标签:code bsp rtp rank note art png res name
1.新建一个项目
scrapy startproject doubanspider
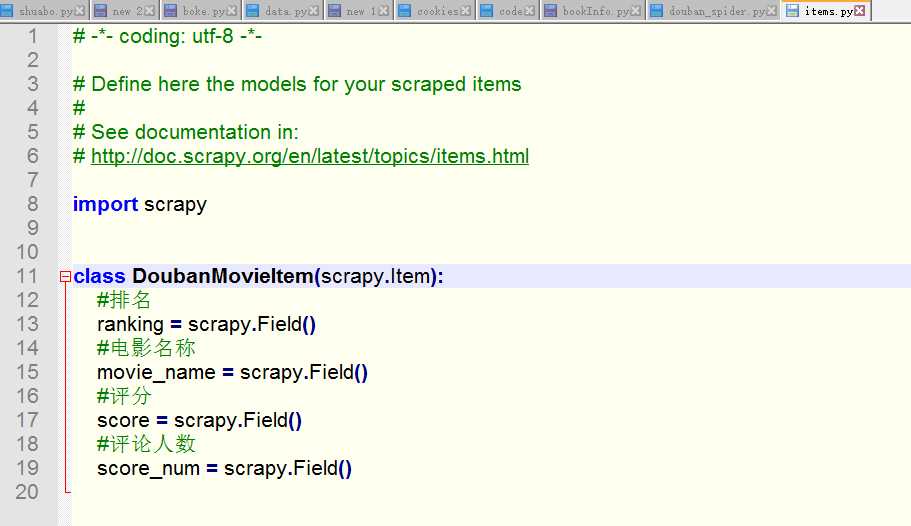
2.编写电影信息item类
3.编写spider类

# -*- coding: utf-8 -*- from scrapy import Request from scrapy.spiders import Spider from doubanspider.items import DoubanMovieItem class DoubanMovieTop250Spider(Spider): name = ‘douban_movie‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36‘, } def start_requests(self): url = ‘https://movie.douban.com/top250‘ yield Request(url,headers=self.headers) def parse(self,response): item = DoubanMovieItem() movies = response.xpath(‘//ol[@class="grid_view"]/li‘) for movie in movies: item[‘ranking‘]=movie.xpath(‘.//div[@class="pic"]/em/text()‘).extract()[0] item[‘movie_name‘]= movie.xpath(‘.//div[@class="hd"]/a/span[1]/text()‘).extract()[0] item[‘score‘] = movie.xpath(‘.//div[@class="star"]/span[@class="rating_num"]/text()‘).extract()[0] item[‘score_num‘] = movie.xpath(‘.//div[@class="star"]/span/text()‘).re(ur‘(\d+)人评价‘)[0] yield item next_url = response.xpath(‘//span[@class="next"]/a/@href‘).extract() if next_url: next_url=‘https://movie.douban.com/top250‘+next_url[0] yield Request(next_url,headers=self.headers)
4.运行结果
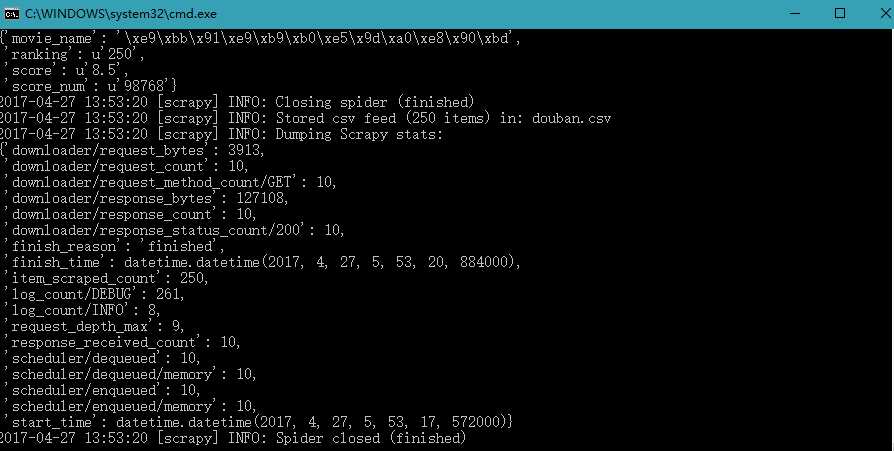
一会就结束了
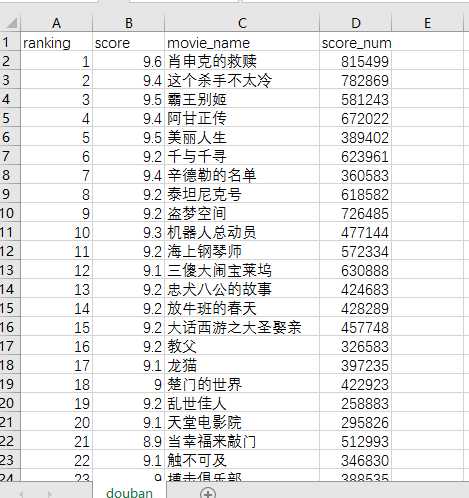
在csv中查看(需要先在Notepad++里打开csv文件,以utf-8编码保存,不然会出现中文乱码)
标签:code bsp rtp rank note art png res name
原文地址:http://www.cnblogs.com/fjl-vxee/p/6773990.html
