标签:表示 最小值 cal center 初始化 也有 img 接下来 方程式
一:线性回归:
例:上一节课的房屋大小与价格数据集
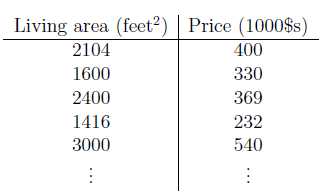
本例中:m:数据个数,x:房屋大小,y:价格
通用符号:
m = 训练样本数
x = 输入变量(特征)
y = 输出变量(目标变量)
(x,y) – 一个样本

对假设进行线性表示 h(x)=θ0+θ1*x
在线性回归的问题上大部分都会有多个输入特征,比如这个例子的输入特征可能也有房间大小,卧室数目两个特征,那么就用x1=房间大小,x2=卧室数目。则方程式就变成了:
h(x)=θ0+θ1*x1+θ2*x2
为了将公式简洁化,假设x0=0,则当有n种特征时,公式为: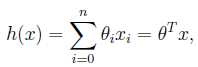 n为特征数目,θ为参数
n为特征数目,θ为参数
选择θ的目的,是使h(x)与y的平方差尽量小。又由于有m个训练样本,需要计算每个样本的平方差,最后为了简化结果乘以1/2,即(最小二乘法):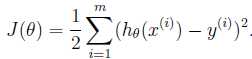 (这里的上标 i 表示第几个样本)(最小二乘法的原理需要看一下,http://blog.csdn.net/lotus___/article/details/20546259)
(这里的上标 i 表示第几个样本)(最小二乘法的原理需要看一下,http://blog.csdn.net/lotus___/article/details/20546259)
最小二乘法的思想, 使得预测数据尽量接近训练集给出的答案,剩下的问题是求该函数的最小值时 的θ值。)
但是各个xn前面的参数是无法确定的,因此可以采用梯度下降的方法来确定Θn的值。根据最小二乘法,得到误差函数J(Θ),目标是计算出各个θ,使得J(θ)最小。
我们要做的就是求:min(J(θ))
求min(J(θ))方法:梯度下降和正规方程组
二 梯度下降
梯度下降是一种搜索算法,基本思想:先给出参数向量一个初始值;不断改变,使得 J(θ)不断缩小。
下面就是计算梯度下降的方法:
1. 随机初始化θ
2. 迭代,如果新的θ能够获得使得J(θ)更小
3. 如果J(θ)能够继续减小,那么回到2,继续执行
梯度下降
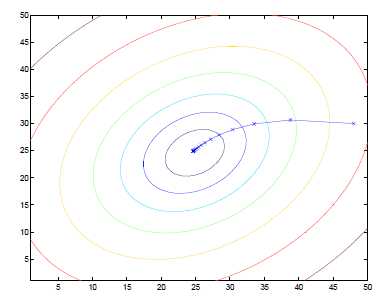
如图所示,水平坐标轴表示θ0和θ1,垂直坐标表示J(θ)
一开始选择0向量作为初始值,假设该三维图为一个三维地表,0向量的点位于一座“山”上。梯度下降的方法是,你环视一周,寻找下降最快的路径,即为梯度的方向,每次下降一小步,再环视四周,继续下降,以此类推。结果到达一个局部最小值,如下图:
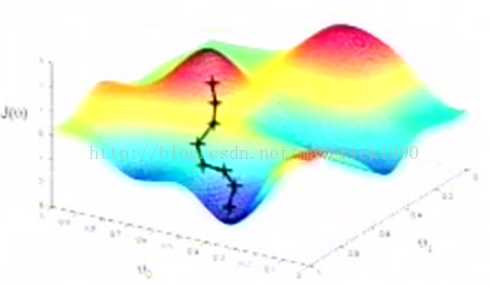
当然,若初始点不同,则结果可能为另一个完全不同的局部最小值,如下:
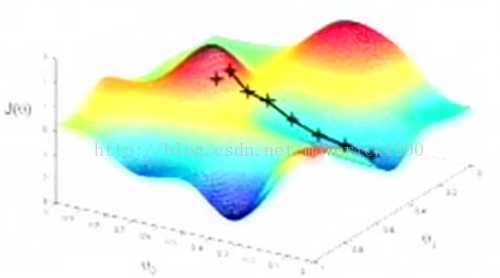
表明梯度下降的结果依赖于参数初始值。
梯度下降算法的数学表示:
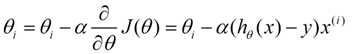 (这些图片θ的下标有的是j,有的是i,这都是各个作者写的方式不同,但是意思都是一样的,就是第几个参数,上标表示第几个样本,下标表示第几个参数)
(这些图片θ的下标有的是j,有的是i,这都是各个作者写的方式不同,但是意思都是一样的,就是第几个参数,上标表示第几个样本,下标表示第几个参数)

每一次将

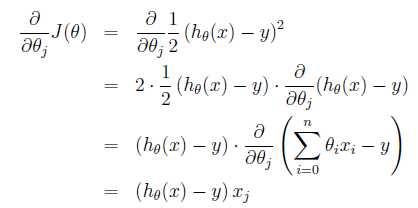 (这里的下标j也是表示第几个参数)
(这里的下标j也是表示第几个参数)

(1) 批梯度下降算法:
上述为处理一个训练样本的公式,将其派生成包含m个训练样本的算法,循环下式直至收敛:
(这里θ的下标表示第i个参数)
复杂度分析:
对于每个
每次迭代(走一步)需要计算n个特征的梯度值,复杂度为O(mn)
一般来说,这种二次函数的
梯度下降性质:接近收敛时,每次的步子会越来越小。其原因是每次减去
检测是否收敛的方法:
1) 检测两次迭代
2) 更常用的方法:检验
批梯度下降算法的优点是能找到局部最优解,但是若训练样本m很大的话,其每次迭代都要计算所有样本的偏导数的和,当训练集合数据量大时效率比较低,需要的时间比较长,于是采用下述另一种梯度下降方法。
(2) 随机梯度下降算法(增量梯度下降算法):
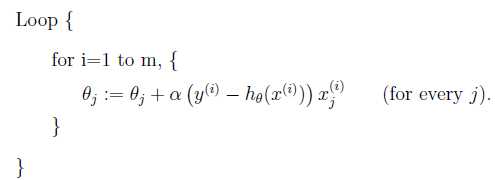
每次计算
即批梯度下降中,走一步为考虑m个样本;随机梯度下降中,走一步只考虑1个样本,也就是一个样本更新一个参数,等n个样本把n个参数一对一都更新了一次后,再换一组样本对参数更新,比如说更新个10次(样本的位置可以换一下,比如第一次样本1对参数θ1进行了更新,下次让 样本1对θ2更新)。
每次迭代复杂度为O(n)。当m个样本用完时,继续循环到第1个样本。
增量梯度下降算法可以减少大训练集收敛的时间(比批量梯度下降快很多),但可能会不精确收敛于最小值而是接近最小值。
上述使用了迭代的方法求最小值,实际上对于这类特定的最小二乘回归问题,或者普通最小二乘问题,存在其他方法给出最小值,接下来这种方法可以给出参数向量的解析表达式,如此一来就不需要迭代求解了。
3、 正规方程组
给定一个函数J,J是一个关于参数数组的函数,定义J的梯度关于的导数,它自己也是一个向量。向量大小为n+1维(从0到n),如下:

所以,梯度下降算法可写成:
J:关于参数数组的函数;
下三角:梯度
更普遍的讲,对于一个函数f,f的功能是将一个m*n的矩阵映射到实数空间上,即:
假设输入为m*n大小的矩阵A,定义f关于矩阵A的导数为:
导数本身也是个矩阵,包含了f关于A的每个元素的偏导数。
如果A是一个方阵,即n*n的矩阵,则将A的迹定义为A的对角元素之和,即:
trA即为tr(A)的简化。迹是一个实数。
一些关于迹运算符和导数的定理:
1) trAB = trBA
2) trABC = trCAB = trBCA
3)
4)
5) 若
6)
有了上述性质,可以开始推导了:
定义矩阵X,称为设计矩阵,包含了训练集中所有输入的矩阵,第i行为第i组输入数据,即:
则由于
又因为对于向量z,有
由上述最后一个性质可得:
通过上述6个性质,推导:
倒数第三行中,运用最后一个性质
将
称为正规方程组
可得:
标签:表示 最小值 cal center 初始化 也有 img 接下来 方程式
原文地址:http://www.cnblogs.com/share-happy-everyday/p/6937554.html













