标签:分享 预测 技术分享 blog 10个 src 随机 输出 评估
1、数据集包含1000个样本,其中500个正例,500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算共有多少种划分方式。
留出法将数据集划分为两个互斥的集合,为了保持数据的一致性,应该保证两个集合中的类别比例相同。故可以用分层采样的方法。训练集包含350个正例与350个反例,测试集包含150个正例与150个反例。
故有500C350*500C350 种划分方式(排列组合)
2、数据集包含100个样本,其中正反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本数较多的类别(训练样本数相同时进行随机猜测),试给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果。
10折交叉检验:由于每次训练样本中正反例数目一样,所以讲结果判断为正反例的概率也是一样的,所以错误率的期望50%。
留一法:如果留下的是正例,训练样本中反例的数目比正例多一个,所以留出的样本会被判断是反例;同理,留出的是反例,则会被判断成正例,所以错误率100%。
3、若学习器A的F1值比学习器B高,试析A的BEP值是否也比B高。
分类器将所有训练样本按自己认为是正例的概率排序,排在越前面分类器更可能将它判断为正例。按顺序逐个把样本标记为正,当查准率与查全率相等时,BEP=查准率=查全率。当然分类器的真实输出是在这个序列中的选择一个位置,前面的标记为正,后面的标记为负,这时的查准率与查全率用来计算F1值。可以看出有同样的BEP值的两个分类器在不同位置截断可能有不同的F1值,所以F1值高不一定BEP值也高。
比如:
| 1/+ | 2/+ | 3/+ | 4/+ | 5/+ | 6/- | 7/- | 8/- | 9/- | 10/- |
|---|---|---|---|---|---|---|---|---|---|
| 1/+ | 2/+ | 3/+ | 4/+ | 6/- | 5/- | 7/- | 8/- | 9/- | 10/- |
| 1/+ | 2/+ | 3/+ | 4/+ | 6/+ | 5/- | 7/- | 8/- | 9/- | 10/- |
第一行是真实的测试样本编号与分类,第二三行是两个分类器对所有样本按为正例可能性的排序,以及判断的结果。显然两个分类器有相同的BEP值,但是他们的F1值一个是0.89,一个是0.8。
4、试述真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)之间的联系。
查全率: 真实正例被预测为正例的比例
真正例率: 真实正例被预测为正例的比例
显然查全率与真正例率是相等的。
查准率:预测为正例的实例中真实正例的比例
假正例率: 真实反例被预测为正例的比例
两者并没有直接的数值关系。
5、试证明AUC=1-lrank
与BEP一样,,学习器先将所有测试样本按预测概率排序,越可能是正的排在越前面。然后依次遍历,每扫描到一个位置,里面如果只有正例,则ROC曲线垂直向上,如果只有反例,曲线水平往右,如果既有正例也有反例,则斜向上。如图所示
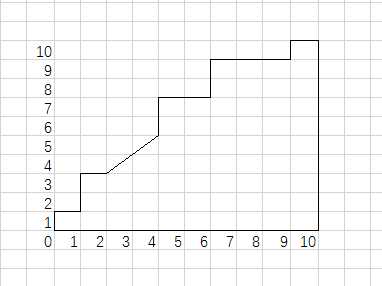
由于TPR与FPR的分母是常数,所以这里按比例扩大了坐标(分别是真实正例和真实反例的数目倍),可以更好看出曲线走势。
可以看出一共有20个测试样本,10个正,10个反。学习器排序的结果是
+,-,(+,+),(+,-),(+,+),(-,-),(+,+),(-,-,-),+,-。其中括号内的样本排在相同的位置。
<(+,+,-,-)与(+,-),(+,-)是同样效果>
标签:分享 预测 技术分享 blog 10个 src 随机 输出 评估
原文地址:http://www.cnblogs.com/sirius-swu/p/6900077.html