标签:get 收集 XML efi 封装 pass 静态 回顾 least
这两天简单整理了一下MyBatis
相关api和jar包这里提供一个下载地址,免得找了
链接:http://pan.baidu.com/s/1jIl1KaE 密码:d2yl

2.进行相关xml配置
放在根目录下

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jhdx.mapper.T_CustomerMapper">
<!-- 通过编号查询用户 -->
<select id="getAllCustomer" resultType="Customer">
select * from t_customer
</select>
<select id="getCustomerById" parameterType="java.lang.Integer" resultType="Customer">
select * from t_customer where id=#{id}
</select>
<select id="getCustomerByName" parameterType="java.lang.String" resultType="Customer">
select * from t_customer where name like "%"#{name}"%"
</select>
<insert id="insertCustomer" parameterType="Customer">
insert into t_customer(name,age,tel) values(#{name},#{age},#{tel})
</insert>
</mapper>
String resource = "mybatis-config.xml";
InputStream inputStream=null;
inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//创建session工厂
SqlSession session=sqlSessionFactory.openSession();
//调用接口方法
T_CustomerMapper t_CustomerMapper=session.getMapper(T_CustomerMapper.class);
T_Customer t_Customer = new T_Customer();
t_Customer=t_CustomerMapper.getCustomerByName("1");
System.out.println(t_Customer.getName());


<mappers>
<!-- 配置映射文件 -->
<mapper resource="com/jhdx/mapper/T_customerMapper.xml" />
<mapper class="com.jhdx.mapper.T_customerMapper" />
</mappers>
<select id="getCustomerByName" parameterType="java.lang.String" resultType="Customer">
select * from t_customer where name like "%"#{name}"%"
</select>
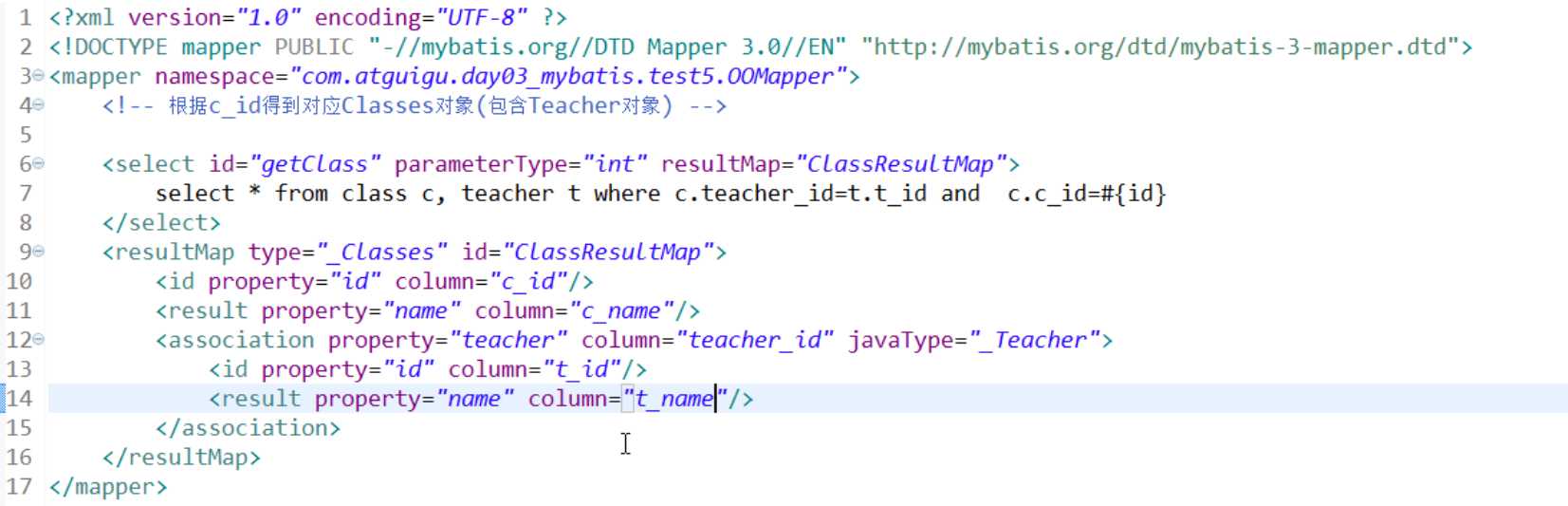

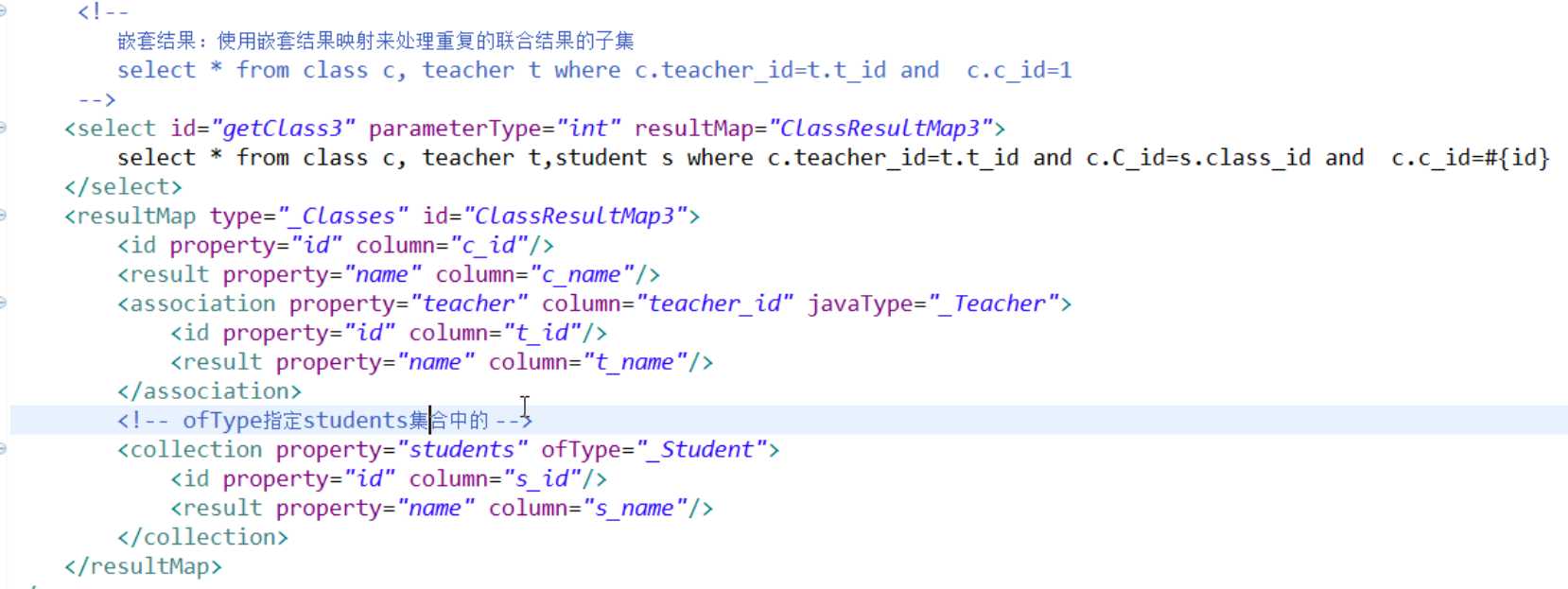
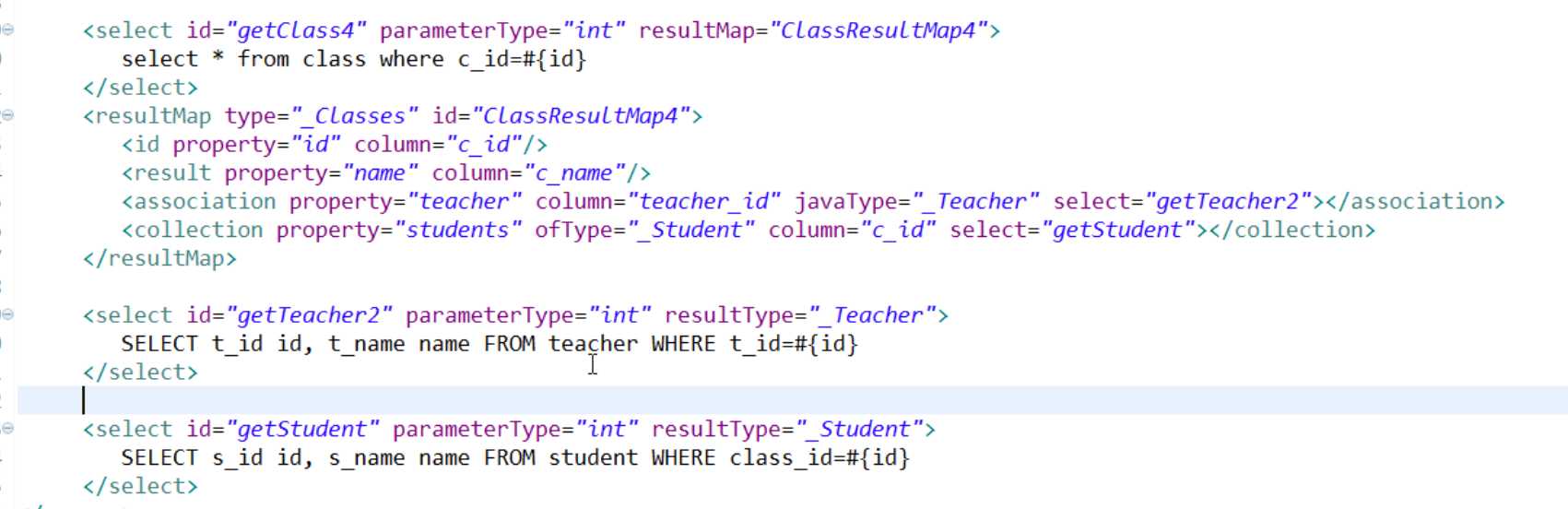
<resultMap id="BaseResultMap" type="com.jhdx.model.entity.User">
<id column="userId" jdbcType="INTEGER" property="userid" />
<result column="userName" jdbcType="VARCHAR" property="username" />
<result column="userPwd" jdbcType="VARCHAR" property="userpwd" />
<collection property="contents" ofType="Content" column="userId" select="selectAllContents"></collection>
</resultMap>
<select id="selectAllContents" resultType="Content" parameterType="java.lang.Integer">
select * from content where userId=#{userId}
</select>
<select id="selectUsers" resultType="map"> select <include refid="userColumns"><property name="alias" value="t1"/></include>, <include refid="userColumns"><property name="alias" value="t2"/></include> from some_table t1 cross join some_table t2 </select>
<sql id="sometable">
${prefix}Table
</sql>
<sql id="someinclude">
from
<include refid="${include_target}"/>
</sql>
<select id="select" resultType="map">
select
field1, field2, field3
<include refid="someinclude">
<property name="prefix" value="Some"/>
<property name="include_target" value="sometable"/>
</include>
</select>
DAO层的函数方法 Public User selectUser(String name,String area); 对应的Mapper.xml <select id="selectUser" resultMap="BaseResultMap"> select * from user_user_t where user_name = #{0} and user_area=#{1} </select>
此方法采用Map传多参数. Dao层的函数方法 Public User selectUser(Map paramMap); 对应的Mapper.xml <select id=" selectUser" resultMap="BaseResultMap"> select * from user_user_t where user_name = #{userName,jdbcType=VARCHAR} and user_area=#{userArea,jdbcType=VARCHAR} </select> Service层调用 Private User xxxSelectUser(){ Map paramMap=new hashMap(); paramMap.put(“userName”,”对应具体的参数值”); paramMap.put(“userArea”,”对应具体的参数值”); User user=xxx. selectUser(paramMap);}
Dao层的函数方法 Public User selectUser(@param(“userName”)Stringname,@parm(“userArea”String area); 对应的Mapper.xml <select id=" selectUser" resultMap="BaseResultMap"> select * from user_user_t where user_name = #{userName,jdbcType=VARCHAR} and user_area=#{userArea,jdbcType=VARCHAR} </select>
1. mybatis中 jdbcType 时间类型
当jdbcType = DATE 时, 只传入了 年月日
jdbcType = TIMESTAMP , 年月日+ 时分秒
使用时, 没有加jdbcType 正常,
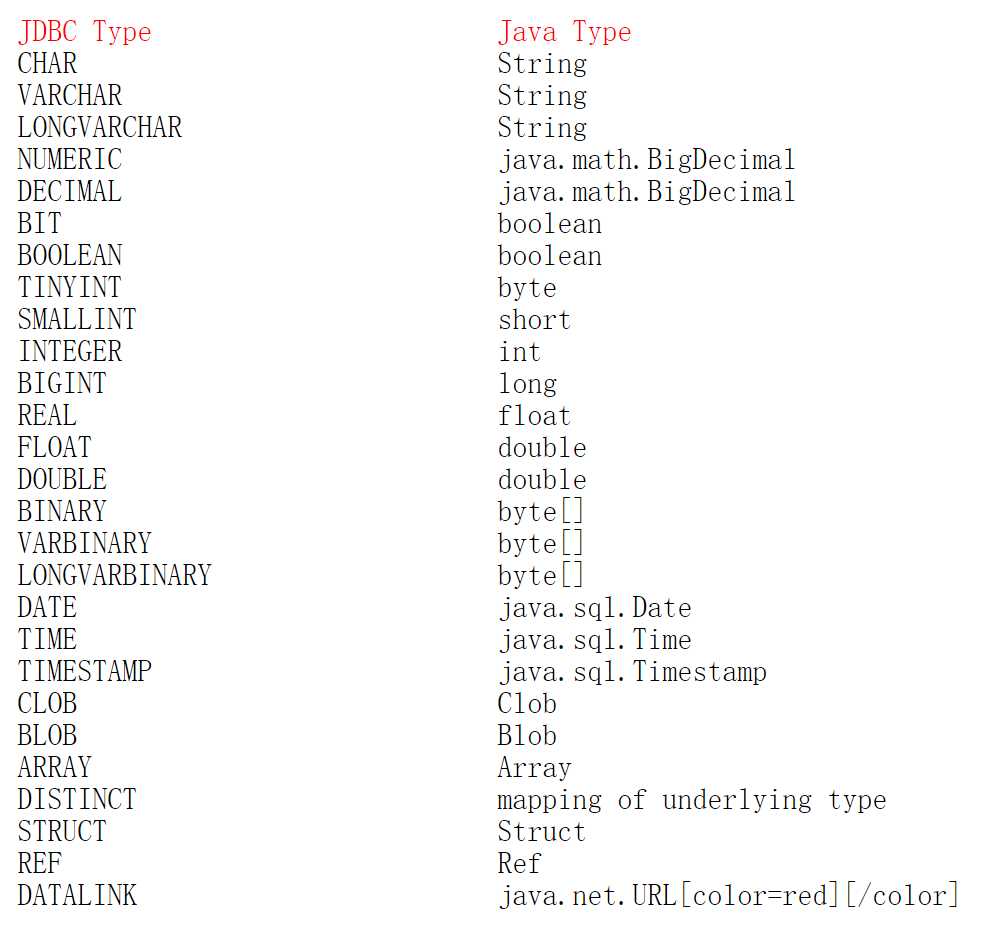
1. #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id".
2. $将传入的数据直接显示生成在sql中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id.
3. #方式能够很大程度防止sql注入。
4.$方式无法防止Sql注入。
5.$方式一般用于传入数据库对象,例如传入表名.
6.一般能用#的就别用$.
标签:get 收集 XML efi 封装 pass 静态 回顾 least
原文地址:http://www.cnblogs.com/invoker-/p/6816445.html
