below:
# Import relevant modules from `openpyxl.utils`
from openpyxl.utils import get_column_letter, column_index_from_string
# Return ‘A‘
get_column_letter(1)
# Return ‘1‘
column_index_from_string(‘A‘)You have already retrieved values for rows that have values in a particular column, but what do you need to do if you want to print out the rows of your file, without just focusing on one single column?
You use another for loop, of course!
You say, for example, that you want to focus on the area that lies in between ‘A1‘ and ‘C3‘, where the first specifies the left upper corner and the second the right bottom corner of the area on which you want to focus.
This area will be the so-called cellObj that you see in the first line of code below. You then say that for each cell that lies in that area, you print the coordinate and the value that is contained within that cell. After the end of each row, you’ll print a message that signals that the row of that cellObj area has been printed.
# Print row per row
for cellObj in sheet[‘A1‘:‘C3‘]:
for cell in cellObj:
print(cells.coordinate, cells.value)
print(‘--- END ---‘)Note again how the selection of the area is very similar to selecting, getting and indexing list and NumPy array elements, where you also use square brackets and a colon : to indicate the area of which you want to get the values. In addition, the above loop also makes good use of the cell attributes!
To make the above explanation and code visual, you might want to check out the result that you’ll get back once the loop has finished:
(‘A1‘, u‘M‘)
(‘B1‘, u‘N‘)
(‘C1‘, u‘O‘)
--- END ---
(‘A2‘, 10L)
(‘B2‘, 11L)
(‘C2‘, 12L)
--- END ---
(‘A3‘, 14L)
(‘B3‘, 15L)
(‘C3‘, 16L)
--- END ---Lastly, there are some attributes that you can use to check up on the result of your import, namely max_row and max_column. These attributes are of course general ways of making sure that you loaded in the data correctly, but nonetheless they can and will be useful.
# Retrieve the maximum amount of rows
sheet.max_row
# Retrieve the maximum amount of columns
sheet.max_columnThis is all very good, but I can almost hear you thinking now that this seems to be an awfully hard way to work with these files, especially if you want to still manipulate the data.
There must be something easier, right?
You’re right!
openpyxl has support for Pandas DataFrames! You can use the DataFrame() function from the Pandas package to put the values of a sheet into a DataFrame:
# Import `pandas`
import pandas as pd
# Convert Sheet to DataFrame
df = pd.DataFrame(sheet.values)If you want to specify headers and indices, you need to add a little bit more code:
# Put the sheet values in `data`
data = sheet.values
# Indicate the columns in the sheet values
cols = next(data)[1:]
# Convert your data to a list
data = list(data)
# Read in the data at index 0 for the indices
idx = [r[0] for r in data]
# Slice the data at index 1
data = (islice(r, 1, None) for r in data)
# Make your DataFrame
df = pd.DataFrame(data, index=idx, columns=cols)Next, you can start manipulating the data with all the functions that the Pandas package has to offer. But, remember that you’re in a virtual environment, so if the package is not yet present, you’ll need to install it again via pip.
To write your Pandas DataFrames back to an Excel file, you can easily use the dataframe_to_rows() function from the utils module:
# Import `dataframe_to_rows`
from openpyxl.utils.dataframe import dataframe_to_rows
# Initialize a workbook
wb = Workbook()
# Get the worksheet in the active workbook
ws = wb.active
# Append the rows of the DataFrame to your worksheet
for r in dataframe_to_rows(df, index=True, header=True):
ws.append(r)But this is definitely not all! The openpyxl package offers you high flexibility on how you write your data back to Excel files, changing cell styles or using the write-only mode, which makes it one of the packages that you definitely need to know when you‘re often working with spreadsheets.
Tip: read up more on how you can change cell styles, change to the write-only mode or how the package works with NumPy here.
Now, let‘s also check out some other packages that you can use to get your spreadsheet data in Python.
Before you close off this section,remember that you shouldn’t forget to deactivate the virtual environment when you’re done!
Are you ready to discover more?
xlrdThis package is ideal if you want to read data and format data from files with the .xls or .xlsx extension.
# Import `xlrd`
import xlrd
# Open a workbook
workbook = xlrd.open_workbook(‘example.xls‘)
# Loads only current sheets to memory
workbook = xlrd.open_workbook(‘example.xls‘, on_demand = True)When you don’t want to consider the whole workbook, you might want to use functions such as sheet_by_name() or sheet_by_index() to retrieve the sheets that you do want to use in your analysis.
# Load a specific sheet by name
worksheet = workbook.sheet_by_name(‘Sheet1‘)
# Load a specific sheet by index
worksheet = workbook.sheet_by_index(0)
# Retrieve the value from cell at indices (0,0)
sheet.cell(0, 0).valueLastly, you also see that you can retrieve the value at certain coordinates, which you express with indices, from your sheet.
Continue to xlwt and xlutils to know more about how they relate to the xlrd package!
xlwtIf you want to create spreadsheets that have your data in them, you can also use the xlwt package, apart from the XlsxWriter package. xlwt is ideal to write data and format information to files with an .xls extension.
It works like this when you manually want to write to a file:
# Import `xlwt`
import xlwt
# Initialize a workbook
book = xlwt.Workbook(encoding="utf-8")
# Add a sheet to the workbook
sheet1 = book.add_sheet("Python Sheet 1")
# Write to the sheet of the workbook
sheet1.write(0, 0, "This is the First Cell of the First Sheet")
# Save the workbook
book.save("spreadsheet.xls")If you want to write the data to a file, but you don’t want to go through to the trouble of doing everything yourself, you can always resort to a for loop to automatize the whole process a little bit. Compose a script in which you initialize a workbook and to which you add a sheet. Specify a list with the columns and one with values that will be filled in the worksheet.
Next, you have a for loop that will make sure that all the values get into the file: you say that for every element in the range from 0 to 4 (5 not included), you’re going to do something. You’re going to fill in the values row by row. To do this, you specify a row element that jumps up at every loop. Next, you have another for loop that will go over the columns of your sheet. You say that for every row in the sheet, you’ll look at the columns that go with it and you’ll fill in a value for every column in the row. When you have filled all the columns of the row with values, you’ll go to the next row until you have no rows left.
# Initialize a workbook
book = xlwt.Workbook()
# Add a sheet to the workbook
sheet1 = book.add_sheet("Sheet1")
# The data
cols = ["A", "B", "C", "D", "E"]
txt = [0,1,2,3,4]
# Loop over the rows and columns and fill in the values
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt[index] + num
row.write(index, value)
# Save the result
book.save("test.xls")To again make the result of this code visual, you can see a screenshot of the resulting file here:
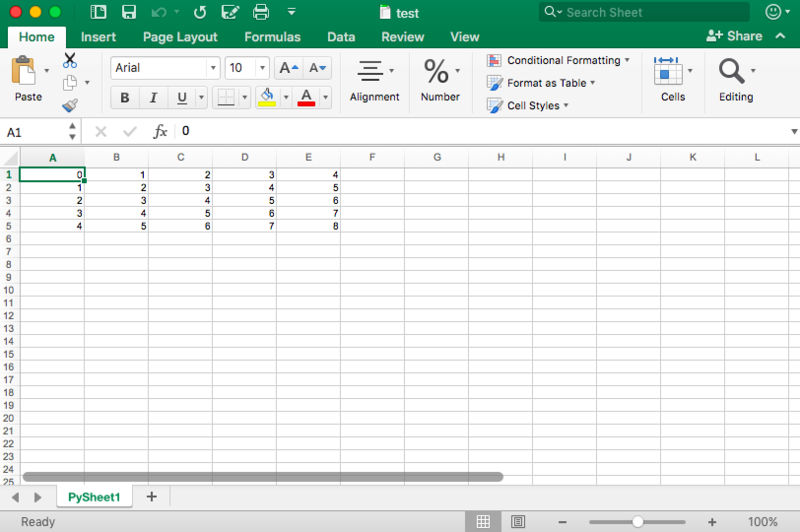
Now that you have seen how the xlrd and xlwt can possibly collaborate together, it’s time to look at a package that is closely linked to these two: xlutils.
xlutilsThis package is basically a collection of utilities that require both xlrd and xlwt, which includes the ability to copy and modify or filter existing files. Generally speaking, these use cases are now covered by openpyxl.
Go back to the section on openpyxl to get more information on how to use this package to get data in Python.
pyexcel To Read .xls or .xlsx FilesAnother package that you can use to read spreadsheet data in Python is pyexcel; It’s a Python Wrapper that provides one API for reading, manipulating and writing data in .csv, .ods, .xls, .xlsx and .xlsm files. Of course, for this tutorial, you will just focus on the .xls and .xls files.
To get your data in an array, you can use the get_array() function that is contained within the pyexcel package:
# Import `pyexcel`
import pyexcel
# Get an array from the data
my_array = pyexcel.get_array(file_name="test.xls")You can also get your data in an ordered dictionary of lists. You can use the get_dict() function:
# Import `OrderedDict` module
from pyexcel._compact import OrderedDict
# Get your data in an ordered dictionary of lists
my_dict = pyexcel.get_dict(file_name="test.xls", name_columns_by_row=0)
# Get your data in a dictionary of 2D arrays
book_dict = pyexcel.get_book_dict(file_name="test.xls")However, you also see that if you want to get back a dictionary of two-dimensional arrays or, stated differently, obtain all the workbook sheets in a single dictionary, you can resort to get_book_dict().
Be aware that these two data structures that were mentioned above, the arrays and dictionaries of your spreadsheet, allow you to create DataFrames of your data with pd.DataFrame(). This will make it easier to handle your data!
Lastly, you can also just retrieve the records with pyexcel thanks to the get_records() function. Just pass the argument file_name to the function and you should be getting back a list of dictionaries:
# Retrieve the records of the file
records = pyexcel.get_records(file_name="test.xls")To learn how you can manipulate Python lists, check out our 18 Most Common Python List Questions.
pyexcelJust like it’s easy to load your data into arrays with this package, you can also easily export your arrays back to a spreadsheet. Use the save_as() function and pass the array and the name of the destination file to the dest_file_name argument:
# Get the data
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Save the array to a file
pyexcel.save_as(array=data, dest_file_name="array_data.xls")Note that if you want to specify a delimiter, you can add the dest_delimiter argument and pass the symbol that you want to use as a delimiter in between "".
If, however, you have a dictionary, you’ll need to use the save_book_as() function. Pass the twodimensional dictionary to bookdict and specify the file name and you’re good:
# The data
2d_array_dictionary = {‘Sheet 1‘: [
[‘ID‘, ‘AGE‘, ‘SCORE‘]
[1, 22, 5],
[2, 15, 6],
[3, 28, 9]
],
‘Sheet 2‘: [
[‘X‘, ‘Y‘, ‘Z‘],
[1, 2, 3],
[4, 5, 6]
[7, 8, 9]
],
‘Sheet 3‘: [
[‘M‘, ‘N‘, ‘O‘, ‘P‘],
[10, 11, 12, 13],
[14, 15, 16, 17]
[18, 19, 20, 21]
]}
# Save the data to a file
pyexcel.save_book_as(bookdict=2d_array_dictionary, dest_file_name="2d_array_data.xls")Something that you should keep in mind when you use the code that is printed in the code chunk above is that the order of your data in the dictionary will not be kept. If you don’t want this, you will need to make a small detour. You can read all about it here.
.csv filesIf you’re still looking for packages that allow you to load in and write data to .csv files besides Pandas, you can best use the csv package:
# import `csv`
import csv
# Read in csv file
for row in csv.reader(open(‘data.csv‘), delimiter=‘,‘):
print(row)
# Write csv file
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
outfile = open(‘data.csv‘, ‘w‘)
writer = csv.writer(outfile, delimiter=‘;‘, quotechar=‘"‘)
writer.writerows(data)
outfile.close()Note also that the NumPy package has a function genfromtxt() that allows you to load in the data that is contained within .csv files in arrays which you can then put in DataFrames. You can find out more about this function in DataCamp’s NumPy tutorial.
When you have the data available, don’t forget the last step: checking whether the data has been loaded in correctly. If you have put your data in a DataFrame, you can easily and quickly check whether the import was successful by running the following commands:
# Check the first entries of the DataFrame
df1.head()
# Check the last entries of the DataFrame
df1.tail()Tip: make use of DataCamp’s Pandas Cheat Sheet when you’re considering loading files as Pandas DataFrames. For more guidance on how to manipulate Python DataFrames, take our Pandas Tutorial: DataFrames in Python.
If you have the data in an array, you can inspect it by making use of the following array attributes: shape, ndim, dtype, etc:
# Inspect the shape
data.shape
# Inspect the number of dimensions
data.ndim
# Inspect the data type
data.dtype
If you want to know more on how you can leverage NumPy arrays for data analysis, consider also going through our NumPy tutorial and definitely don’t forget to use our NumPy cheat sheet!
Congratulations! You have successfully gone through our tutorial that taught you all about how to read Excel files in Python.
But importing data is just the start of your data science workflow. Once you have the data from your spreadsheets in your environment, you can focus on what really matters: analyzing your data. If you have loaded your data in DataFrames, consider taking our Pandas Foundations course or Manipulating DataFrames with Pandas courses which are both taught by Dhavide Aruliah, Director of Training at Continuum Analytics and the creator and driving force behind Anaconda.
If you want to continue working on this topic, however, consider checking out PyXll, which enables to write functions in Python and call them in Excel.
标签:stay poi arrays attr sam could distrib ebs packages
原文地址:http://www.cnblogs.com/think-and-do/p/6606859.html


