标签:容器 read 第一个 体会 会同 9.png 设计 灰色 time
前面我们知道了在一个简单的SRAM 芯片中进行读写操作的步骤了,然后我们来了解一下普通的DRAM 芯片的工作情况。DRAM 相对于SRAM 来说更加复杂,因为在DRAM存储数据的过程中需要对于存储的信息不停的刷新,这也是它们之间最大的不同。
1. 多路寻址技术
最早、最简单也是最重要的一款DRAM 芯片是Intel 在1979 年发布的2188,这款芯片是16Kx1 DRAM 18 线DIP 封装。“16K x 1”的部分意思告诉我们这款芯片可以存储16384个bit 数据,在同一个时期可以同时进行1bit 的读取或者写入操作。
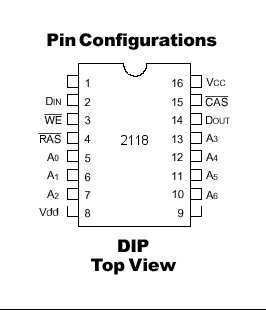
上面的示意图可以看出,DRAM 和SRAM 之间有着明显的不同。首先你会看到地址引脚从14 根变为7 根,那么这颗16K DRAM 是如何完成同16K SRAM 一样的工作的呢?答案很简单,DRAM 通过DRAM 接口把地址一分为二,然后利用两个连续的时钟周期传输地址数据。这样就达到了使用一半的针脚实现同SRAM 同样的功能的目的,这种技术被称为多路技术(multiplexing)。
那么为什么要减少地址引脚呢?这样做有什么好处呢?前面我们曾经介绍过,存储1bit的
数据SRAM 需要4-6 个晶体管但是DRAM 仅仅需要1 个晶体管,那么这样同样容量的SRAM 的体积比DRAM 大至少4 倍。这样就意味着你没有足够空间安放同样数量的引脚(因为针脚并没有因此减少4 倍)。当然为了安装同样数量的针脚,也可以把芯片的体积加大,但是这样就提高芯片的生产成本和功耗,所以减少针脚数目也是必要的,对于现在的大容量DRAM 芯片,多路寻址技术已经是必不可少的了。
当然多路寻址技术也使得读写的过程更加复杂了,这样在设计的时候不仅仅DRAM 芯片更加复杂了,DRAM 接口也要更加复杂,在我们介绍DRAM 读写过程之前,请大家看一张DRAM 芯片内部结构示意图:
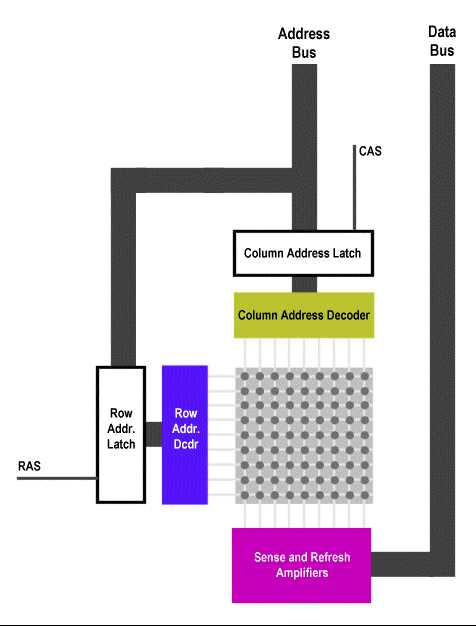
在上面的示意图中,你可以看到在DRAM 结构中相对于SRAM 多了两个部分:由/RAS(Row Address Strobe:行地址脉冲选通器)引脚控制的行地址门闩线路(Row Address Latch)和由/CAS(Column Address Strobe:列地址脉冲选通器)引脚控制的列地址门闩线路(ColumnAddress Latch)。
2. DRAM的读取过程和各种延时
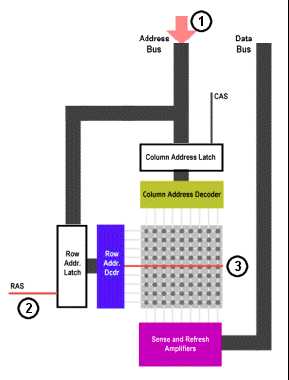
1)通过地址总线将行地址传输到地址引脚
2)/RAS 引脚被激活,这样行地址被放入到行地址选通电路中
3) 行地址解码器( Row Address Decoder)选择正确的行然后送到传感放大器( sense amps)
4)/WE 引脚被确定不被激活,所以DRAM 知道它不会进行写入操作
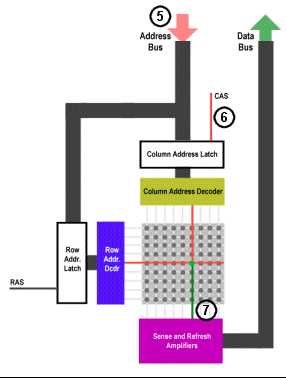
5)列地址通过地址总线传输到地址引脚
6)/CAS 引脚被激活,这样列地址被放入到列地址选通电路中
7)/CAS 引脚同样还具有/OE 引脚的功能,所以这个时候Dout 引脚知道需要向外输出数据。
8) /RAS 和/CAS 都不被激活,这样就可以进行下一个周期的数据操作了。
其实DRAM 的写入的过程和读取过程是基本一样的,所以如果你真的理解了上面的过程就能知道写入过程了,所以这里就不赘述了。(只要把第4 步改为/WE 引脚被激活就可以了)。
在内存的读取过程中,需要我们考虑的有两个主要类型的延迟。第一类的是连续的DRAM 读操作之间的延迟。内存不可能在进行完一个读取操作之后就立刻进行第两个读取操作,因为DRAM 的读取操作包括电容器的充电和放电另外还包括把信号传送出去的时间,所以在两个读取操作中间至少留出足够的时间让内存进行这些方面的操作。
在连续的两次读取操作之间,第一种类型的延迟包括 /RAS 和 /CAS 预充电延迟时间。在 /RAS 被激活并且失活之后,你必须给它足够的时间为下次激活做好准备。下图可以帮助你更好了解这个过程。
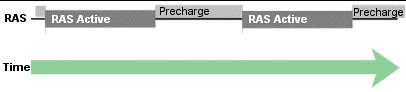
CAS 预充电的过程是一样的,你只要把上图的“RAS”换成“CAS”就可以了。
从前面我们介绍的DRAM 读取过程的8 个步骤中,我们可以了解到 /RAS 和 /CAS 预充电过程是依次进行的,所以我们在一定的时间里只能进行有限次数的读取操作。特别是在第8 个步骤中,当一次读取操作周期结束之后,我们必须让 /RAS 和/CAS 引脚都失活。实际上,在你让它们失活之后,必须等待预充电过程结束之后才能开始下一个操作(或者还是读取操作、或者是写入操作、或者是刷新操作)。
当然在两次读取操作之间的预充电时间不是限制DRAM 速度的唯一因素。第二种延迟类型是叫做内部读取延迟( inside-the-read)。这种延迟同两次读取操作之间的延迟非常的相似,但不是由停止 /RAS 和/CAS 激活而产生的,而是由于要激活 /RAS 和/CAS 而产生的。比如,行存取时间(tRAC)--它就是在你激活/RAS 和数据最终出现在数据总线之间的时间。同样的列存取时间 (tCAC)就是激活 /CAS 引脚和数据最终出现在数据总线上之间的时间。下面的示意图可以帮助你更好的理解这两种类型的延迟:
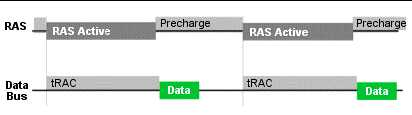
上面的图仅仅是一个示意图,下面的时序图可以帮助你了解不同的延迟时间发生的顺序:
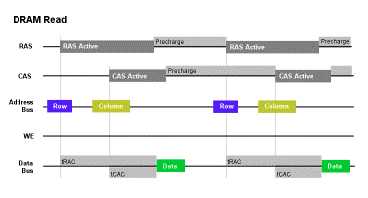
现在让我们花一点时间结合前面介绍的读取过程来研究一下上面的这张示意图:
1) 首先看上图第一行,在预充电期间行地址通过地址总线传输到地址引脚,这个期间/RAS 未被激活,在第三行Address BUS 中我们看到数据在这个期间正在行地址总线上,这个期间/CAS 也处于预充电状态;
2) 依然看上图第一行,/RAS 引脚被激活(RAS Active,灰色的部分),行地址就会被放入行地址选通电路(第三行Address Bus 中所示),这个期间/CAS 依然处于预充电状态;在/RAS 被激活的同时,tRAC(行存取时间)开始--如上图最后一行Data Bus 所示。
3) 在/RAS 被激活以后,行地址解码器( Row Address Decoder)选择正确的行然后送到传感放大器( sense amps)
4) 在这个期间/WE 引脚一直处于不激活的状态,所以 DRAM 知道它们不是进行写操作--这个状态将一直持续到开始执行写操作才结束
5) 列地址通过地址总线传输到地址引脚
6) /CAS 引脚被激活(如上图第三行),列地址就可以被送到列地址选通器( Column Address Latch) ,这个时候tCAC(列地址访问时间)开始计时
7) 在/CAS 处于激活状态期间的末尾,/RAS 停止激活--也就大约在这个时间附近找到的数据被传送到数据总线进行数据传送(如图data Bus),在数据总线进行数据传输的过程中,地址总线是处于空闲状态的,它并不接受新的数据--在数据开始创送的同时tRAC 和tCAC 都结束了。
8)就在数据在数据总线上传输期间,/CAS 引脚也被停止激活--就是得到一个高电平,从而开始进入到预充电期。/RAS 和/CAS 会同时处于预充电期,直到下次/RAS 被激活进入到下一个读取操作的周期。
相信经过这样的说明大家应该了解DRAM 的读取过程了。 在这个基础上我们就可以开始认识SIMM 或者DIMM 的潜伏期( latency)问题了。首先我们来继续澄清一下几个概念。
DRAM 潜伏期类型分为两种:访问时间( access time)和周期时间(cycle time)。其中访问时间(access time)同前面我们谈论的第二种类型的延迟有关,也就是同读取周期中的延迟时间;而周期时间(cycle time)同我们前面谈论的第一种类型的延迟有关,也就是受到两个读取周期之间的延迟时间影响。当然潜伏期的时间很短,都是用纳秒来衡量的。
对于异步 DRAM 芯片,访问时间就是从行地址到达行地址引脚的时间起截至到数据被传输到数据引脚的时间段。这样,访问时间为60 纳秒的 DIMM 意味着当我们下达读取数据的命令后,地址数据被送到地址引脚之后要等待60 纳秒才能达到数据输出引脚。周期时间,从字面上理解就是从两个连续读取操作之间的时间间隔。如何尽可能的减小DRAM 的周期时间和访问时间是我们这篇文章后半部分将要详细的讨论的问题。
我们平时说到DRAM 内存是多少多少纳秒,这里指的一般是访问时间(我们也会对于为什么采取这样的标称方法进行解释)。我们都知道访问时间越短,意味着内存工作频率会越高。当然内存工作频率越高,意味着可以适应外频更高的处理器。如果处理器的时钟周期较短,而DRAM 的潜伏期较长,处理器在很多时间里都是等到DRAM 传送数据。因此当DRAM一定时,比如时潜伏期为70 纳秒,那么一颗 1GHz PIII 等待数据的时间将会比一颗 400MHzPII 处理器长。当然出现这样的现象是每个用户都不愿意看到的,当使用的内存速度越慢或者说你的处理器相对越快,你的处理器就会由更多的性能都被这样的等待浪费了。
3. DRAM的刷新
我们已经提到过,DRAM 同SRAM 最大的不同就是不能比较长久的保持数据,这项特性使得这种存储介质对于我们几乎没有任何的作用。但是DRAM 设计师利用刷新的技术使得DRAM 成为了现在对于我们最有用处的存储介质。这里我仅仅简要的提及一下DRAM 的刷新技术,因为在后面介绍FP、EDO 等类型的内存的时候,你会发现它们具体的实现过程都是不同的。
DRAM 内仅仅能保持其内存储的电荷非常短暂的时间,所以它需要在其内的电荷消失之前就进行刷新直到下次写入数据或者计算机断电才停止。每次读写操作都能刷新DRAM内的电荷,所以DRAM 就被设计为有规律的读取DRAM 内的内容。这样做有下面几个好处。
第一, 仅仅使用/RAS 激活每一行就可以达到全部刷新的目的;
第二, DRAM 控制器来控制刷新,这样可以防止刷新操作干扰有规律的读写操作。
在文章的开始,曾经说过一般行的数目比列的数据少。现在我可以告诉为什么会这样了,因为行越少用户刷新的时间就会越少。
4. 快页模式DRAM
FPM DRAM( Fast Page Mode DRAM),也就是我们常说的快页内存。之所以称之为快页内存,因为它以4 字节突发模式传送数据,这4 个字节来自同一列或者说同一页。
如何理解这种读取方式呢?FPM DRAM 如果要突发4 个字节的数据,它依然需要依次的读取每一个字节的数据,比如它要读取第一个字节的数据,这个时候的情况同前面介绍的DRAM 读取方式是一样的(我们依然通过读取下面的FPM 读取时序图来了解它的工作方式):
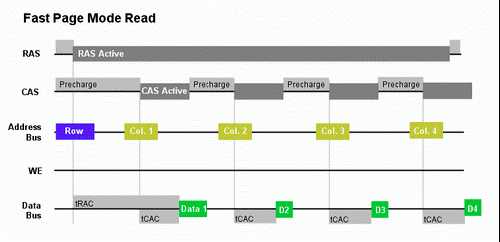
1. 首先行地址被传送到行地址引脚,在/RAS 引脚被激活之前,/RAS 处于预充电状态,/CAS 也处于预充电状态,当然/WE 此时依然是高电平,FPM 至少知道自己不会进行写操作。
2. /RAS 引脚被赋予低电平而被激活,行地址被送到行地址选通器,然后选择正确的行送到传感放大器,就在/RAS 引脚被激活的同时,tRAC 开始计时。
3. /CAS 一直处于预充电状态,直到列地址被传送到列地址引脚并且 /CAS 引脚得到一个低电平而被激活(tCRC 时间开始计时),然后下面的事情我们也应该很清楚了,列地址被送到列地址选通器,然后需要读取的数据位置被锁定,这个时候Dout 引脚被激活,第一组数据就被传送到数据总线上。
4. 对于原来介绍的DRAM,这个时候一个读取周期就结束了,不过对于FPM 则不同,在传送第一组数据期间,/CAS 失活(/RAS 依然保持着激活状态)并且进入预充电状态,等待第二组列地址被传送到列地址引脚,然后进行第二组数据的传输,如此周而复始直至4 组数据全部找到并且传输完毕。
5. 当第四组数据开始传送的时候,/RAS 和/CAS 相继失活进入到预充电状态,这样FPM的一个完整的读取周期方告结束。FPM 之所以能够实现这样的传输模式,就是因为所需要读取的4 个字节的行地址是相同的但是列地址不同,所以它们不必为了得到一个相同的行地址而去做重复的工作。
6. 这样的工作模式显然相对于普通的DRAM 模式节省了很多的时间,特别是节省了3次/RAS 预充电的时间和3 个tRAC 时间,从而进一步提高的效率。
我想你一定看到过诸如6-3-3-3 这样的内存标注方法,其中的6 表示从最初状态读取第一组数据需要6 个时钟周期,而读取另外三个数据仅仅需要3 个时钟周期就能达到目的了。
需要特别指出的是,在上面的时序图中,我们并没有标注出 FPM DRAM 进行第二个、第三个、第四个数据输出的前进行新的列地址选通的时间,但是从上面的示意图中我们可以看到Col.2 同Data1 和D2 之间都没有重叠,所以这三个数据的输出是进行完毕一个再进行的另一个,因此再上一次数据传输完毕到下一次列地址传输之间还有一点小小的延迟。请看下图:
5. 扩展数据输出DRAM
EDO DRAM( Extended Data Out DRAM:扩展数据输出DRAM)在介绍FPM 的读取过程的最后着重提到了 FPM DRAM 是在上一次的数据读取完毕才会进行下一个数据的读取,但是对于EDO DRAM 却是完全不一样的。 EDO DRAM 可以在输出数据的同时进行下一个列地址选通,我们依然结合下面的EDO 读取时序图来了解EDO DRAM 读取数据的过程:
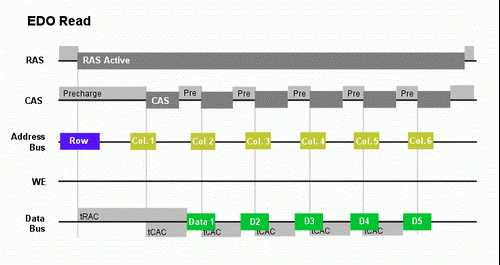
1. /RAS 在结束上一次的读取操作之后,进入预充电状态,当接到读取数据的请求之后,行地址首先通过地址总线传输到地址引脚,在这个期间/CAS 依然处于预充电状态。
2. /RAS 引脚被激活,行地址开始经过行地址选通电路和行地址解码器进行行地址的选择,就在这个同时tRAC 周期开始,因为是读取操作/WE 引脚一直没有被激活,所以内存知道自己进行的是读取操作而不是写操作。
3. 在/CAS 依然进行预充电的过程中,列地址被送到列地址选通电路选择出来合适的地址,当/CAS 被激活的同时tCAC 周期开始,当tCAC 结束的时候,需要读取的数据将会通过数据引脚传输到数据总线。
4. 从开始输出第一组数据的时候,我们就可以体会到EDO 同FPM 之间的区别了:在tCAC 周期结束之前,/CAS 失活并且开始了预充电,第二组列地址传输和选通也随即开始,第一数据还没有输出完毕之前,下一组数据的tCAC 周期就开始了--显然这样进一步的节省了时间。就在第二组数据输出前,/CAS 再次失活为第三组数据传输列地址做起了准备…
5. 如此的设计使得EDO 内存的性能比起FPM 的性能提高了大约20-40%
6. 正是因为EDO 的速度比FPM 快,所以它可以运行在更高的总线频率上。所以很多的EDO RAM 可以运行在66MHz 的频率上,并且一般标注为5-2-2-2。
标签:容器 read 第一个 体会 会同 9.png 设计 灰色 time
原文地址:http://www.cnblogs.com/lzhu/p/7071488.html
{kind=link}