标签:分割 时间 .net 瓶颈 单节点 cal san 同步 system
这是阅读 http://book.mixu.net/distsys/time.html 的笔记,是该系列的第三章。
为什么时间和顺序很重要呢?为什么我们关系事件A发生在事件B之前?
因为分布式系统要解决的问题是把单机上的问题通过多机来解决。然而传统单机的程序总是假设确定的顺序。对于分布式程序来说,正确性最简单的定义就是,跑起来像一台单机上运行的程序。
具体的定义大家可以去翻离散书。简单地说,全序就是在集合里任何两个元素都可以比较,分出大小。偏序中,某些元素是没办法比较大小的。
在单节点系统中,全序是必然的。因为单机上指令顺序执行。程序运行可预测。这个性质在分布式系统上不是不能实现,但是要付出代价。通信非常昂贵,时间同步困难且脆弱。
时间是顺序的来源。有了时间,我们才可以定义谁先谁后。分秒时只不过为了让人理解恰好出现的记号。
假设时间以同样的速率推进,(这是一个非常强的假设),时间和时间戳有下面解释:
分布式系统中每个节点都有独立的本地时间和时间戳,于是事件的发生有本地的顺序。但是该顺序和其他节点完全独立。给决定分布式系统中的全局顺序造成一定困难。
分布式系统中应该尽量避免假设时间在不同节点上都以同样的速率流逝,否则系统实现会比较脆弱。
那是否可以做到不同节点事件,一致而顺序发生呢?有三个设计(假设)选择。
同步系统模型有全局时钟,部分同步模型有本地时钟,而异步系统模型没有时钟。
全局时钟是全序的源泉。
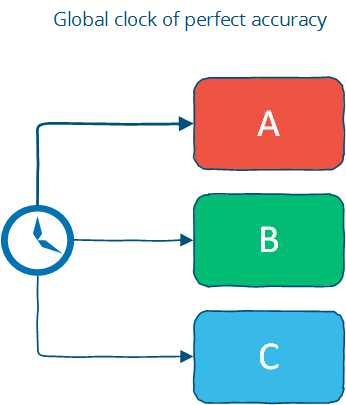
完美的时钟,走时同步,存在于所有节点。这是分布式系统的理想假设。实际上,时钟同步只能保证有限的精度。用户可能随机地改变本机时间,新节点加入,都有可能破坏全局时钟的假设。
当然,现实系统也有做出这个假设的。FB的Cassandra,就是使用时间戳来解决write的冲突的。时间戳较大的write会赢。那么,如果时间不同步,那么旧的write有可能覆盖新的。
假设,可能是目前比较合理的假设,本地有时钟,但是不存在一个全局时钟。两个节点的本地时间戳是不能比较的。
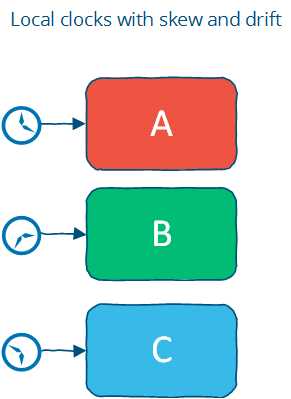
这和真实世界比较接近。事件在本地是可以排序的,但是在多节点分布式系统里不行。不过可以在单机上计算timeout。
完全不使用”时钟”这个概念,取而代之,“逻辑时间”。因为时间戳么,只不过是当前世界状态的一个快照,那我们用一个计数器(Counter),并和节点之间交流就可以做到了。
这样,我们可以在不同的节点之间决定事件顺序。不过有个坏处,因为缺乏时钟,没办法决定timeout。
“没有时钟”的假设的一个实现是“Vector clocks”。后面会详细讲到。Cassandra的cousin Riak 和 Vodemort(LinkedIn)是它的应用。这些系统避免了全局or本地时钟漂移带来的不确定性。
那么事件的顺序的准确性,完全是由通信的延时来决定了。
Lamport时钟和向量时钟通过计数器和通信来决定分布式系统中事件发生顺序的。计数器可以在不同节点之前进行比较。
每个进程都维护一个计时器。
Lamport时钟定义了一个偏序,如果 timestamp(a) < timestamp(b):
第二种情况发生在a和b所在的Partition没有发送通信。
向量时钟是Lamport时钟的一种扩展。它维护大小为N的数列[t1, t2, ....],N为节点数。每个节点都更新自己的时钟。
如下图:
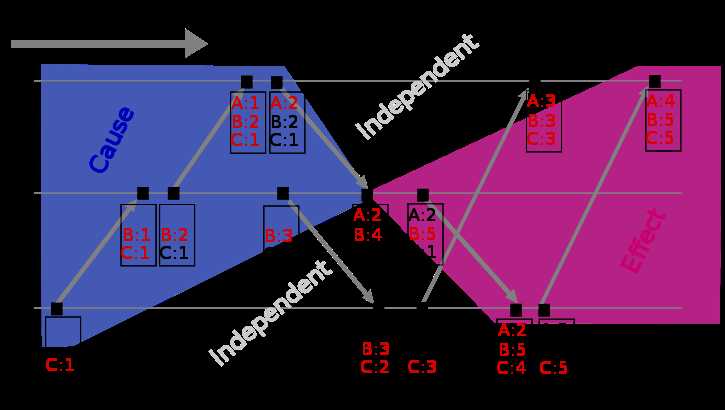
向量时钟潜在的问题是每个节点都有个时钟计数,对于大型的系统来说,向量本身可能变得很大。
对于一个节点上的程序,它怎么知道远程某个节点失效了呢?在缺乏有效准确的全局信息下,我们可以通过一个合理的timeout值来确定。
但是合理的timeout值该怎么确定呢?
失灵检测器可以通过使用心跳消息来实现timeout。节点之间交换心跳消息。如果消息在timeout之前没有收到响应,就可以认为出现失效。
这种检测要么太冲动(把正常的节点算成失效),要么太保守,很长时间才能检测出错误。
论文 http://www.google.com/search?q=Unreliable%20Failure%20Detectors%20for%20Reliable%20Distributed%20Systems 讨论了失灵检测在解决一致性问题中的两大属性: 完整性和精准性。
我们知道在分布式系统中应假设偏序而不是全序。而要承诺全序也是可能的,但是代价非常大。通常的做法是告诉某一个master节点顺序,让它去执行。(GFS的control path做法)。这可能造成性能瓶颈。
时间,顺序和同步真的必要么?看情况。有时候可能你只不过需要最后的结果而不关系中间事件发生的顺序。(Map Reduce)
[分布式系统学习]阅读笔记 Distributed systems for fun and profit 之三 时间和顺序
标签:分割 时间 .net 瓶颈 单节点 cal san 同步 system
原文地址:http://www.cnblogs.com/lichen782/p/6850248.html