标签:任务 学习 输入 数据 中学 技术 关系 计算机 无限
什么是机器学习?计算机程序从经验E(给一些样本数据)中学习任务T,用度量P来衡量性能,并且由P定义的关于T的性能会随着经验E而提高
机器学习分为:有监督学习(给出数据样本的标签)、无监督学习(没有给出数据样本的标签)、半监督学习(给出少量的有标签数据,和大量没有标签的数据)、强化学习(对输入的数据做出评价)
机器学习的过程如下所示:
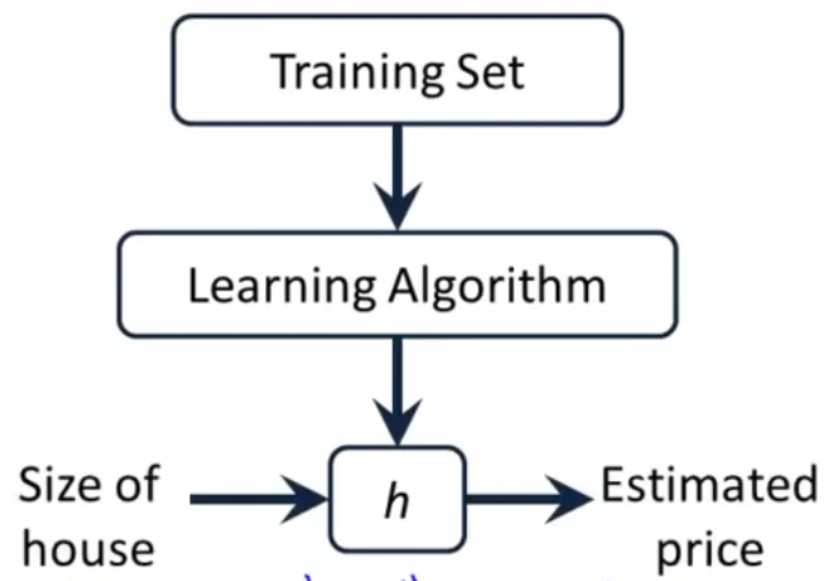
即由训练数据,输入学习算法,得到模型的假设函数,例如,由房屋尺寸和价格得到的房屋价格预测模型,由输入房屋尺寸,经过模型h,得到估计的房屋价格
为什么机器学习由训练的数据样本训练出的模型,在另外的测试样本中经过这个模型可以得到近似真实的结果?
以从瓶中抽取弹珠为例:
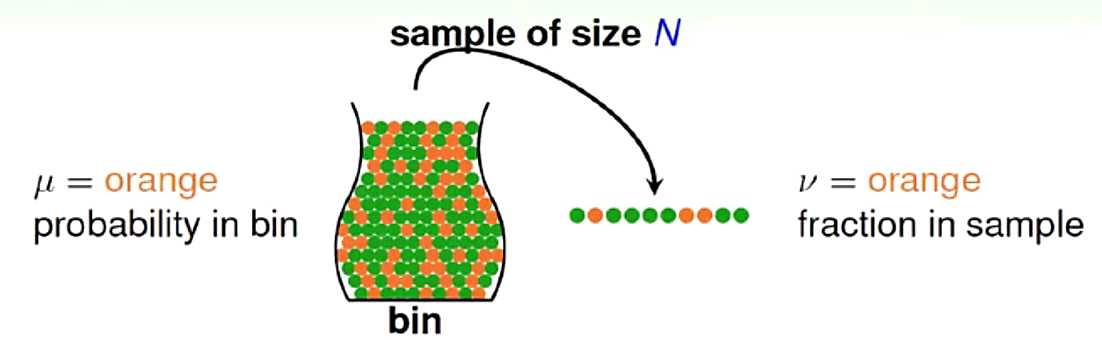
假设,总的样本中橘色弹珠的比例为 ,随机抽取出的样本中橘色弹珠的比例为
,随机抽取出的样本中橘色弹珠的比例为 ,这两个比例值相差的概率符合公式:
,这两个比例值相差的概率符合公式: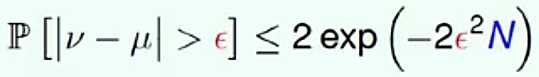 ,由公式可以看出,两个比例值相减的差值大于某一值
,由公式可以看出,两个比例值相减的差值大于某一值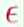 ,由于后面的
,由于后面的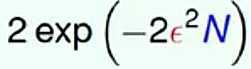 随着
随着 的增大而减小,公式说明两个比例值相差很大的概率是很小的,说明在一定程度上抽取的样本训练模型可以代表真实的模型,但只是大致相近,不能等同与真实模型,那么怎么保证由样本训练出的模型无限接近于真实的模型?
的增大而减小,公式说明两个比例值相差很大的概率是很小的,说明在一定程度上抽取的样本训练模型可以代表真实的模型,但只是大致相近,不能等同与真实模型,那么怎么保证由样本训练出的模型无限接近于真实的模型?
引入三个符号,训练时的误差Ein和测试模型的误差Eout,以及代表模型复杂度的 ,训练模型时要Ein尽可能的小(理想情况下为0),无限接近真实的模型要Eout尽可能的最小,模型的假设函数用g表示,则对于一个模型函数g的Ein和Eout的关系表示为
,训练模型时要Ein尽可能的小(理想情况下为0),无限接近真实的模型要Eout尽可能的最小,模型的假设函数用g表示,则对于一个模型函数g的Ein和Eout的关系表示为
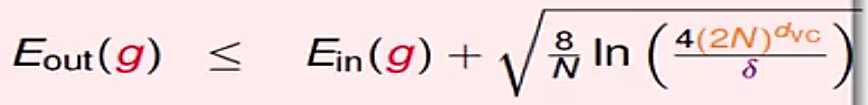 ,
,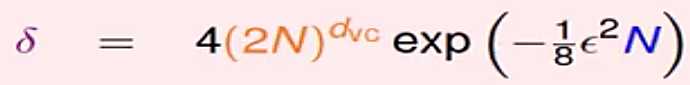
由公式可以看出
线性回归模型,由一系列输入得到一个实数的输出
标签:任务 学习 输入 数据 中学 技术 关系 计算机 无限
原文地址:http://www.cnblogs.com/zsw900610/p/6953912.html