标签:content sort enter return pattern style new 过程 src
#!/usr/bin env python
# -*- coding:utf-8 -*-
import re
def preprocess(fileName, pattern):
‘‘‘
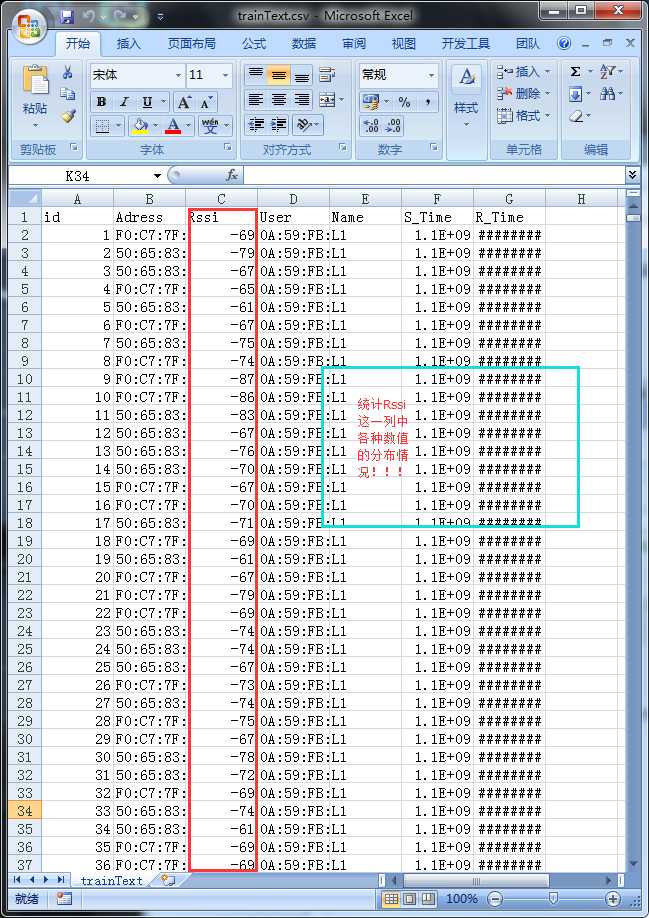
将数据集进行预处理,比如取出RSSI那一列的数据
:param fileName: 接收相对路径
:param pattern: 接收正则表达式的模板
:return: 返回Region of interest数据集
‘‘‘
with open(fileName, ‘r‘, encoding=‘utf-8‘) as f, open(‘laterText.txt‘, ‘w‘, encoding=‘utf-8‘) as f2:
for line in f:
result = re.findall(pattern, line) #‘.*(-\d{2}),‘
if result:
newContent = result[0] + ‘\n‘
f2.write(newContent)
return ‘laterText.txt‘
def sort(fileName):
‘‘‘
将Region of interest数据集内容取出来放进一个列表
再将列表进行排序,然后再对列表的内容进行统计
:param fileName: ROI数据集的路径
:return:
‘‘‘
s1 = []
s_result = []
with open(fileName, ‘r‘, encoding=‘utf-8‘) as f:
for line in f:
line = line.split()[0]
s1.append(line)
s1 = sorted(s1)
for i in s1:
flage = False
for j in s_result:
if i in j:
a, b = j.split(‘:‘)
new_j = a + ‘:‘ + str(int(b) + 1)
s_result.remove(j)
s_result.append(new_j)
flage = True
else:
continue
if flage == False:
new_str = i + ‘:‘ + ‘1‘
s_result.append(new_str)
return s_result
def finalText(list1):
‘‘‘
将统计后的列表写入文件,结果更加直观
:param list1: 统计之后的列表
:return: True
‘‘‘
with open(‘result.txt‘, ‘w‘, encoding=‘utf-8‘) as f2:
for i in list1:
new_line = i + ‘\n‘
f2.write(new_line)
return True
if __name__ == ‘__main__‘:
inputFile = input(‘Enter a file path:‘) # 输入文件的相对路径 例 trainText.csv
pattern = input(‘Enter a re expression:‘) #输入正则表达式 例 .*(-\d{2}),
laterText = preprocess(inputFile, pattern) # laterText接收预处理文件的路径 ‘laterText.txt‘
list1 = sort(laterText) # 将预处理后的文件内容取出,放入列表进行排序并统计列表中各个元素出现的次数,并返回一个列表
if finalText(list1): # 将列表里面的元素放入一个result.txt里面
print(‘统计完毕,结果参考result.txt‘)
-47:1 -48:2 -49:7 -50:7 -51:23 -52:22 -53:33 -54:58 -55:157 -56:81 -57:200 -58:149 -59:214 -60:269 -61:603 -62:256 -63:636 -64:427 -65:525 -66:585 -67:1233 -68:483 -69:1127 -70:654 -71:676 -72:735 -73:1133 -74:432 -75:766 -76:418 -77:411 -78:395 -79:519 -80:184 -81:321 -82:137 -83:146 -84:138 -85:128 -86:110 -87:96 -88:36 -89:38 -90:20 -91:7 -92:11 -93:1
标签:content sort enter return pattern style new 过程 src
原文地址:http://www.cnblogs.com/wuwen19940508/p/6914735.html