标签:wiki 编译器 ati 特定 外观 保护 holo 接受 tween
记得当年在程序员杂志上看出这次访谈,10多年过去了, 这件事儿最近被重提了, 原因是 Kotlin.
1、对Checked Exceptions特性持保留态度
(译者注:在写一段程序时,如果没有用try-catch捕捉异常或者显式的抛出异常,而希望程序自动抛出,一些语言的编译器不会允许编译通过,如Java就是这样。这就是Checked Exceptions最基本的意思。该特性的目的是保证程序的安全性和健壮性。Zee&Snakey(MVP)对此有一段很形象的话,可以参见:
http://www.blogcn.com/user2/zee/main.asp。Bruce Eckel 也有相关的一篇文章(《Does Java need Checked Exceptions》),参见:
http://www.mindview.net/Etc/Discussions/CheckedExceptions)
Bruce Eckel:C#没有Checked Exceptions,你是怎么决定是否在C#中放置这种特性的么?
Anders Hejlsberg:我发现Checked Exceptions在两个方面有比较大的问题:扩展性和版本控制。我知道你也写了一些关于Checked Exceptions的东西,并且倾向于我们对这个问题的看法。
Bruce Eckel:我一直认为Checked Exceptions是非常重要的。
Anders Hejlsberg:是的,老实说,它看起来的确相当重要,这个观点并没有错。我也十分赞许Checked Exceptions特性的美妙。但它某些方面的实现会带来一些问题。例如,从Java中Checked Exceptions的实现途径来看,我认为它在解决一系列既有问题的同时,付出了带来一系列新问题的代价。这样一来,我就搞不清楚Checked Exceptions特性是否可以真的让我们的生活变得更美妙一些。对此你或许有不同看法。
Bruce Eckel:C#设计小组对Checked Exceptions特性是否有过大量的争论?
Anders Hejlsberg:不,在这个问题上,我们有着广泛的共识。C#目前在Checked Exceptions上是保持缄默的。一旦有公认的更好的解决方案,我们会重新考虑,并在适当的地方采用的。我有一个人生信条,那就是——如果你对该问题不具有发言权,也没办法推进其解决进程,那么最好保持沉默和中立,而不应该摆出一个非此即彼的架势。
假设你让一个新手去编一个日历控件,他们通常会这样想:“哦,我会写出世界上最好的日历控件!我要让它有各种各样的日历外观。它有显示部分,有这个,有那个……”他们将所有这些构想都放到控件中去,然后花两天时间写了一个很蹩脚的日历程序。他们想:“在程序的下一个版本中,我将实现更多更好的功能。”
但是,一旦他们开始考虑如何将脑海中那么多抽象的念头具体实现出来时,就会发现他们原来的设计是完全错误的。现在,他们正蹲在一个角落里痛苦万状呢,他们发现必须将原来的设计全盘抛弃。这种情况我不是看到一次两次了。我是一个最低纲领主义者。对于影响全局的问题,在没有实际解决方案前,千万不要将它带入到整个框架中去,否则你将不知道这个框架在将来会变成什么样子。
Bruce Eckel:极限编程(The Extreme Programmers)上说:“用最简单的办法来完成工作。”
Anders Hejlsberg:对呀,爱因斯坦也说过:“尽可能简单行事。”对于Checked Excpetions特性,我最关心的是它可能给程序员带来哪些问题。试想一下,当程序员调用一些新编写的有自己特定的异常抛出句法的API时,程序将变得多么纷乱和冗长。这时候你会明白Checked Exceptions不是在帮助程序员,反而是在添麻烦。正确的做法是,API的设计者告诉你如何去处理异常而不是让你自己想破脑袋。
2、Checked Exceptions的版本相关性
Bill Venners:你提到过Checked Exceptions的扩展性和版本相关性这两个问题。现在能具体解释一下它们的意思么?
Anders Hejlsberg:让我首先谈谈版本相关性,这个问题更容易理解。假设我创建了一个方法foo,并声明它可能抛出A、B、C三个异常。在新版的foo中,我要增加一些功能,由此可能需要抛出异常D。这将产生了一个极具破坏性的改变,因为原来调用此方法时几乎不可能处理过D异常。
??? 也就是说,在新版本中增加抛出的异常时,给用户的代码带来了破坏。在接口中使用方法时也有类似的问题。一个实现特定功能的接口一经发布,就是不可改变的,新功能只能在新版的接口中增加。换句话说,就是只能创建新的接口。在新版本中,你只有两种选择,要么建立一个新的方法foo2,foo2可以抛出更多的异常,要么在新的foo中捕获异常D,并转化为原来的异常A、B或者C。
Bill Venners:但即使在没有Checked Exceptions特性的语言中,(增加新的异常)不是同样会对程序造成破坏么?假如新版foo抛出了需要用户处理的新的异常,难道仅仅因为用户不希望这个异常发生,他写代码时就可以置之不理吗?
Anders Hejlsberg:不,因为在很多情况下,用户根本就不关心(异常)。他们不会处理任何异常。其实消息循环中存在一个最终的异常处理者,它会显示一个对话框提示你程序运行出错。程序员在任何地方都可以使用try finally来保护自己的代码,即使运行时发生了异常,程序依然可以正确运行。对于异常本身的处理,事实上,程序员是不关心的。
很多语言的throws语法(如Java),没必要地强迫你去处理异常,也就是逼迫你搞清楚每一个异常的来源。它们要求你要么捕获声明的异常,要么将它们放入throws语句。程序员为了达到这个要求,做了很多荒谬可笑的事情。例如他们在声明每个方法时,都必须加上修饰语:“throws Exception”。这完全是在搧这个特性的耳光,它不过是要求程序员多作些官样文章,对谁都没有好处。
Bill Venners:如此说来,你认为不要求程序员明确的处理每个异常的做法,在现实中要适用得多了?
Anders Hejlsberg:人们为什么认为(显式的)异常处理非常重要呢?这太可笑了。它根本就不重要。在我印象中,一个写得非常好的程序里,try finally和try catch语句数目大概是10:1。在C#中,也可以使用和类似try finally的using语句(来处理异常)。
Bill Venners:finally到底干了些什么?
Anders Hejlsberg:finally保证你不被异常干扰,但它不直接处理异常。异常处理应该放在别的什么地方。实际上,在任何一个事件驱动的(如现代图形界面)程序中,在主消息循环里,都有一个缺省的异常处理过程,程序员只需要处理那些没被缺省处理的异常。但你必须确保任何异常情况下,原来分配的资源都能被销毁。这样一来,你的程序就是可持续运行的。你肯定不希望写程序时,在100个地方都要处理异常并弹出对话框吧。如果那样的话,你作修改时就要倒大霉了。异常应该集中处理,并在异常来临处保护好你的代码。
3、Checked Exceptions的扩展性
Bill Venners:那么Checked Exceptions的扩展性又是如何呢?
Anders Hejlsberg:扩展性有时候和版本性是相关的。 在一个小程序里,Checked Exceptions显得蛮迷人的。你可以捕捉FileNotFoundException异常并显示出来,是不是很有趣?这在调用单个的API时也挺美妙的。但是在开发大系统时,灾难就降临了。你计划包含4、5个子系统,每个子系统抛出4到10个异常。但是(实际开发时),你每在系统集成的梯子上爬一级,必须被处理的新异常都将呈指数增长。最后,可能每个子系统需要抛出40个异常。将两个子系统集成时,你将必须写80个throw语句。最后,可能你都无法控制了。
很多时候,Checked Exceptions都会激怒程序员,于是程序员就想办法绕过这个特性。他要么在到处都是写“throws Exception”,要么——我都不知道自己看到多少回了——写“try, da da da da da(译者注:意思是飞快的写一段代码), catch curly curly(译者注:即‘{ }’)”,然后说:“哦,我会回头来处理这些空的异常处理语句的。”实际上,理所当然的没有任何人会回头干这些事情。这时候,Checked Exceptions已经造成系统质量的极大下降。
所以,你可能很重视这些问题,但是在我们决定是否将Checked Exceptions的一些机制放入C#时,却是颇费了一番思量的。当然,知道什么异常可能在程序中抛出还是有相当价值的,有一些工具也可以作这方面的检查。我不认为我们可以建立一套足够严格而严谨的规则(来完成异常检查),因为(异常)还可能是编译器的错误引起的呢。但是我认为可以在(程序)分析工具上下些功夫,检测是否有可疑代码,是否有未捕获的异常,并将这些隐藏的漏洞给你指出来。
Java包含两种异常:checked异常和unchecked异常。C#只有unchecked异常。checked和unchecked异常之间的区别是:
有许多支持或者反对二者甚至是否应该使用checked异常的争论。本文将讨论一些常见的观点。开始之前,先澄清一个问题:
Checked和unchecked异常从功能的角度来讲是等价的。可以用checked异常实现的功能必然也可以用unchecked异常实现,反之亦然。
选择checked异常还是unchecked异常是个人习惯或者组织规定问题。并不存在谁比谁强大的问题。
在讨论checked和unchecked异常的优缺点前先看一下代码中如下使用它们。下面是一个抛出checked异常的方法,另一个方法调用了它:
上一节我们已经讨论了checked异常和unchecked异常代码实现上的区别,下面深入分析二者的适用情况(支持和反对二者的观点)。
一些Java书籍(如Suns Java Tutorial)中建议在遇到可恢复的错误时采用checked异常,遇到不可恢复的异常时采用unchecked异常。事实上,大多数应用必须从几乎所有异常(包括NullPointerException,IllegalArgumentException和许多其他unchecked异常)中恢复。执行失败的action/transaction会被取消,但是应用程序必须能继续处理后续的action或transaction。关闭一个应用的唯一合法时机是应用程序启动时。例如,如果配置文件丢失而且应用程序依赖于它,那么这时关闭应用程序是合法的。
我建议的使用策略是:选择checked异常或unchecked异常中的一种使用。混合使用经常导致混乱和不一致。如果你是一个经验丰富的程序员,那么根据自己的需要使用吧。
下面是支持和反对checked/unchecked异常的一些最常见的观点。支持一种类型的exception的观点通常意味着反对另一种(支持checked = 反对unchecked,支持unchecked = 反对checked)。因此,只列出了支持checked异常或unchecked异常的列表。
上述每一个观点都有相反的观点,下面我会详细讨论这些观点。
编译器强制检查,checked异常必须被捕获或者传播,这样就不会忘记处理异常。
当被强制捕获或传播许多异常时,开发人员的效率会受到影响,也可能会只写
Unchecked异常容易忘记处理,由于编译器不强制程序员捕获或传播它(第一条的反面表述)。
强制处理或传播checked异常导致的草率地异常处理非常糟糕。
在近期的一个大型项目中我们决定采用unchecked异常。我在这个项目中获得的经验是:使用unchecked异常时,任何方法都可能抛出异常。因此我不论在写哪一部分代码都时刻注意异常。而不只是声明了checked异常的地方。
此外,许多没有声明任何checked异常的标准的Java API方法会抛出诸如NullPointerException或者InvalidArgumentException之类的unchecked异常。你的应用程序需要处理这些unchecked异常。你可能会说checked异常的存在让我们容易忘记处理unchecked异常,因为unchecked异常没有显式地声明。
沿调用栈向上传播的Checked异常破坏了顶层的方法,因为这些方法必须声明抛出所有它们调用的方法抛出的异常。即,声明的异常聚合了调用栈中所有的方法抛出的异常。例如:
异常声明传播聚合在实际应用程序中很少发生。开发人员时常使用异常包装机制来优化。如下:
我的个人观点是,如果你只是包装异常但并不提供更多信息,那为什么要包装它呢?try-catch块就成了多余的代码,没有做任何有意义的事。只需将ApplicationException,BadUrlException和BadNumberException定义为unchecked异常。下面是上述代码的unchecked版本:
另一种常用于避免异常声明聚集的技术是创建一个应用程序基础异常类。应用程序中抛出的所有异常必须是基础异常类的子类。所有抛出异常的方法只需声明抛出基础异常。比如一个抛出Exception的方法可能抛出Exception的任何子类。如下代码:
我还是支持异常包装:如果应用程序的所有方法都声明抛出ApplicationException(基础异常),为什么不直接将ApplicationException定义为unchecked?这样不但省去了一些try-catch块,也省去了throws语句。
当方法不声明它们会抛出何种异常时,就难以处理它们抛出的异常。如果没有声明,你就不会知道方法会抛出什么样的异常。因此你也就不会知道如何处理它们。当然,如果你能访问源代码,就不存在这个问题,因为你可以从源代码中看出来会抛出何种异常。
在多数情况下,处理异常的措施仅仅是向用户弹出一个错误提示消息,将错误消息写入日志,回滚事务等。无论发生何种异常,你可能会采用相同的处理措施。因此,应用程序通常包含一些集中的通用错误处理代码。如此一来,确切获知抛出了何种异常也就不那么重要了。
Check异常的抛出作为方法接口的一部分,这使得添加或移除早期版本中方法的异常难以实现。
如果方法采用了基础异常机制,就不存在这个问题。如果方法声明抛出基础异常,那么可以方便抛出新异常。唯一的需求是新异常必须是基础异常的子类。
需要再强调一遍的是,让所有可能抛出异常的方法声明抛出相同的基础异常的意义何在?这样能比抛出unchecked异常更好地处理异常吗?
我过去支持checked异常,但是最近我改变了我的观点。Rod Johnson(Spring Framework),Anders Hejlsberg(C#之父),Joshua Bloch(Effective Java,条目41:避免checked异常的不必要的使用)和其他一些朋友使我重新考虑了checked异常的真实价值。最近我们尝试在一个较大的项目中使用unchecked异常,效果还不错。错误处理被集中在了少数几个类中。会有需要本地错误处理的地方,而不是将异常传播给主错误处理代码。但是这种地方不会很多。由于代码中不会到处都是try-catch块,我们的代码变得可读性更好。换句话说,使用unchecked异常比使用checked异常减少了无用的catch-rethrow try-catch块。总之,我建议使用unchecked异常。至少在一个工程中尝试过。我总结了以下原因:
你的项目中使用何种异常由你自己决定。下面是相关的资料。
Anders Hejlsberg on checked vs. unchecked exceptions
http://www.artima.com/intv/handcuffs.html
James Gosling on checked exceptions
http://www.artima.com/intv/solid.html
Bill Venners on Exceptions
http://www.artima.com/interfacedesign/exceptions.html
Bruce Eckel on checked exceptions
http://www.artima.com/intv/typingP.html
Designing with Exceptions (Bill Venners - www.artima.com)
http://www.artima.com/designtechniques/desexcept.html
Effective Java (Joshua Bloch - Addison Wesley 2001)
Daniel Pietraru - in favor of checked exceptions
http://littletutorials.com/2008/05/06/exceptional-java-checked-exceptions-are-priceless-for-everything-else-there-is-the-the-runtimeexception/
英文原文:http://tutorials.jenkov.com/java-exception-handling/checked-or-unchecked-exceptions.html
| Blog Consulting Seminars Calendar Books CD-ROMS Newsletter About FAQ Search |
|
最近 JetBrains 的 Kotlin 语言忽然成了热门话题。国内小编们传言说,Kotlin 取代了 Java,成为了 Android 的“钦定语言”,很多人听了之后热血沸腾。初学者们也开始注意到 Kotlin,问出各种“傻问题”,很“功利”的问题,比如“现在学 Kotlin 是不是太早了一点?” 结果引起一些 Kotlin 老鸟们的鄙视。当然也有人来信,请求我评价 Kotlin。
对于这种评价语言的请求,我一般都不予理睬的。作为一个专业的语言研究者,我的职责不应该是去评价别人设计的语言。然而浏览了 Kotlin 的文档之后,我发现 Kotlin 的设计者误解了一个重要的问题——关于是否需要 checked exception。对于这个话题我已经思考了很久,觉得有必要分享一下我对此的看法,避免误解的传播,所以我还是决定写一篇文章。
可以说我这篇文章针对的是 checked exception,而不是 Kotlin,因为同样的问题也存在于 C# 和其它一些语言。
在进入主题之前,我想先纠正一些人的误解,让他们冷静下来。我们首先应该搞清楚的是,Kotlin 并不是像有些国内媒体传言的那样,要“取代 Java 成为 Android 的官方语言”。准确的说,Kotlin 只是得到了 Android 的“官方支持”,所以你可以用 Kotlin 开发 Android 程序,而不需要绕过很多限制。可以说 Kotlin 跟 Java 一样,都是 Android 的官方语言,但 Kotlin 不会取代 Java,它们是一种并存关系。
这里我不得不批评一下有些国内技术媒体,他们似乎很喜欢片面报道和歪曲夸大事实,把一个平常的事情吹得天翻地覆。如果你看看国外媒体对 Kotlin 的报道,就会发现他们用词的迥然不同:
Google’s Java-centric Android mobile development platform is adding the Kotlin language as an officially supported development language, and will include it in the Android Studio 3.0 IDE.
译文:Google 的以 Java 为核心的 Android 移动开发平台,加入了 Kotlin 作为官方支持的开发语言。它会被包含到 Android Studio 3.0 IDE 里面。
看明白了吗?不是“取代了 Java”,而只是给了大家另一个“选择”。我发现国内的技术小编们似乎很喜欢把“选择”歪曲成“取代”。前段时间这些小编们也有类似的谣传,说斯坦福大学把入门编程课的语言“换成了 JavaScript”,而其实别人只是另外“增加”了一门课,使用 JavaScript 作为主要编程语言,原来以 Java 为主的入门课并没有被去掉。我希望大家在看到此类报道的时候多长个心眼,要分清楚“选择”和“取代”,不要盲目的相信一个事物会立即取代另一个。
Android 显然不可能抛弃 Java 而拥抱 Kotlin。毕竟现有的 Android 代码绝大部分都是 Java 写的,绝大部分程序员都在用 Java。很多人都知道 Java 的好处,所以他们不会愿意换用一个新的,未经时间考验的语言。所以虽然 Kotlin 在 Android 上得到了和 Java 平起平坐的地位,想要程序员们从 Java 转到 Kotlin,却不是一件容易的事情。
我不明白为什么每当出现一个 JVM 的语言,就有人欢呼雀跃的,希望它会取代 Java,似乎这些人跟 Java 有什么深仇大恨。他们已经为很多新语言热血沸腾过了,不是吗?Scala,Clojure…… 一个个都像中国古代的农民起义一样,煽动一批人起来造反,而其实自己都不知道自己在干什么。Kotlin 的主页也把“drastically reduce the amount of boilerplate code”作为了自己的一大特色,仿佛是在暗示大家 Java 有很多“boilerplate code”。
如果你经过理性的分析,就会发现 Java 并不是那么的讨厌。正好相反,Java 的有些设计看起来“繁复多余”,实际上却是经过深思熟虑的决定。Java 的设计者知道有些地方可以省略,却故意把它做成多余的。不理解语言“可用性”的人,往往盲目地以为简短就是好,多写几个字就是丑陋不优雅,其实不是那样的。关于 Java 的良好设计,你可以参考我之前的文章《为 Java 说句公道话》。另外在《对 Rust 语言的分析》里面,我也提到一些容易被误解的语言可用性问题。我希望这些文章对人们有所帮助,避免他们因为偏执而扔掉好的东西。
实际上我很早以前就发现了 Kotlin,看过它的文档,当时并没有引起我很大的兴趣。现在它忽然火了起来,我再次浏览它的新版文档,却发现自己还是会继续使用 Java 或者 C++。虽然我觉得 Kotlin 比起 Java 在某些小地方设计相对优雅,一致性稍好一些,然而我并没有发现它可以让我兴奋到愿意丢掉 Java 的地步。实际上 Kotlin 的好些小改进,我在设计自己语言的时候都已经想到了,然而我并不觉得它们可以成为人们换用一个新语言的理由。
有几个我觉得很重要的,具有突破性的语言特性,Kotlin 并没有实现。另外我还发现一个很重要的 Java 特性,被 Kotlin 的设计者给盲目抛弃了。这就是我今天要讲的主题:checked exception。我不知道这个术语有什么标准的中文翻译,为了避免引起定义混乱,下文我就把它简称为“CE”好了。
先来科普一下 CE 到底是什么吧。Java 要求你必须在函数的类型里面声明它可能抛出的异常。比如,你的函数如果是这样:
void foo(string filename) throws FileNotFoundException
{
if (...)
{
throw new FileNotFoundException();
}
...
}
Java 要求你必须在函数头部写上“throws FileNotFoundException”,否则它就不能编译。这个声明表示函数在某些情况下,会抛出 FileNotFoundException 这个异常。由于编译器看到了这个声明,它会严格检查你对 foo 函数的用法。在调用 foo 的时候,你必须使用 try-catch 处理这个异常,或者在调用的函数头部也声明 “throws FileNotFoundException”,把这个异常传递给上一层调用者。
try
{
foo("blah");
}
catch (FileNotFoundException e)
{
...
}
这种对异常的声明和检查,叫做“checked exception”。很多语言(包括 C++,C#,JavaScript,Python……)都有异常机制,但它们不要求你在函数的类型里面声明可能出现的异常类型,也不使用静态类型系统对异常的处理进行检查和验证。我们说这些语言里面有“exception”,却没有“checked exception”。
理解了 CE 这个概念,下面我们来谈正事:Kotlin 和 C# 对 CE 的误解。
Kotlin 的文档明确的说明,它不支持类似 Java 的 checked exception(CE),指出 CE 的缺点是“繁琐”,并且列举了几个普通程序员心目中“大牛”的文章,想以此来证明为什么 Java 的 CE 是一个错误,为什么它不解决问题,却带来了麻烦。这些人包括了 Bruce Eckel 和 C# 的设计者 Anders Hejlsberg。
很早的时候我就看过 Hejlsberg 的这些言论。他的话看似有道理,然而通过自己编程和设计语言的实际经验,我发现他并没有抓住问题的关键。他的论述里有好几处逻辑错误,一些自相矛盾,还有一些盲目的臆断,所以这些言论并没能说服我。正好相反,实在的项目经验告诉我,CE 是 C# 缺少的一项重要特性,没有了 CE 会带来相当麻烦的后果。在微软写 C# 的时候,我已经深刻体会到了缺少 CE 所带来的困扰。现在我就来讲一下,CE 为什么是很重要的语言特性,然后讲一下为什么 Hejlsberg 对它的批评是站不住脚的。
首先,写 C# 代码时最让我头痛的事情之一,就是 C# 没有 CE。每调用一个函数(不管是标准库函数,第三方库函数,还是队友写的函数,甚至我自己写的函数),我都会疑惑这个函数是否会抛出异常。由于 C# 的函数类型上不需要标记它可能抛出的异常,为了确保一个函数不会抛出异常,你就需要检查这个函数的源代码,以及它调用的那些函数的源代码……
也就是说,你必须检查这个函数的整个“调用树”的代码,才能确信这个函数不会抛出异常。这样的调用树可以是非常大的。说白了,这就是在用人工对代码进行“全局静态分析”,遍历整个调用树。这不但费时费力,看得你眼花缭乱,还容易漏掉出错。显然让人做这种事情是不现实的,所以绝大部分时候,程序员都不能确信这个函数调用不会出现异常。
在这种疑虑的情况下,你就不得不做最坏的打算,你就得把代码写成:
try
{
foo();
}
catch (Exception)
{
...
}
注意到了吗,这也就是你写 Java 代码时,能写出的最糟糕的异常处理代码!因为不知道 foo 函数里面会有什么异常出现,所以你的 catch 语句里面也不知道该做什么。大部分人只能在里面放一条 log,记录异常的发生。这是一种非常糟糕的写法,不但繁复,而且可能掩盖运行时错误。有时候你发现有些语句莫名其妙没有执行,折腾好久才发现是因为某个地方抛出了异常,所以跳到了这种 catch 的地方,然后被忽略了。如果你忘了写 catch (Exception),那么你的代码可能运行了一段时间之后当掉,因为忽然出现一个测试时没出现过的异常……
所以对于 C# 这样没有 CE 的语言,很多时候你必须莫名其妙这样写,这种做法也就是我在微软的 C# 代码里经常看到的。问原作者为什么那里要包一层 try-catch,答曰:“因为之前这地方出现了某种异常,所以加了个 try-catch,然后就忘了当时出现的是什么异常,具体是哪一条语句会出现异常,总之那一块代码会出现异常……” 如此写代码,自己心虚,看的人也糊涂,软件质量又如何保证?
那么 Java 呢?因为 Java 有 CE,所以当你看到一个函数没有声明异常,就可以放心的省掉 try-catch。所以这个 C# 的问题,自然而然就被避免了,你不需要在很多地方疑惑是否需要写 try-catch。Java 编译器的静态类型检查会告诉你,在什么地方必须写 try-catch,或者加上 throws 声明。如果你用 IntelliJ,把光标放到 catch 语句上面,可能抛出那种异常的语句就会被加亮。C# 代码就不可能得到这样的帮助。
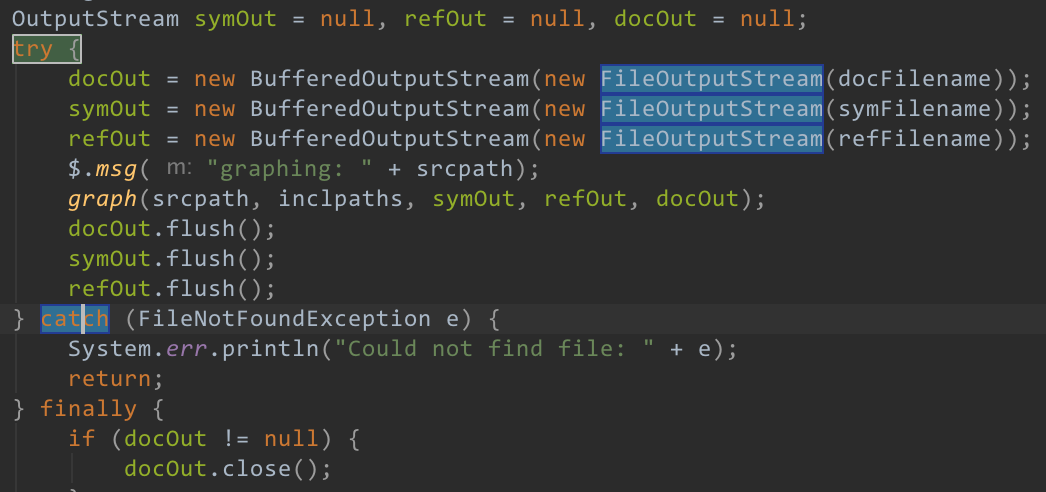
CE 看起来有点费事,似乎只是为了“让编译器开心”,然而这其实是每个程序员必须理解的事情。出错处理并不是 Java 所特有的东西,就算你用 C 语言,也会遇到本质一样的问题。使用任何语言都无法逃脱这个问题,所以必须把它想清楚。在《编程的智慧》一文中,我已经讲述了如何正确的进行出错处理。如果你滥用 CE,当然会有不好的后果,然而如果你使用得当,就会起到事半功倍,提高代码可靠性的效果。
Java 的 CE 其实对应着一种强大的逻辑概念,一种根本性的语言特性,它叫做“union type”。这个特性只存在于 Typed Racket 等一两个不怎么流行的语言里。Union type 也存在于 PySonar 类型推导和 Yin 语言里面。你可以把 Java 的 CE 看成是对 union type 的一种不完美的,丑陋的实现。虽然实现丑陋,写法麻烦,CE 却仍然有着 union type 的基本功能。如果使用得当,union type 不但会让代码的出错处理无懈可击,还可以完美的解决 null 指针等头痛的问题。通过实际使用 Java 的 CE 和 Typed Racket 的 union type 来构建复杂项目,我很确信 CE 的可行性和它带来的好处。
现在我来讲一下为什么 Hejlsberg 对于 CE 的批评是站不住脚的。他的第一个错误,俗话说就是“人笨怪刀钝”。他把程序员对于出错处理的无知,不谨慎和误用,怪罪在 CE 这个无辜的语言特性身上。他的话翻译过来就是:“因为大部分程序员都很傻,没有经过严格的训练,不小心又懒惰,所以没法正确使用 CE。所以这个特性不好,是没用的!”
他的论据里面充满了这样的语言:
注意到了吗,这种给每个函数加上 throws Exception 或者 catch (Exception) 的做法,也就是我在《编程的智慧》里面指出的经典错误做法。要让 CE 可以起到良好的作用,你必须避免这样的用法,你必须知道自己在干什么,必须知道被调用的函数抛出的 exception 是什么含义,必须思考如何正确的处理它们。
另外 CE 就像 union type 一样,如果你不小心分析,不假思索就抛出异常,就会遇到他提到的“抛出 80 多种异常”的情况。出现这种情况往往是因为程序员没有仔细思考,没有处理本来该自己处理的异常,而只是简单的把下层的异常加到自己函数类型里面。在多层调用之后,你就会发现最上面的函数累积起很多种异常,让调用者不知所措,只好传递这些异常,造成恶性循环。终于有人烦得不行,把它改成了“throws Exception”。
我在使用 Typed Racket 的 union type 时也遇到了类似的问题,但只要你严格检查被调用函数的异常,尽量不让它们传播,严格限制自己抛出的异常数目,缩小可能出现的异常范围,这种情况是可以避免的。CE 和 union type 强迫你仔细的思考,理顺这些东西之后,你就会发现代码变得非常缜密而优雅。其实就算你写 C 代码或者 JavaScript,这些问题是同样存在的,只不过这些语言没有强迫你去思考,所以很多时候问题被稀里糊涂掩盖了起来,直到很长时间之后才暴露出来,不可救药。
所以可以说,这些问题来自于程序员自己,而不是 CE 本身。CE 只提供了一种机制,至于程序员怎么使用它,是他们自己的职责。再好的特性被滥用,也会产生糟糕的结果。Hejlsberg 对这些问题使用了站不住脚的理论。如果你假设程序员都是糊里糊涂写代码,那么你可以得出无比惊人的结论:所有用于防止错误的语言特性都是没用的!因为总有人可以懒到不理解这些特性的用法,所以他总是可以滥用它们,绕过它们,写出错误百出的代码,所以静态类型没用,CE 没用,…… 有这些特性的语言都是垃圾,大家都写 PHP 就行了 ;)
Hejlsberg 把这些不理解 CE 用法,懒惰,滥用它的人作为依据,以至于得出 CE 是没用的特性,以至于不把它放到 C# 里面。由于某些人会误用 CE,结果就让真正理解它的人也不能用它。最后所有人都退化到最笨的情况,大家都只好写 catch (Exception)。在 Java 里,至少有少数人知道应该怎么做,在 C# 里,所有人都被迫退化成最差的 Java 程序员 ;)
另外,Hejlsberg 还指出 C# 代码里没有被 catch 的异常,应该可以用“静态分析”检查出来。可以看出来,他并不理解这种静态检查是什么规模的问题。要能用静态分析发现 C# 代码里被忽略的异常,你必须进行“全局分析”,也就是说为了知道一个函数是否会抛出异常,你不能只看这个函数。你必须分析这个函数的代码,它调用的代码,它调用的代码调用的代码…… 所以你需要分析超乎想象的代码量,而且很多时候你没有源代码。所以对于大型的项目,这显然是不现实的。
相比之下,Java 要求你对异常进行 throws 显式声明,实质上把这个全局分析问题分解成了一个个模块化(modular)的小问题。每个函数作者完成其中的一部分,调用它的人完成另外一部分。大家合力帮助编译器,高效的完成静态检查,防止漏掉异常处理,避免不必要的 try-catch。实际上,像 Exceptional 一类的 C# 静态检查工具,会要求你在注释里写出可能抛出的异常,这样它才能发现被忽略的异常。所以 Exceptional 其实重新发明了 Java 的 CE,只不过 throws 声明被写成了一个注释而已。
说到 C#,其实它还有另外一个特别讨厌的设计错误,引起了很多不必要的麻烦。感兴趣的人可以看看我这篇文章:《可恶的 C# IDisposable 接口》。这个问题浪费了整个团队两个月之久的时间。所以我觉得作为 C# 的设计者,Hejlsberg 的思维局限性相当大。我们应该小心的分析和论证这些人的言论,不应该把他们作为权威而盲目接受,以至于让一个优秀的语言特性被误解,不能进入到新的语言里。
所以我对 Kotlin 是什么“结论”呢?我没有结论,这篇文章就像我所有的看法一样,仅供参考。显然 Kotlin 有的地方做得比 Java 好,所以它不会因为没有 CE 而完全失去意义。我不想打击人们对新事物的兴趣,我甚至鼓励有时间的人去试试看。
我知道很多人希望我给他们一个结论,到底是用一个语言,还是不用它,这样他们就不用纠结了,然而我并不想给出一个结论。一来是因为我不想让人感觉我在“控制”他们,如何看待一个东西是他们的自由,是否采用一个东西是他们自己的决定。二来是因为我还没有时间和机会,去用 Kotlin 来做实际的项目。另外,我早就厌倦了试用新的语言,如果一个大众化的语言没有特别讨厌,不可原谅的设计失误,我是不会轻易换用新语言的。我宁愿让其他人做我的小白鼠,去试用这些新语言。到后来我有空了,再去看看他们的成功或者失败经历 :P
所以对我个人而言,我至少现在不会去用 Kotlin,但我并不想让其他人也跟我一样。因为 Java,C++ 和 C 已经能满足我的需求,它们相当稳定,而且我对它们已经很熟悉,所以我为什么要花精力去学一个新的语言,去折腾不成熟的工具,放下我真正感兴趣的算法和数据结构等问题呢?实际上不管我用什么语言写代码,我的头脑里都在用同一个语言构造程序。我写代码的过程,只不过是在为我脑子里的“万能语言”找到对应的表达方式而已。
| Rod Waldhoff‘s Weblog |
|
|
Java‘s checked exceptions were a mistake (and here‘s what I would like to do about it) 1 April 2003
Java‘s checked exceptions were an experiment. While Java borrows most of its try/catch exception handling from C++, the notion of "checked" exceptions, which must either be caught or explicitly thrown, are a Java addition. By and large, this experiment has failed. You won‘t find checked exceptions in Java-influenced languages like Ruby or C#. An idea (the idea?) behind C++ style exception handling is a sound one--it allows one to deal with exceptional conditions at an appropriate, perhaps centralized, point in the call stack, which may be far from where the exceptional condition was encountered. Unrecoverable exceptions are common at very low levels of the code--places where we‘re interacting with I/O and network devices, for example. But these are the very places least likely to know the appropriate response. Do we simply "skip" that action? Try again? Try a different service? Report the problem to the user? To syslog? Allowing the problem to "propagate up" to some caller is a convenient and relatively clean way of dealing with this problem of needing what is essentially out-of-band communication. At first glance, checked exceptions seem like a good idea too. The major risk with unchecked exceptions is that no one will catch them--problems might bubble clear off the stack. Checked exceptions require that callers either deal with the exception or make it known what they are not dealing with. It forces the caller to consider the exceptional case: If you‘re opening a file, be prepared to handle FileNotFound. If you‘re connecting to a server, there may be NoRouteToHost. The problem that‘s introduced here is the impedance between the intention of try/catch exception handling in general (allow exceptional conditions to be handled far from their source) and the implication of checked exceptions in particular (everyone between the thrower and the handler must be aware of the exception that passes through). Even at a second glance, checked exceptions work fairly well. This approach is adequate for self-contained systems, where the distance between the thrower and catcher is small, or for "bottom tier" subsystems, which act as a source for exceptions, but rarely as a sink or pipe (think of basic networking, file I/O, JDBC, etc.). Checked exceptions are pretty much disastrous for the connecting parts of an application‘s architecture however. These middle-level APIs don‘t need or generally want to know about the specific types of failure that might occur at lower levels, and are too general purpose to be able to adequately respond to the exceptional conditions that might occur. Jakarta-Commons Pool provides a good example of this phenomenon. The first release of pool didn‘t allow checked exceptions:
class ObjectPool {
Object borrowObject();
void returnObject(Object obj);
}
But when the generator of pooled objects may throw a checked exception (like Jakarta-Commons DBCP does), extensions of pool were left with two undesirable options--either quietly swallow the checked exception:
class ConnectionFactory implements PoolableObjectFactory {
void makeObject() {
try {
// ...
} catch(SQLException e) {
return null;
}
}
}
or wrap it with some RuntimeException:
class ConnectionFactory implements PoolableObjectFactory {
void makeObject() {
try {
// ...
} catch(SQLException e) {
throw new RuntimeException(e.toString());
}
}
}
(JDK 1.4‘s chained exceptions make this better ( Both options undermine the utility of the exception handling mechanism. The current (cvs HEAD) version of Jakarta-Commons Pool allows for arbitrary checked exceptions:
class ObjectPool {
Object borrowObject() throws Exception;
void returnObject(Object obj) throws Exception;
}
which feels cleaner in some respects, but similarly undermines the utility of the exception handling mechanism. Clients of ObjectPool instances that don‘t throw checked exceptions in practice still need to behave as if they do. Clients of ObjectPool instances that do throw checked exceptions lose any compile-time checking that exceptions of a given type are handled in some meaningful way (i.e., we lose all indications that we expect a specific exception--SQLException--and instead must deal with the most generic case). This situation isn‘t any better than it would be if DriverManager.getConnection() simply threw a RuntimeException, and in some respects, is a bit worse since now I have to litter my code with seemingly extraneous "throws Exception" clauses. The DBCP case is unique, since the client of the ObjectPool is also a SQLException-aware type. (Generally DBCP is a pool masquerading as a Driver or DataSource. Pool plugs-in to DBCP, but it is fully encapsulated by it.) In this scenario, a RuntimeException envelope would be sufficient:
class RuntimeSQLException extends RuntimeException {
RuntimeSQLException(SQLException e) {
exception = e;
}
SQLException getSQLException() {
return exception;
}
private SQLException exception = e;
}
class PoolingDriver {
Connection connect(String url, Properties props) throws SQLException {
try {
return (Connection)(pool.borrowObject());
} catch(RuntimeSQLException e) {
throw e.getSQLException();
}
}
private ObjectPool pool;
}
class ConnectionFactory implements PoolableObjectFactory {
void makeObject() {
try {
// ...
} catch(SQLException e) {
throw new RuntimeSQLException(e);
}
}
}
but this approach only works when there is somebody upstream from ConnectionFactory who knows what to do with a RuntimeSQLException--i.e., when we have control over the code on both sides of the code that the exception passes through. The problem is thornier when the source for the checked exceptions (which creates the "envelope") may be a different component than the one that wants to open the envelope. Jakarta-Commons Functor is a good example of this. The generic functor interfaces don‘t want to (and hopefully don‘t need to) be aware of the various checked exceptions that an implementation of that interface might encounter. At the same time, much of the point of an API like Functor is to allow a client of the functor interfaces to interoperate with disparate implementations of those interfaces, so an approach that requires clients to be aware of every functor implementation‘s RuntimeXXXException subtype (RuntimeIOException, RuntimeSAXException, etc.) isn‘t desirable either. I‘ll suggest that what we need is a single uniform mechanism for tunneling checked Exceptions through APIs that only allow RuntimeException. The exception chaining mechanism in JDK 1.4 supports this, but not in a backwards compatible fashion. Jakarta-Commons Lang has a NestedException type that works in earlier JREs, but not in a forward compatible fashion. But exception chaining is really a different concept. Using chained exceptions alone makes it impossible to distinguish the "chain of exceptions" case from the "tunneling Exception through RuntimeException" case. What we really need is a dedicated adapter type:
class ExceptionRuntimeException extends RuntimeException {
ExceptionRuntimeException(Exception e) {
exception = e;
}
void rethrowException() throws Exception {
throw e;
}
/* ...etc... */
Exception e;
}
Such a type could delegate methods like printStackTrace appropriately, could be used for the exclusive purpose of tunneling checked Exceptions, and is equally valid in JDK 1.3 and JDK 1.4. Placing this type in a small, standalone utility component (of Jakarta-Commons for example), would be a rather minor imposition on clients of components that use it (ExceptionRuntimeException would be a run-time dependency if ever instantiated, but clients who choose to could simply treat at a code level like any other RuntimeException.) Here‘s an example. Jakarta-Commons Functor has a UnaryPredicate type:
interface UnaryPredicate {
boolean test(Object obj);
}
and methods for filtering a Collection according to some UnaryPredicate:
class CollectionAlgorithms {
static Collection select(Iterator iter, UnaryPredicate pred, Collection col) {
while(iter.hasNext()) {
Object obj = iter.next();
if(pred.test(obj)) {
col.add(obj);
}
}
return col;
}
static Collection select(Iterator iter, UnaryPredicate pred) {
return select(iter,pred,new ArrayList());
}
}
which might be used as:
Collection allFiles = getListOfFiles(); Collection directoriesOnly = CollectionAlgorithms.select(allFiles.iterator(),new IsDirectory()); The implementation of the IsDirectory predicate might have need for checked exceptions of course:
/**
* Given a String representing a file URI, determines
* whether the given file is a Directory or not.
* @throws ExceptionRuntimeException for a URISyntaxException
*/
class IsDirectory implements UnaryPredicate {
boolean test(Object obj) {
URI uri;
try {
uri = new URI((String)obj);
} catch(URISyntaxException e) {
throw new ExceptionRuntimeException(e);
}
File file = new File(uri);
return file.isDirectory();
}
}
but using ExceptionRuntimeException allows us to tunnel through the RuntimeException-based functor API without losing information and without adding "throws Exception" to every method in the Functor API. Whenever we‘re ready, we can unwrap the underlying checked Exception, and can easily distinguish that case from other instances of RuntimeException:
boolean flag;
try {
flag = isDirectory.test(someObject);
} catch(ClassCastException e) {
// thrown when someObject is not a String
} catch(NullPointerException e) {
// thrown when someObject is null
} catch(IllegalArgumentException e) {
// thrown when someObject isn‘t a file URI
} catch(ExceptionRuntimeException ere) {
// thrown only if some Exception was thrown
try {
ere.rethrowException();
} catch(URISyntaxException e) {
// thrown when someObject isn‘t a valid URI
} catch(Exception e) {
// other checked exceptions, which we
// could throw as checked or unchecked
// as needed
throw ere;
}
}
I‘ve grown increasingly fond of this approach, and think I‘ll try to put something together in the Jakarta Commons sandbox for it.
By the way, I still think checked exceptions offer some advantage in the cases I enumerated above. Consider Axion‘s AxionException for example. By design, the use of AxionException is fully encapsulated within the Axion API. Clients to Axion‘s external interface should never encounter an AxionException, it‘s only used internally. But similarly, clients to AxionException should generally never encounter an Axion-specific RuntimeException either--Axion‘s external interface should throw SQLException almost exclusively. Making AxionException a checked exception makes this constraint much easier to enforce (the JDBC-tier of Axion can easily tell which methods may result in an AxionException and which methods may not), even if it means that many of Axion‘s internal methods are declared to throw AxionException. Having an ExceptionRuntimeException adapter makes it possible to tunnel AxionExceptions through third-party APIs like Commons Functor. Post script: Thinking it unlikely that I was the first person to have this frustration with checked exceptions I consulted with some of my usual sources. One can find a number of related articles and postings, including Bruce "Thinking in Java" Eckel‘s Does Java need Checked Exceptions? and Checked Exceptions Are Of Dubious Value and Exception Tunneling on Ward‘s Wiki. A somewhat contrary position can be found in Alan Griffith‘s Exceptional Java. Among other guidelines, Alan suggests exception "translation" to wrap or chain exceptions to a predictable, component- or API-specific type. This seems similar to exception tunneling, and perhaps sometimes appropriate, but the thought of having to walk arbitrarily deep exception chains to find the relevant exception gives me pause.
To post comments on this story, please use this blog entry. |
标签:wiki 编译器 ati 特定 外观 保护 holo 接受 tween
原文地址:http://www.cnblogs.com/ioriwellings/p/6905863.html