标签:设计 img 保存 idt 算法 耦合 list www 集群配置
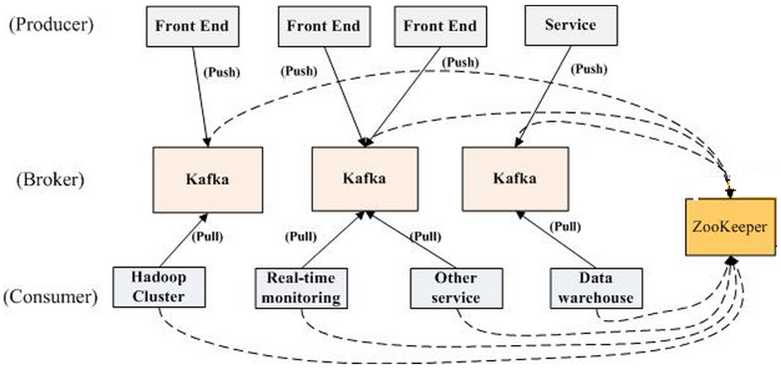
如上图所示,一个典型的kafka集群中包含若干producer(可以是web前端产生的page view,或者是服务器日志,系统CPU、memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干consumer group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息
示例:网络游戏
假设我们正在开发一个在线网络游戏平台,这个平台需要支持大量的在线用户实时操作,玩家在一个虚拟的世界里通过互相协作的方式一起完成每一个任务。由于游戏当中允许玩家互相交易金币、道具,我们必须确保玩家之间的诚信关系,而为了确保玩家之间的诚信及账户安全,我们需要对玩家的 IP 地址进行追踪,当出现一个长期固定 IP 地址忽然之间出现异动情况,我们要能够预警,同时,如果出现玩家所持有的金币、道具出现重大变更的情况,也要能够及时预警。此外,为了让开发组的数据工程师能够测试新的算法,我们要允许这些玩家数据进入到 Hadoop 集群,即加载这些数据到 Hadoop 集群里面。
对于一个实时游戏,我们必须要做到对存储在服务器内存中的数据进行快速处理,这样可以帮助实时地发出预警等各类动作。我们的系统架设拥有多台服务器,内存中的数据包括了每一个在线玩家近 30 次访问的各类记录,包括道具、交易信息等等,并且这些数据跨服务器存储。
我们的服务器拥有两个角色:首先是接受用户发起的动作,例如交易请求,其次是实时地处理用户发起的交易并根据交易信息发起必要的预警动作。为了保证快速、实时地处理数据,我们需要在每一台机器的内存中保留历史交易信息,这意味着我们必须在服务器之间传递数据,即使接收用户请求的这台机器没有该用户的交易信息。为了保证角色的松耦合,我们使用 Kafka 在服务器之间传递信息 (数据)。
Kafka 特性
Kafka 的几个特性非常满足我们的需求:可扩展性、数据分区、低延迟、处理大量不同消费者的能力。这个案例我们可以配置在 Kafka 中为登陆和交易配置同一个主题。由于 Kafka 支持在单一主题内的排序,而不是跨主题的排序,所以我们为了保证用户在交易前使用实际的 IP 地址登陆系统,我们采用了同一个主题来存储登陆信息和交易信息。
当用户登陆或者发起交易动作后,负责接收的服务器立即发事件给 Kafka。这里我们采用用户 id 作为消息的主键,具体事件作为值。这保证了同一个用户的所有的交易信息和登陆信息被发送到 Kafka 分区。每一个事件处理服务被当作一个 Kafka 消费者来运行,所有的消费者被配置到了同一个消费者群组,这样每一台服务器从一些 Kafka 分区读取数据,一个分区的所有数据被送到同一个事件处理服务器 (可以与接收服务器不同)。当事件处理服务器从 Kafka 读取了用户交易信息,它可以把该信息加入到保存在本地内存中的历史信息列表里面,这样可以保证事件处理服务器在本地内存中调用用户的历史信息并做出预警,而不需要额外的网络或磁盘开销。
>为了多线程处理,我们为每一个事件处理服务器或者每一个核创建了一个分区。Kafka 已经在拥有 1 万个分区的集群里测试过。
切换回 Kafka
上面的例子听起来有点绕口:首先从游戏服务器发送信息到 Kafka,然后另一台游戏服务器的消费者从主题中读取该信息并处理它。然而,这样的设计解耦了两个角色并且允许我们管理每一个角色的各种功能。此外,这种方式不会增加负载到 Kafka。测试结果显示,即使 3 个结点组成的集群也可以处理每秒接近百万级的任务,平均每个任务从注册到消费耗时 3 毫秒。
上面例子当发现一个事件可疑后,发送一个预警标志到一个新的 Kafka 主题,同样的有一个消费者服务会读取它,并将数据存入 Hadoop 集群用于进一步的数据分析。
备份机制是Kafka0.8版本的新特性,备份机制的出现大大提高了Kafka集群的可靠性、稳定性。有了备份机制后,Kafka允许集群中的节点挂掉后而不影响整个集群工作。一个备份数量为n的集群允许n-1个节点失败。在所有备份节点中,有一个节点作为lead节点,这个节点保存了其它备份节点列表,并维持各个备份间的状体同步。下面这幅图解释了Kafka的备份机制:
参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-kafka/
http://www.importnew.com/24677.html
kafka备份机制——zk选举leader,leader在broker里负责备份
标签:设计 img 保存 idt 算法 耦合 list www 集群配置
原文地址:http://www.cnblogs.com/bonelee/p/6893286.html

