标签:position char break null 分离链接法 hid 关键词 释放 typedef
处理冲突的方法
1.换个位置:开放地址法
2.同一位置的冲突对象组织在一起:链地址法
开放地址法(Open Addressing):
一旦产生了冲突(该地址已有其他元素),就按某种规则去寻找另一空地址
若发生了第i次冲突,试探的下一个地址将增加di, 基本公式:
hi(key) = (h(key)+di) mod TableSize (1≤i<TableSize)
di决定了不同解决冲突方案:线性探测、平方探测、双散列
线性探测:di = i +1 +2 +3
平方探测:di = ±i^2 +1^2, -1^2, +2^2, -2^2
双散列:di = i*h2(key)
线性探测(Linear Probing):
以增量序列1, 2, ..., (TableSize-1)循环试探下一个存储地址
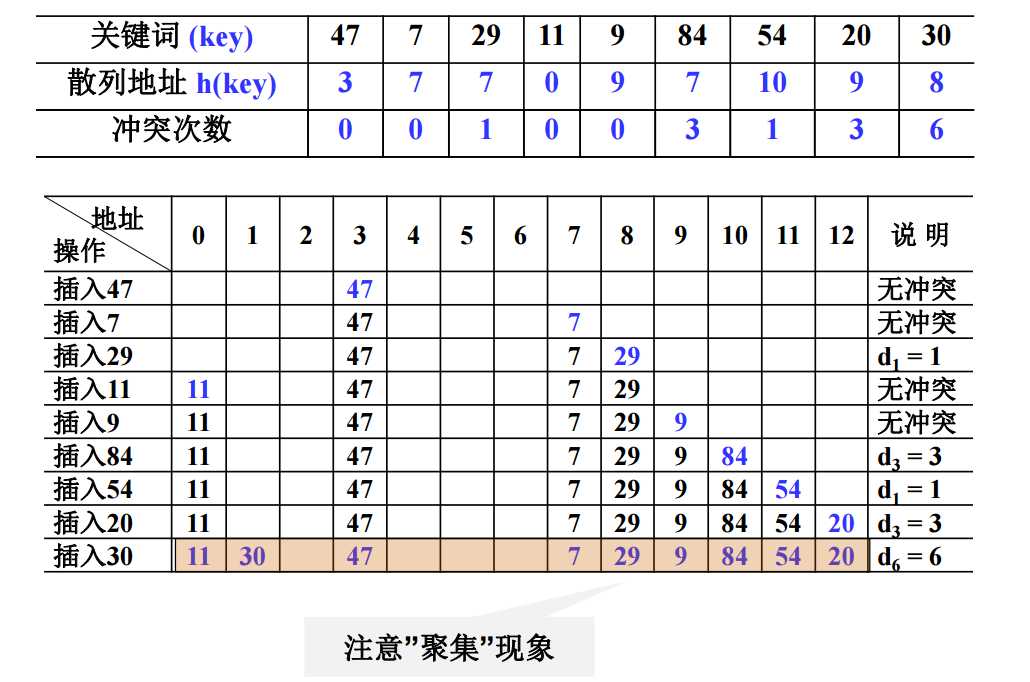
[例] 设关键词序列为 {47,7,29,11,9,84,54,20,30},
散列表表长TableSize =13 (装填因子 α = 9/13 ≈ 0.69);
散列函数为:h(key) = key mod 11。
用线性探测法处理冲突,列出依次插入后的散列表,并估算查找性能
散列表查找性能分析
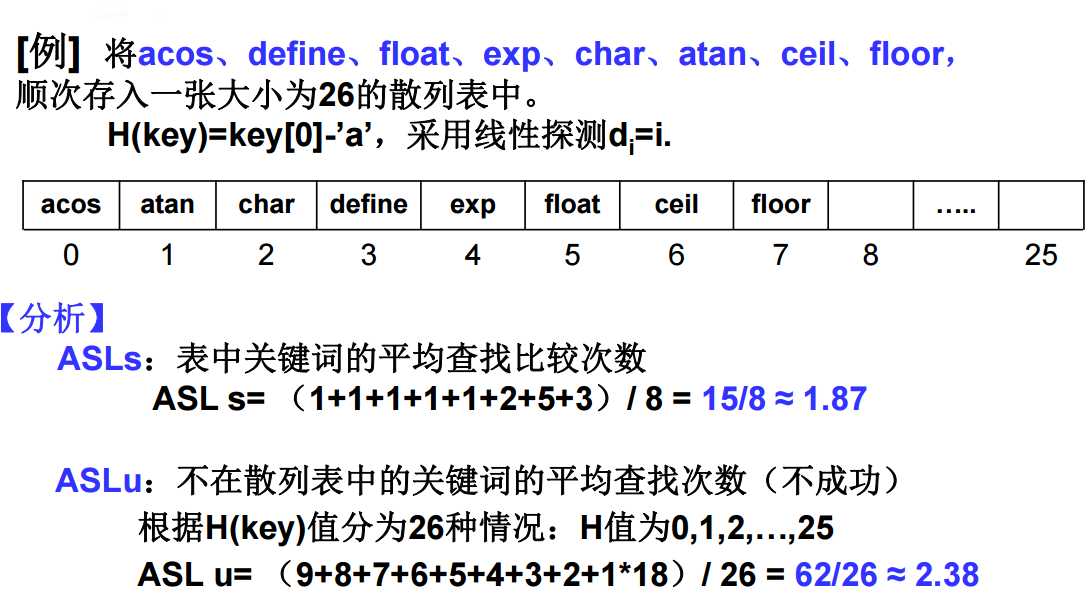
成功平均查找长度(ASLs)
不成功平均查找长度(ASLu)

ASLs:平均查找比较次数(冲突次数加1)
ASL s = (1+7+1+1+2+1+4+2+4)/9 = 23/9 ≈2.56
ASLu:不在散列表中的关键词的平均查找次数(不成功)
一般方法:将不在散列表中的关键词分若干类。 如根据H(key)值分类
ASL u = (3+2+1+2+1+1+1+9+8+7+6)/11 = 41/11 ≈ 3.73
 ,
,
平方探测法(Quadratic Probing) —二次探索
平方探测法:以增量序列1^2, -1^2, 2^2, -2^2, ..., q^2, -q^2
且q<=[TableSize/2]循环试探下一个存储地址
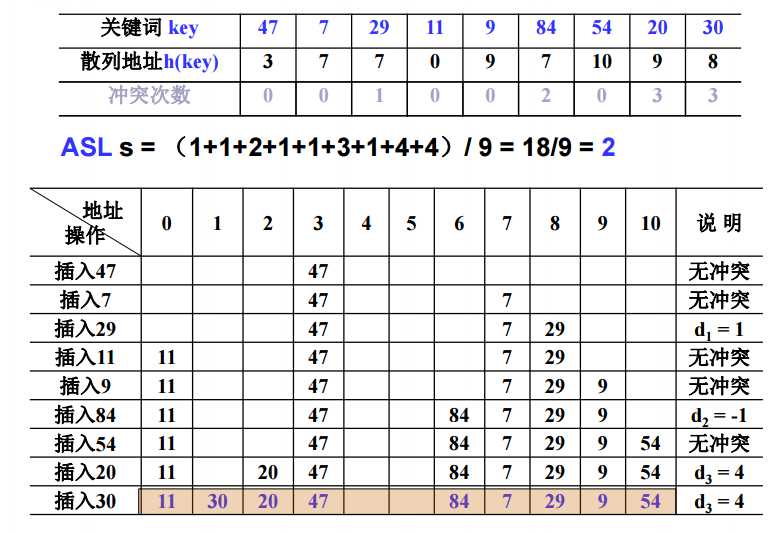
定理:如果散列表长度TableSize是某个4k+3(k是正整数)形式的素数时,平方探测法
就可以探查到整个散列表空间。

#include <stdio.h> #include <math.h> #include <stdlib.h> #define MAXTABLESIZE 100000 //最大散列表长度 typedef int ElementType; //关键词类型 typedef int Index; //散列地址类型 typedef Index Position; //数据所在位置 //散列单元状态类型,分别对应:有合法元素、空单元、有已删除元素 typedef enum{Legitimate, Empty, Deleted} EntryType; typedef struct HashEntry Cell; //散列表单元类型 struct HashEntry { ElementType Data; EntryType info; }; typedef struct TblNode *HashTable; //散列表类型 struct TblNode { int TableSize; Cell *Cells; }; int NextPrime(int N) //返回大于N且不超过MAXTABLESIZE的最小素数 { int i, p = (N % 2) ? N+2 : N+1; //从大于N的下一个奇数开始 while (p <= MAXTABLESIZE) { for (i = (int)sqrt(p); i > 2; i--) //p已经是奇数 if (!(p % i)) break; //p不是素数 if (i == 2) break; //for正常结束,说明p是素数 else p += 2; } return p; } HashTable CreatTable(int TableSize) { HashTable H; int i; H = (HashTable)malloc(sizeof(struct TblNode)); H->TableSize = NextPrime(TableSize); //保证散列表最大长度是素数 H->Cells = (Cell *)malloc(H->TableSize * sizeof(Cell)); //初始化单元状态为空单元 for (i = 0; i < H->TableSize; i++) H->Cells[i].Info = Empty; return H; } Position Find(HashTable H, ElementType Key) { Position CurrentPos, NewPos; int CNum = 0; //记录冲突次数 NewPos = CurrentPos = Hash(Key, H->TableSize); //初始散列位置 while (H->Cells[NewPos].Info != Empty && H->Cells[NewPos].Data != Key) { //字符串类型的关键词需要strcmp函数 //统计一次冲突,判断奇偶性 if (++CNum%2) //奇数次冲突 { NewPos = CurrentPos + (CNum+1)*(CNum+1)/4; //增量为+[(CNum+1)/2]^2 if (NewPos >= H->TableSize) NewPos %= H->TableSize; } else { //偶数次冲突 NewPos = CurrentPos - CNum*CNum/4; //增量为-(CNum/2)^2 while (NewPos < 0) NewPos += H->TableSize; } } return NewPos; //此时NewPos是Key的位置或者是一个空位置(没找到) } bool Insert(HashTable H, ElementType) { Position Pos = Find(H, Key); if (H->Cells[Pos].Info != Legitimate) { H->Cells[Pos].Info = Legitimate; H->Cells[Pos].Data = Key; //字符串类型关键词需要strcpy函数 return true; } else { printf("键值已存在"); return false; } }
3.双散列探测法(Double Hashing)
4.再散列(Rehashing)
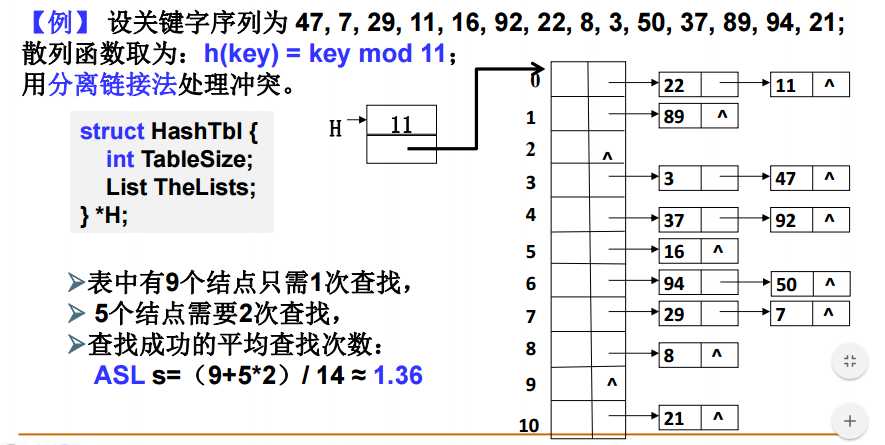
分离链接法(Separate Chaining)
分离链接法:将相应位置上冲突的所有关键词存储在同一个链表中
#include <stdlib.h> #include <string> #define KEYLENTH 15 //关键词字符串的最大长度 typedef char ElementType[KEYLENTH+1]; //关键词类型用字符串 typedef int Index; //散列地址类型 //单链表定义 typedef struct LNode *PtrToLNode; struct LNode { ElementType Data; PtrToLNode Next; }; typedef PtrToLNode Position; typedef PtrToLNode List; //以上是单链表定义 typedef struct TblNode *HashTable; //散列表类型 struct TblNode //散列表结点定义 { int TableSize; List Heads; //指向链表头结点的数组 }; HashTable CreatTable (int TableSize) { HashTable H; int i; H = (HashTable)malloc(sizeof(struct TblNode)); H->TableSize = NextPrime(TableSize); H->Heads = (List)malloc(H->TableSize*sizeof(struct LNode)); //初始化表头结点 for (i = 0; i < H->TableSize; i++) { H->Heads[i].Data[0] = ‘\0‘; H->Heads[i].Next = NULL; } return H; } Position Find(HashTable H, ElementType Key) { Position P; Index Pos; Pos = Hash(Key, H->TableSize); P = H->Heads[Pos].Next; //从该链表的第一个结点 //当未到末尾,并且Key未找到时 while (P && strcmp(P->Data, Key)) P = P->Next; return P; } bool Insert(HashTable H, ElementType Key) { Position P, NewCell; Index Pos; P = Find(H, Key); if (!P) { NewCell = (Position)malloc(sizeof(struct LNode)); strcmp(NewCell->Data, Key); Pos = Hash(Key, H->TableSize); //将NewCell插入为H->Heads[Pos]链表的第一个结点 NewCell->Next = H->Heads[Pos].Next; H->Heads[Pos].Next = NewCell; return true; } else { printf("键值已存在"); return false; } } void DestroyTable(HashTable H) { int i; Position P, Tmp; //释放每个链表的结点 for (i = 0; i < H->TableSize; i++) { P = H->Heads[i].Next; while (P) { Tmp = P->Next; free(P); P = Tmp; } } free(H->Heads); free(H); }
标签:position char break null 分离链接法 hid 关键词 释放 typedef
原文地址:http://www.cnblogs.com/whileskies/p/6886549.html
