标签:record table potential 3.3 tin his 接收 丢失 type
目前我们的数据是通过OGG->Kafka->Spark Streaming->HBase。由于之前我们发现HBase的列表put无法保证顺序,因此改了程序,如果是在同一个SparkStreaming的批次里面对同一条数据进行操作,则写入HBase的数据时间戳就非常相近,只会差几毫秒,如果是不同批次则会差好几秒。此为背景。
现在有一条数据,理应先删除再插入,但是结果变成了先插入再删除,结果如下
hbase(main):002:0> get ‘XDGL_ACCT_PAYMENT_SCHEDULE‘,‘e5ad-***‘, {COLUMN=>‘cf1:SQLTYPE‘,VERSIONS=>10}COLUMN CELLcf1:SQLTYPE timestamp=1498445308420, value=Dcf1:SQLTYPE timestamp=1498445301336, value=I
其中,两条记录的时间戳换算过来正好相差了7秒
2017-06-26 10:48:21 I
2017-06-26 10:48:28 D
很明显这两条数据并没有在同一个批次得到处理,很明显Spark获取到数据的先后顺序出了点问题。
首先SparkStream接收到数据后根据数据的pos排序,然后再根据主键排序。从现象看,是SparkStreaming分了两个批次才拿到,而SparkStreaming从Kafka拿数据也是顺序拿的。那么出现问题的可能性就只有两个:
1、OGG发给Kafka的数据顺序是错误的。
2、OGG发给Kafka的数据顺序是正确的,但是发到了不同的Kafka Partition。
为了验证上面的两个猜想,我把kafka的数据再次获取出来进行分析。重点分析数据的partition、key、value。
得到的结果如下:
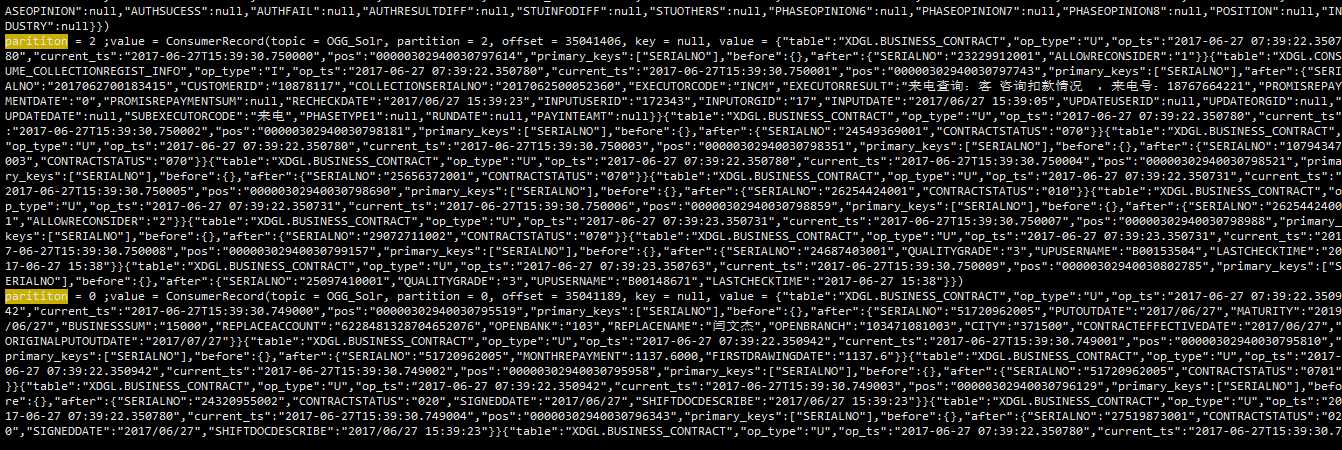
可以看到数据的同一个表数据写到了不同的分区,可以看到OGG的同一分区下的数据顺序是正确的。
正好说明2.1里面的第二个猜想。看来是OGG写入的时候并没有按照数据的表名写入不同的分区。
在OGG 文档
http://docs.oracle.com/goldengate/bd1221/gg-bd/GADBD/GUID-2561CA12-9BAC-454B-A2E3-2D36C5C60EE5.htm#GADBD449
中的 5.1.4 Kafka Handler Configuration 的属性 gg.handler.kafkahandler.ProducerRecordClass 里面提到了,默认使用的是oracle.goldengate.handler.kafka.DefaultProducerRecord这个类对表名进行分区的。如果要自定义的话需要实现CreateProducerRecord这个接口
原话是 The unit of data in Kafka - a
ProducerRecordholds the key field with the value representing the payload. This key is used for partitioning a Kafka Producer record that holds change capture data. By default, the fully qualified table name is used to partition the records. In order to change this key or behavior, theCreateProducerRecordKafka Handler Interface needs to be implemented and this property needs to be set to point to the fully qualified name of the customProducerRecordclass.
然而写入kafka的结果却不是这样子的。这点让人费解。看来我们需要查看OGG的源代码。
在OGG的安装包里面有一个名叫ggjava/resources/lib/ggkafka-****.jar的文件,我们将其导入一个工程之后就可以直接看到它的源代码了。
我们直接查看oracle.goldengate.handler.kafka.DefaultProducerRecord这个类
public class DefaultProducerRecord implements CreateProducerRecord {public DefaultProducerRecord() {}public ProducerRecord createProducerRecord(String topicName, Tx transaction, Op operation, byte[] data, TxOpMode handlerMode) {ProducerRecord pr;if(handlerMode.isOperationMode()) {pr = new ProducerRecord(topicName, operation.getTableName().getOriginalName().getBytes(), data);} else {pr = new ProducerRecord(topicName, (Object)null, data);}return pr;}}
这个类只返回一个ProducerRecord,这个是用于发送给Kafka的一条消息。我们先不管这个,继续看他是如何写给kafka的
首先是OGG与Kafka相关的配置类 oracle.goldengate.handler.kafka.impl.KafkaProperties 。这个类里面定义了一堆参数,我们只需要关心partitioner.class这个参数,该参数用于定义写入Kafka的时候获取分区的类。很遗憾,这个类没有该参数配置。
这里有一个抽象类oracle.goldengate.handler.kafka.impl.AbstractKafkaProducer,他有两个子类,分别叫BlockingKafkaProducer和NonBlockingKafkaProducer (默认是NonBlockingKafkaProducer)
这两个类都是直接将通过producer对象将record发送给了kafka。因此想要指导Kafka的分区信息还需要看Kafka是怎么获取分区的。
进入kafka的producer发送record的函数
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {return send(record, null);}public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {// intercept the record, which can be potentially modified; this method does not throw exceptionsProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);return doSend(interceptedRecord, callback);}
发送的方法在doSend里面,里面内容很多,请看我勾出来的这两段
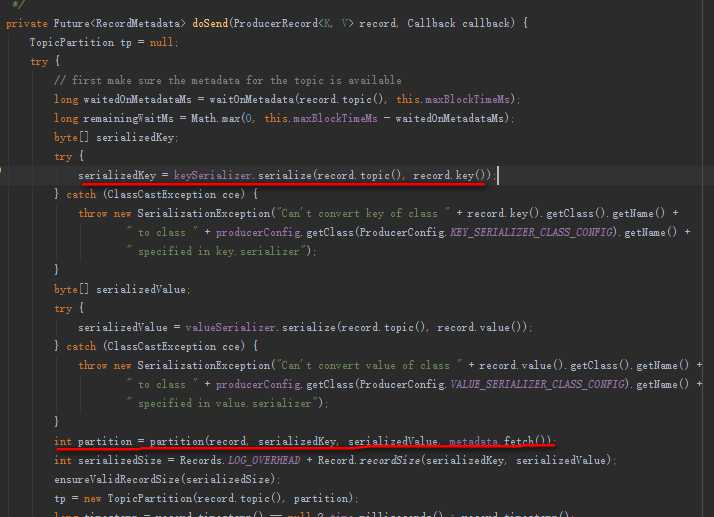
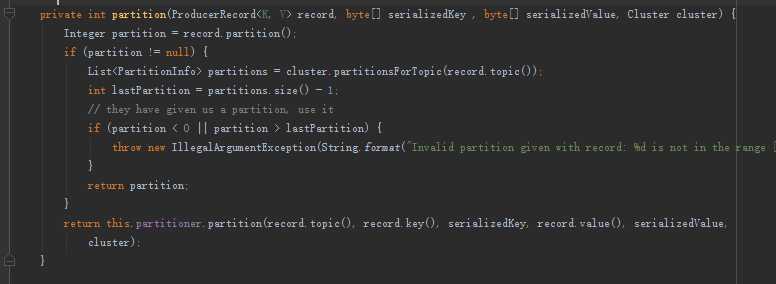
由于写入的时候都没有对Record指定分区,因此这段代码的partition都为空。所以代码总会执行到 this.partitioner.partition(record.topic(), record.key(), serializedKey,record.value(), serializedValue,cluster)
该函数是kafka的Partitioner这个抽象类里面的
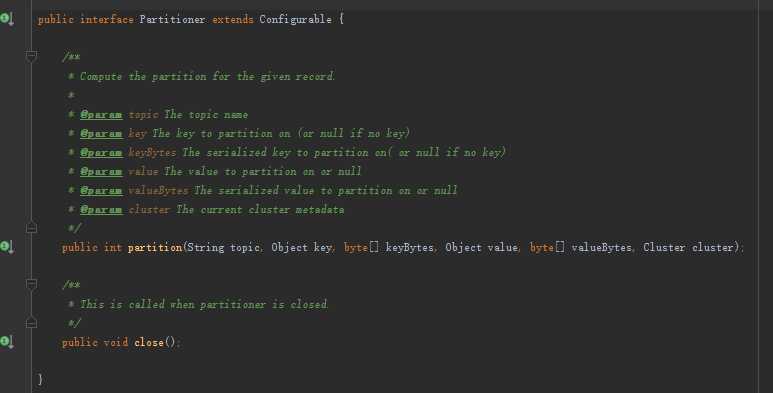
由于2.3.2 Kafka配置类中没有指定分区的class,因此只会使用Kafka默认的分区类org.apache.kafka.clients.producer.internals.DefaultPartitioner
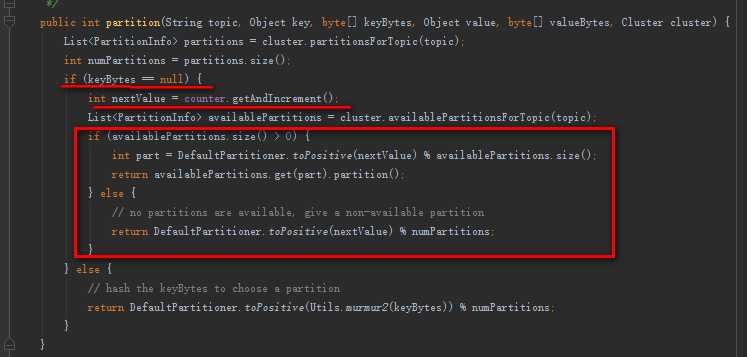
private final AtomicInteger counter = new AtomicInteger(new Random().nextInt());
这里先是获取了一个随机值,然后再获取了Kafka中对应topic的可用分区列表,然后根据分区数和随机值进行取余得到分区数的值。
流程走到这里,我们基本可以得到一个结论。
事情到了这里,我们可以断定,写入分区错乱的问题是因为gg.handler.kafkahandler.Mode是事务模式,导致多条消息一次发送了,无法使用表名作为key,OGG就用了null作为key发送给了Kafka,最终Kafka拿到空值之后只能随机发送给某个partition,所以才会出现这样的问题。
最终,修改了ogg的操作模式之后可以看到,写入的分区正常了。
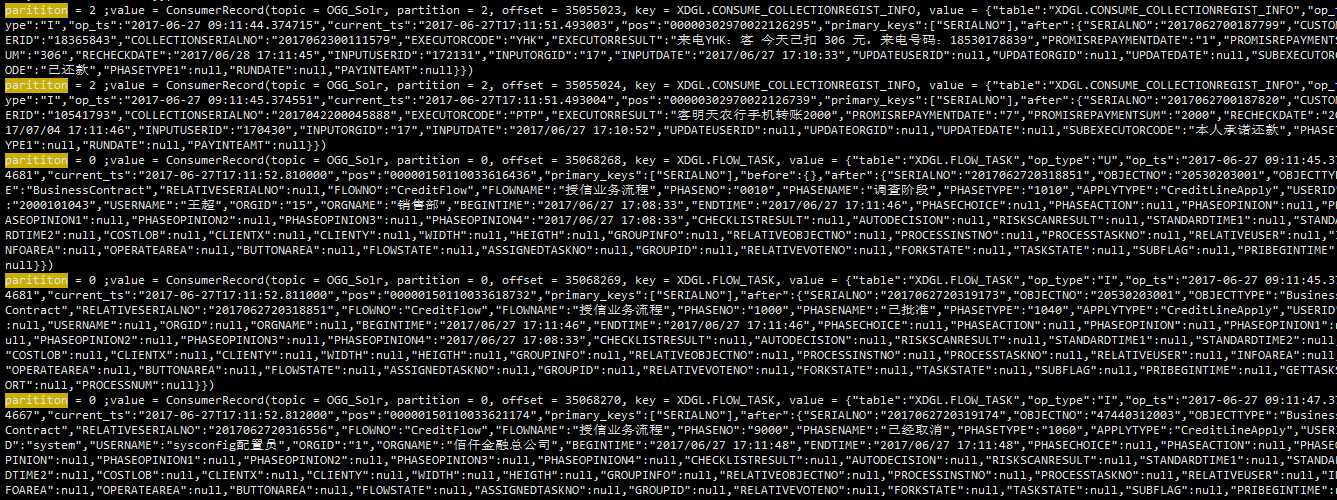
标签:record table potential 3.3 tin his 接收 丢失 type
原文地址:http://www.cnblogs.com/kekukekro/p/7088154.html