标签:term handle 分析 转发 stp his exception 接收 idt
从本篇开始,对elasticsearch的介绍将进入数据功能部分(index),这一部分包括索引的创建,管理,数据索引及搜索等相关功能。对于这一部分的介绍,首先对各个功能模块的分析,然后详细分析数据索引和搜索的整个流程。
这一部分从代码包结构上可以分为:index, indices及lucene(common)几个部分。index包中的代码主要是各个功能对应于lucene的底层操作,它们的操作对象是index的shard,是elasticsearch对lucene各个功能的扩展和封装。indices部分是对index部分功能的封装,集群对于底层索引的操作多数通过这一部分提供的接口来进行。common包中的lucene包部分代码主要是对于索引一下读操作的封装。如读取索引元数据,搜索中用到的一些过滤器的实现等。
在index部分通过对lucene的封装,为es提供了索引操作各个功能的接口。如codec,这一部分是lucene索引写入的部分。在4.x后这一部分被分开成为单独的一层,在这里对其进行了封装。postformat是lucene中倒排表的写入格式,封装后通过postingformatservice对外提供。而具体的postform则是由postprovide提供。它的继承关系如下所示:
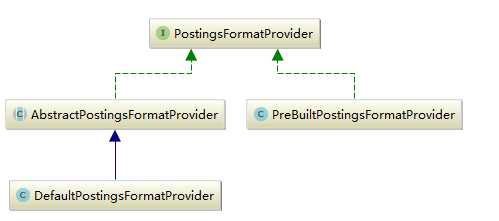
外部通过调研postingservice的get方法获取到对应的postingprovider,代码如下所示:
public PostingsFormatProvider get(String name) throws ElasticsearchIllegalArgumentException { PostingsFormatProvider provider = providers.get(name); if (provider == null) { throw new ElasticsearchIllegalArgumentException("failed to find postings_format [" + name + "]"); } return provider; }
这里的provides在service初始化时注入,当然es的1.5版本只是使用了默认的DefaultPostingFormatProvider。postformat的获取则是通过postingprovider的get的方法,而对应的postingformat初始化在构造方法总实现:
public DefaultPostingsFormatProvider(@Assisted String name, @Assisted Settings postingsFormatSettings) { super(name); this.minBlockSize = postingsFormatSettings.getAsInt("min_block_size", BlockTreeTermsWriter.DEFAULT_MIN_BLOCK_SIZE); this.maxBlockSize = postingsFormatSettings.getAsInt("max_block_size", BlockTreeTermsWriter.DEFAULT_MAX_BLOCK_SIZE); this.postingsFormat = new Lucene41PostingsFormat(minBlockSize, maxBlockSize); }
可以看到这里就是初始化了lucene的postingformat。这一部分的实现多数都跟codec的实现类似,后面的分析中会其中的一些做详细的介绍。这里对于写索引的方法都在Engine中。这里封装了所有对于索引写操作的方法,后面会详细分析。
关于common部分的lucene的功能基本山都是对lucene的读操作,如对于segment信息读取的方法如下所示:
public static SegmentInfos readSegmentInfos(Directory directory) throws IOException { final SegmentInfos sis = new SegmentInfos(); sis.read(directory); return sis; }
直接调用了lucene的segmentInfos类读取segment信息。这一部分在后面会单独分析,这里只是简单介绍一下。
index部分是shard基本的接口,这里的操作都是针对于单个机器单个shard(lucene index)的操作,不涉及集群。而indice部分则通过封装index的相关功能为集群对于index的操作提供了相关接口。如这里的store部分,只是提供了一个实现类IndiceStore,它的实现如下所示。
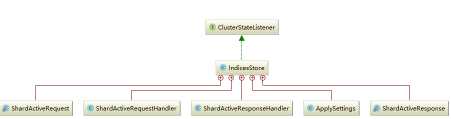
它实现了多个handle类用于处理来自集群的相关请求。跟之前结束的handler一样,这些内部类会接收处理属于本节点的请求,转发属于本节点请求到对应节点。
总结:以上就是elasticsearch数据(index)部分的代码结构。这里只是简单的概述,后面会对对应的部分进行详细分析。
标签:term handle 分析 转发 stp his exception 接收 idt
原文地址:http://www.cnblogs.com/zziawanblog/p/6789837.html