标签:display nexon dna 个数 解决 有用 fse 来源 检测
例1,数据点聚类:AP应用到25个二维数据中,使用负平法误差作为相似度 聚类数目不用预先指定

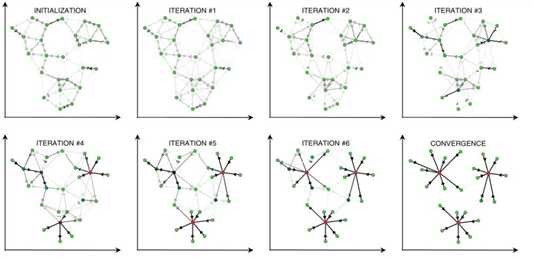
AP的一个优点是聚类数目不用预先指定,而是在消息传递方法中慢慢浮现,取决于输入参考度(preference),这种自动模型的选择,基于先验指定每一个数据点有多合适作为exemplar。
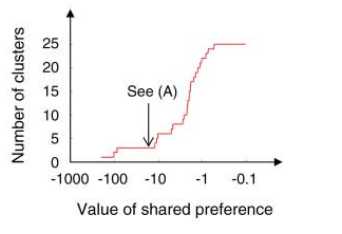
下图表示输入常量参考度对聚类数目的影响,这种关系近乎同样于在精确最小平方误差中的关系。
例2,人脸识别:使用优化标准为均方差,识别900张灰度图像 AP一致的能够实现更低的误差,在时间上花费要少于两个数量级。
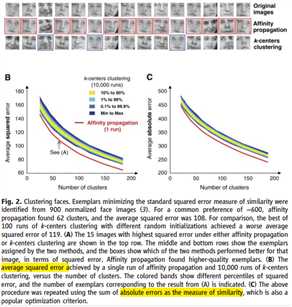
上图2A表示两种方法找到的exemplars,图2B表示一次AP和10000次k-centers的误差分布与簇数目的关系。图2C表示使用另一种优化准则(sum of absolute pixel differences),重复以上做法,一样的,AP实现了更低的误差。
例3:很多工作需要鉴别在稀疏联系的数据中exemplars,大部分相似度不是未知就是负无穷。
看一下AP在这个环境中的应用:聚类假定的外显子来找基因(putative exons to find genes),使用来源于微阵列数据和(4)的报告的稀疏相似度矩阵,75066段DNA(60 bases long)对应于putative exons开采于老鼠染色体的基因组。其翻译水平通过12套样本测量,每一对putative exons(数据点)之间的相似度被计算。相似度的计算基于他们在基因组上的接近程度和通过12组翻译水平的协调程度。考虑putative exons不是exons(introns),我们增加一些额外的人工样本,并且决定每个数据点对这个non-exon exemplar的相似度在整个数据集中使用统计,结果是75067×75067的相似矩阵包含99.73%的相似度为负无穷,对应的远距离的DNA片段不可能是相同基因的一部分,我们在相似度矩阵上使用AP,但是如果s(i,k)=-∞,在i和k之间并不需要交换消息,每一次迭代只需要在很小的数据集(0.27%)的数据对之间交换。
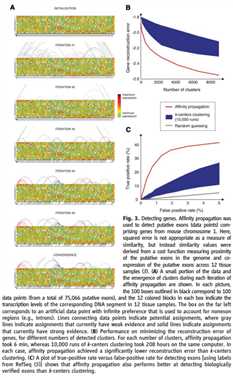
图3A识别基因簇和一些数据分配给nonexon exemplar,图3B是AP和k-centers重构误差的对比,对于每一个簇的数量,AP运行一次耗时6min,k-centers耗时208hours,为了展示这些方法在检测基因片段的性能,图3C画出了在使用RefSEq数据集中提供的标签,TP(ture-positive)与FP(false-positive)之间的关系,AP的结果是实现TP达到39%,k-centers实现最好的记过是17%。作为对比,对于层次聚类算法,能够达到19%,(4)中描述的工程工具,考虑一些其他的工程信息,实现TP到43%。
AP可以操作于非标准化的优化法则,使其适用于考察数据分析可使用不同寻常的相似性度量。适用于
sentence举例:
为了找出一些句子来概括这篇文章的意思,我们把每一个句子看成是单词包,计算句子i和句子k的相似度,基于编码句子i中的单词需要使用句子k中单词的成本,我们发现97%的相似度结果都是不对称的,参考度来调节不同的代表exemplar句子的数量(阻尼因子为0.8),结果如下图所示:

例4,估计商业旅行航空时间
AP可以看做一个搜索能量函数(具体指什么意思呢?),取决于N个隐标签的集合,c1,c2,……cN对应N个数据点,每个标签对应表示该点所属的exemplar。
s(i,ci)是数据点i到它exemplar的相似度,ci=i是一种特例,表明i是其自身的exemplar。所以s(i,ci)是点i的输入参考度。并不是所有的标签都是有效的,当一个配置C有效时,即对于每一个i,如果其他点i’ 选择i作为它的exemplar(ci’=i),那么i一定是一个exemplar,即ci=i,能量的有效配置为![]() 。精确最小化能量从计算上说是很复杂的,因为一个特别的最小化问题的例子是NP难k中值问题(8),然而AP的更新规则对应固定点的递归为了最小化Bethe-energy(9)的近似,AP是能够非常容易的源于因子图中max-sum算法描述标签和能量函数的一个特例。
。精确最小化能量从计算上说是很复杂的,因为一个特别的最小化问题的例子是NP难k中值问题(8),然而AP的更新规则对应固定点的递归为了最小化Bethe-energy(9)的近似,AP是能够非常容易的源于因子图中max-sum算法描述标签和能量函数的一个特例。
AP的一些优势:方法如k中心点聚类、k均值聚类和期望最大化(EM)算法在每一步存储了相对较小的估计簇中心,这些技术的提高是通过大量类开始,然后修剪他们,他们依然依赖随机样本以及难以作出修剪,并且修剪是不能再从中回收,与之对比,通过同时考虑所有点作为候选中心点,并且逐渐识别簇,AP可以避免很多由于不幸的初始化导致的不好的解,作出困难的决策的情况,马尔科夫链蒙特卡洛技术随机搜索好的解,但是不能有AP同时把所有可能的解考虑到的优势。
AP的输入可以是一般非度量相似度,AP提供了一个概念上新的方法,在实践中很有用,利用直觉信息进行更新。
在相当不同的一些学科中,获得的一些优异的结果。
Clustering by Passing Messages Between Data Points(Brendan J.Frey* and Delbert Dueck)例子
标签:display nexon dna 个数 解决 有用 fse 来源 检测
原文地址:http://www.cnblogs.com/betterforever/p/6882764.html