标签:auto lob 技术 sci its nbsp height rem img
1 regression 和 classificationn
we call the learning problem a regression prob if th target variable that we‘re trying to predict is continuous; when target variable can only take on a small number of discrete values we call it a classification prob.
2 gradient descent
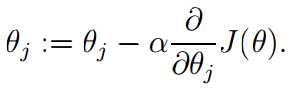
alpha is learning rate. This update is simultaneously performed for all values of j= 0, ..., n
For a single training exmple, this gives the update rule:
(LMS least mean squares update rule or Widrow-Hoff learining rule)
![]()
:= means "set value"
Note that J(theta) is a quadratic function, (a Covex bowl shape), so the gradient descent always converges (only have one global optima with no other local one)
3 Batch gd and stochastic gd (gd = gradient descent)
Batch means you should look at every example in the entire training set on every step
But it turns out that sometimes you will meet really a large training set. by then, you should use another algorsm, that is stochastic gd(随机梯度下降) (also called incremental gd) (it may never "converge" to the minimum, and the parameters theta will keep oscillating around the minimum of J(theta))
4 Matrix derivatives (define and some interesting conclusion)

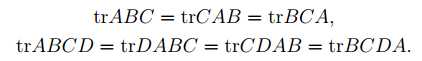
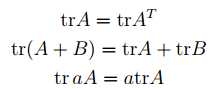
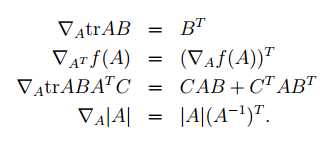
有了上面的引进,就有:
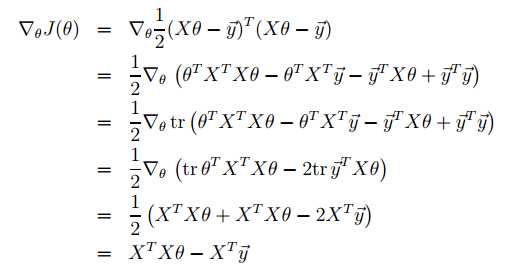
这也是1/2消失的原因。so to minimize J, we set its derivatives to zero, and obtain the normal equations:
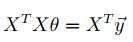
Thus, the value of theta that minimizes J(theta) is given in closed form by the equation
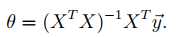
标签:auto lob 技术 sci its nbsp height rem img
原文地址:http://www.cnblogs.com/hans209/p/6920613.html