标签:表示 固定 最小 向量 语义 动态 最简 from apt
统计语言模型(Statistical Language Model)即是用来描述词、语句乃至于整个文档这些不同的语法单元的概率分布的模型,能够用于衡量某句话或者词序列是否符合所处语言环境下人们日常的行文说话方式。统计语言模型对于复杂的大规模自然语言处理应用有着非常重要的价值,它能够有助于提取出自然语言中的内在规律从而提高语音识别、机器翻译、文档分类、光学字符识别等自然语言应用的表现。好的统计语言模型需要依赖大量的训练数据,在上世纪七八十年代,基本上模型的表现优劣往往会取决于该领域数据的丰富程度。IBM 曾进行过一次信息检索评测,发现二元语法模型(Bi-gram)需要数以亿计的词汇才能达到最优表现,而三元语法模型(TriGram)则需要数十亿级别的词汇才能达成饱和。本世纪初,最流行的统计语言模型当属 N-gram,其属于典型的基于稀疏表示(Sparse Representation)的语言模型;近年来随着深度学习的爆发与崛起,以词向量(WordEmbedding)为代表的分布式表示(Distributed Representation)的语言模型取得了更好的效果,并且深刻地影响了自然语言处理领域的其他模型与应用的变革。除此之外,Ronald Rosenfeld[7] 还提到了基于决策树的语言模型(Decision Tree Models)、最大熵模型以及自适应语言模型(Adaptive Models)等。
统计语言模型可以用来表述词汇序列的统计特性,譬如学习序列中单词的联合分布概率函数。如果我们用w1w1 到 wtwt 依次表示这句话中的各个词,那么该句式的出现概率可以简单表示为:
P(w1,...,wt)=∏i=1tP(wi|w1,...,wi?1)=∏i=1tP(wi|Context)P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt?1)(1)(1)P(w1,...,wt)=∏i=1tP(wi|w1,...,wi?1)=∏i=1tP(wi|Context)P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt?1)
统计语言模型训练目标也可以是采用极大似然估计来求取最大化的对数似然,公式为1T∑Tt=1∑?c≤j≤c,j≠0logp(wt+j|wt)1T∑t=1T∑?c≤j≤c,j≠0logp(wt+j|wt)。其中cc是训练上下文的大小。譬如cc取值为
5 的情况下,一次就拿 5
个连续的词语进行训练。一般来说cc越大,效果越好,但是花费的时间也会越多。p(wt+j|wt)p(wt+j|wt)表示wtwt条件下出现wt+jwt+j的概率。常见的对于某个语言模型度量的标准即是其困惑度(Perplexity),需要注意的是这里的困惑度与信息论中的困惑度并不是相同的含义。这里的困惑度定义公式参考Stolcke[11],为exp(?logP(wt)/|w?
|)exp(?logP(wt)/|w→|),即是1/P(wt|wt?11)1/P(wt|w1t?1)的几何平均数。最小化困惑度的值即是最大化每个单词的概率,不过困惑度的值严重依赖于词表以及具体使用的单词,因此其常常被用作评判其他因素相同的两个系统而不是通用的绝对性的度量参考。
参照上文的描述,在统计学语言模型中我们致力于计算某个词序列E=wT1E=w1T的出现概率,可以形式化表示为:
P(E)=P(|E|=T,wT1)(2)(2)P(E)=P(|E|=T,w1T)
上式中我们求取概率的目标词序列EE的长度为TT,序列中第一个词为w1w1,第二个词为w2w2,等等,直到最后一个词为wTwT。上式非常直观易懂,不过在真实环境下却是不可行的,因为序列的长度TT是未知的,并且词表中词的组合方式也是非常庞大的数目,无法直接求得。为了寻找实际可行的简化模型,我们可以将整个词序列的联合概率复写为单个词或者单个词对的概率连乘。即上述公式可以复写为P(w1,w2,w3)=P(w1)P(w2|w1)P(w3|w1,w2)P(w1,w2,w3)=P(w1)P(w2|w1)P(w3|w1,w2),推导到通用词序列,我们可以得到如下形式化表示:
P(E)=∏t=1T+1P(wt|wt?11)(3)(3)P(E)=∏t=1T+1P(wt|w1t?1)
此时我们已经将整个词序列的联合概率分解为近似地求
P(wt|w1,w2,…,wt?1)P(wt|w1,w2,…,wt?1)。而这里要讨论的 N-gram 模型就是用
P(wt|wt?n+1,…,wt?1)P(wt|wt?n+1,…,wt?1)
近似表示前者。根据NN的取值不同我们又可以分为一元语言模型(Uni-gram)、二元语言模型(Bi-gram)、三元语言模型(Tri-gram)等等类推。该模型在中文中被称为汉语语言模型(CLM,
Chinese Language
Model),即在需要把代表字母或笔画的数字,或连续无空格的拼音、笔画,转换成汉字串(即句子)时,利用上下文中相邻词间的搭配信息,计算出最大概率的句子;而不需要用户手动选择,避开了许多汉字对应一个相同的拼音(或笔画串、数字串)的重码问题。
一元语言模型又称为上下文无关语言模型,是一种简单易实现但实际应用价值有限的统计语言模型。该模型不考虑该词所对应的上下文环境,仅考虑当前词本身的概率,即是 N-gram 模型中当N=1N=1的特殊情形。
p(wt|Context)=p(wt)=NwtN(4)(4)p(wt|Context)=p(wt)=NwtN
N-gram 语言模型也存在一些问题,这种模型无法建模出词之间的相似度,有时候两个具有某种相似性的词,如果一个词经常出现在某段词之后,那么也许另一个词出现在这段词后面的概率也比较大。比如“白色的汽车”经常出现,那完全可以认为“白色的轿车”也可能经常出现。N-gram 语言模型无法建模更远的关系,语料的不足使得无法训练更高阶的语言模型。大部分研究或工作都是使用 Tri-gram,就算使用高阶的模型,其统计 到的概率可信度就大打折扣,还有一些比较小的问题采用 Bi-gram。训练语料里面有些 n 元组没有出现过,其对应的条件概率就是 0,导致计算一整句话的概率为 0。最简单的计算词出现概率的方法就是在准备好的训练集中计算固定长度的词序列的出现次数,然后除以其所在上下文的次数;譬如以 Bi-gram 为例,我们有下面三条训练数据:
我们可以推导出词 am, study 分别相对于 i 的后验概率:
p(w2=am|w1=i)=w1=i,w2=amc(w1=1)=12=0.5p(w2=study|w1=i)=w1=i,w2=studyc(w1=1)=12=0.5(5)(5)p(w2=am|w1=i)=w1=i,w2=amc(w1=1)=12=0.5p(w2=study|w1=i)=w1=i,w2=studyc(w1=1)=12=0.5
上述的计算过程可以推导为如下的泛化公式:
PML(wt|wt?11)=cprefix(wt1)cprefix(wt?11)(6)(6)PML(wt|w1t?1)=cprefix(w1t)cprefix(w1t?1)
这里cprefix(?)cprefix(?)表示指定字符串在训练集中出现的次数,这种方法也就是所谓的最大似然估计(Maximum
Likelihood Estimation);该方法十分简单易用,同时还能保证较好地利用训练集中的统计特性。根据这个方法我们同样可以得出
Tri-gram 模型似然计算公式如下:
P(wt|wt?2,wt?1)=count(wt?2wt?1wt)count(wt?2wt?1)(7)(7)P(wt|wt?2,wt?1)=count(wt?2wt?1wt)count(wt?2wt?1)
我们将 N-gram 模型中的参数记作θθ,其包含了给定前n?1n?1个词时第nn个词出现的概率,形式化表示为:
θwtt?n+1=PML(wt|wt?1t?n+1)=c(wtt?n+1)c(wt?1t?n+1)(8)(8)θwt?n+1t=PML(wt|wt?n+1t?1)=c(wt?n+1t)c(wt?n+1t?1)
朴素的
N-gram 模型中对于训练集中尚未出现过的词序列会默认其概率为零
,因为我们的模型是多个词概率的连乘,最终会导致整个句式的概率为零。我们可以通过所谓的平滑技巧来解决这个问题,即组合对于不同的NN取值来计算平均概率。譬如我们可以组合
Uni-gram 模型与 Bi-gram 模型:
P(wt|wt?1)=(1?α)PML(wt|wt?1)+αPML(wt)(9)(9)P(wt|wt?1)=(1?α)PML(wt|wt?1)+αPML(wt)
其中αα表示分配给
Uni-gram
求得的概率的比重,如果我们设置了α>0α>0,那么词表中的任何词都会被赋予一定的概率。这种方法即是所谓的插入平滑(Interpolation),被应用在了很多低频稀疏的模型中以保证其鲁棒性。当然,我们也可以引入更多的NN的不同的取值,整个组合概率递归定义如下:
P(wt|wt?1t?m+1)=(1?αm)PML(wt|wt?1t?m+1)+αmP(wt|wt?1t?m+2)(10)(10)P(wt|wt?m+1t?1)=(1?αm)PML(wt|wt?m+1t?1)+αmP(wt|wt?m+2t?1)
[Stanley
et al., 1996] 中还介绍了很多其他复杂但精致的平滑方法,譬如基于上下文的平滑因子计算(Context-dependent
Smoothing
Coefficients),其并没有设置固定的αα值,而是动态地设置为αwt?1t?m+1αwt?m+1t?1。这就保证了模型能够在有较多的训练样例时将更多的比重分配给高阶的
N-gram 模型,而在训练样例较少时将更多的比重分配给低阶的 N-gram 模型。目前公认的使用最为广泛也最有效的平滑方式也是
[Stanley et al., 1996] 中提出的 Modified Kneser-Ney smoothing( MKN )
模型,其综合使用了上下文平滑因子计算、打折以及低阶分布修正等手段来保证较准确地概率估计。
顾名思义,神经网络语言模型(Neural
Network Language
Model)即是基于神经网络的语言模型,其能够利用神经网络在非线性拟合方面的能力推导出词汇或者文本的分布式表示。在神经网络语言模型中某个单词的分布式表示会被看做激活神经元的向量空间,其区别于所谓的局部表示,即每次仅有一个神经元被激活。标准的神经网络语言模型架构如下图所示:
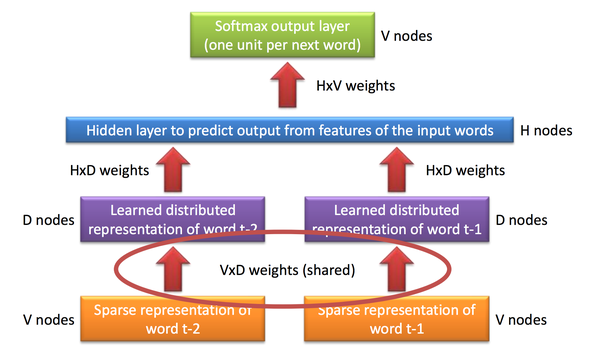
神经网络语言模型中最著名的当属 Bengio[10] 中提出的概率前馈神经网络语言模型(Probabilistic Feedforward Neural Network Language Model),它包含了输入(Input)、投影(Projection)、隐藏(Hidden)以及输出(Output)这四层。在输入层中,会从VV个单词中挑选出NN个单词以下标进行编码,其中VV是整个词表的大小。然后输入层会通过N×DN×D这个共享的投影矩阵投射到投影层PP;由于同一时刻仅有NN个输入值处于激活状态,因此这个计算压力还不是很大。NNLM 模型真正的计算压力在于投影层与隐层之间的转换,譬如我们选定N=10N=10,那么投影层PP的维度在 500 到 2000 之间,而隐层HH的维度在于500500到10001000之间。同时,隐层HH还负责计算词表中所有单词的概率分布,因此输出层的维度也是VV。综上所述,整个模型的训练复杂度为:
Q=N×D+N×D×H+H×VQ=N×D+N×D×H+H×V
其训练集为某个巨大但固定的词汇集合VV 中的单词序列w1...wtw1...wt;其目标函数为学习到一个好的模型f(wt,wt?1,…,wt?n+2,wt?n+1)=p(wt|wt?11)f(wt,wt?1,…,wt?n+2,wt?n+1)=p(wt|w1t?1),约束为f(wt,wt?1,…,wt?n+2,wt?n+1)>0f(wt,wt?1,…,wt?n+2,wt?n+1)>0并且Σ|V|i=1f(i,wt?1,…,wt?n+2,wt?n+1)=1Σi=1|V|f(i,wt?1,…,wt?n+2,wt?n+1)=1。每个输入词都被映射为一个向量,该映射用CC表示,所以C(wt?1)C(wt?1)即为wt?1wt?1的词向量。定义gg为一个前馈或者递归神经网络,其输出是一个向量,向量中的第ii个元素表示概率p(wt=i|wt?11)p(wt=i|w1t?1)。训练的目标依然是最大似然加正则项,即:
MaxLikelihood=max1T∑tlogf(wt,wt?1,…,wt?n+2,wt?n+1;θ)+R(θ)MaxLikelihood=max1T∑tlogf(wt,wt?1,…,wt?n+2,wt?n+1;θ)+R(θ)
其中θθ为参数,R(θ)R(θ)为正则项,输出层采用sofamax函数:
p(wt|wt?1,…,wt?n+2,wt?n+1)=eywt∑ieyip(wt|wt?1,…,wt?n+2,wt?n+1)=eywt∑ieyi
其中yiyi是每个输出词ii的未归一化loglog概率,计算公式为y=b+Wx+Utanh(d+Hx)y=b+Wx+Utanh(d+Hx)。其中b,W,U,d,Hb,W,U,d,H都是参数,xx为输入,需要注意的是,一般的神经网络输入是不需要优化,而在这里,x=(C(wt?1),C(wt?2),…,C(wt?n+1))x=(C(wt?1),C(wt?2),…,C(wt?n+1)),也是需要优化的参数。在图中,如果下层原始输入xx不直接连到输出的话,可以令b=0b=0,W=0W=0。如果采用随机梯度算法的话,梯度的更新规则为:
θ+??logp(wt|wt?1,…,wt?n+2,wt?n+1)?θ→θθ+??logp(wt|wt?1,…,wt?n+2,wt?n+1)?θ→θ
其中??为学习速率,需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层xx也是参数(存在CC中),也是需要优化的。优化结束之后,词向量有了,语言模型也有了。这个
Softmax 模型使得概率取值为(0,1),因此不会出现概率为0的情况,也就是自带平滑,无需传统 N-gram
模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 N-gram
算法要好10%到20%。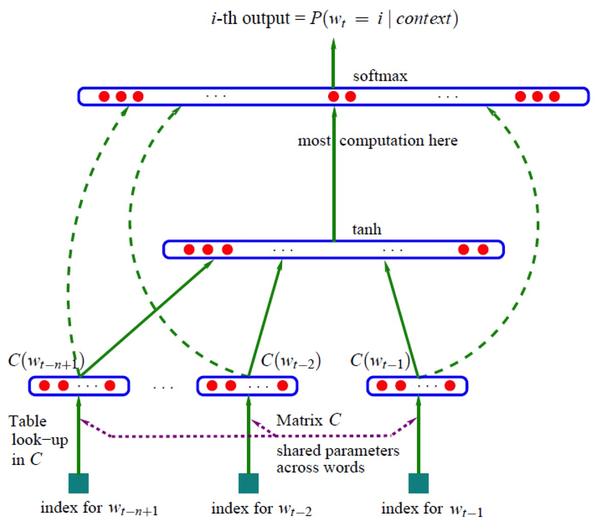
好的语言模型应当至少捕获自然语言的两个特征:语法特性与语义特性。为了保证语法的正确性,我们往往只需要考虑生成词的前置上下文;这也就意味着语法特性往往是属于局部特性。而语义的一致性则复杂了许多,我们需要考虑大量的乃至于整个文档语料集的上下文信息来获取正确的全局语义。神经网络语言模型相较于经典的 N-gram 模型具有更强大的表现力与更好的泛化能力,不过传统的 N-gram 语言模型与 [Bengio et al., 2003] 中提出的神经网络语言模型都不能有效地捕获全局语义信息。为了解决这个问题,[Mikolov et al., 2010; 2011] 中提出的基于循环神经网络(Recurrent Neural Network, RNN)的语言模型使用了隐状态来记录词序的历史信息,其能够捕获语言中的长程依赖。在自然语言中,往往在句式中相隔较远的两个词却具备一定的语法与语义关联,譬如He doesn‘t have very much confidence in himself 与 She doesn‘t have very much confidence in herself 这两句话中的<He, himself>与<She, herself>这两个词对,尽管句子中间的词可能会发生变化,但是这两种词对中两个词之间的关联却是固定的。这种依赖也不仅仅出现在英语中,在汉语、俄罗斯语中也都存在有大量此类型的词对组合。而另一种长期依赖(Long-term Dependencies)的典型就是所谓的选择限制(Selectional Preferences);简而言之,选择限制主要基于已知的某人会去做某事这样的信息。譬如我要用叉子吃沙拉与我要和我的朋友一起吃沙拉这两句话中,叉子指代的是某种工具,而我的朋友则是伴侣的意思。如果有人说我要用双肩背包来吃沙拉就觉得很奇怪了,双肩背包并不是工具也不是伴侣;如果我们破坏了这种选择限制就会生成大量的无意义句子。最后,某个句式或者文档往往都会归属于某个主题下,如果我们在某个技术主题的文档中突然发现了某个关于体育的句子,肯定会觉得很奇怪,这也就是所谓的破坏了主题一致性。
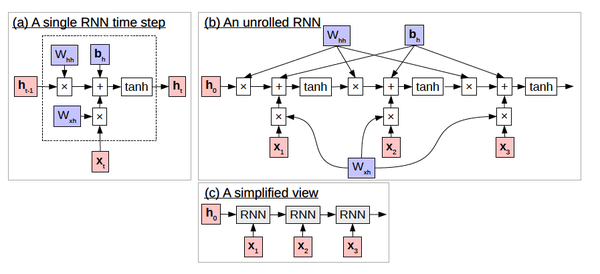
[Eriguchi et al., 2016] 中介绍的循环神经网络在机器翻译上的应用就很值得借鉴,它能够有效地处理这种所谓长期依赖的问题。它的思想精髓在于计算新的隐状态h? h→时引入某个之前的隐状态ht?1→ht?1→,形式化表述如下:
h? t={tanh(Wxhx? t+Whhh? t?1+b? h),0,t ≥1,otherwises(11)(11)h→t={tanh(Wxhx→t+Whhh→t?1+b→h),t ≥1,0,otherwises
我们可以看出,在t≥1t≥1时其与标准神经网络中隐层计算公式的区别在于多了一个连接Whhh?
t?1Whhh→t?1,该连接源于前一个时间点的隐状态。在对于 RNN
有了基本的了解之后,我们就可以将其直接引入语言模型的构建中,即对于上文讨论的神经网络语言模型添加新的循环连接:
m?
t=M?,wt?1h? t={tanh(Wxhx? t+Whhh? t?1+b? h),0,t ≥1,otherwisesp?
t=softmax(Whsh? t+bs)(12)(12)m→t=M?,wt?1h→t={tanh(Wxhx→t+Whhh→t?1+b→h),t
≥1,0,otherwisesp→t=softmax(Whsh→t+bs)
注意,与上文介绍的前馈神经网络语言模型相对,循环神经网络语言模型中只是将前一个词而不是前两个词作为输入;这是因为我们假设wt?2wt?2的信息已经包含在了隐状态ht?1→ht?1→中,因此不需要重复代入。
标签:表示 固定 最小 向量 语义 动态 最简 from apt
原文地址:http://www.cnblogs.com/801234567com/p/6940999.html