标签:blog http os io ar 文件 数据 2014 log
首先修改Master的core-site.xml文件,此时的文件内容是:
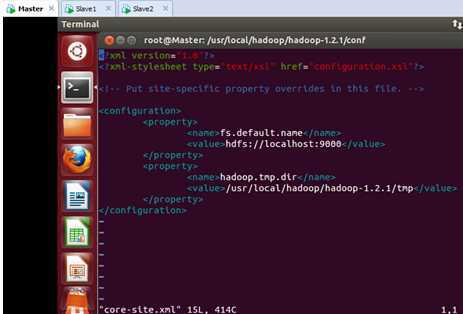
我们把“localhost”域名修改为“Master”:
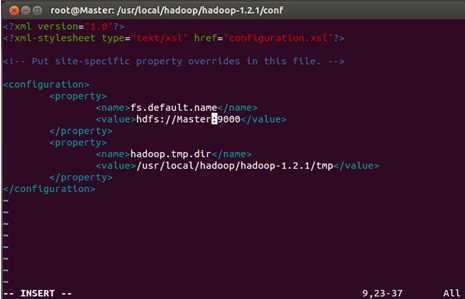
同样的操作分别打开Slave1和Slave2节点core-site.xml,把“localhost”域名修改为“Master”。
其次修改Master、Slave1、Slave2的mapred-site.xml文件.
进入Master节点的mapred-site.xml文件把“localhost”域名修改为“Master”,保存退出。
同理,打开Slave1和Slave2节点mapred-site.xml,把“localhost”域名修改为“Master”,保存退出。
最后修改Master、Slave1、Slave2的hdfs-site.xml文件:
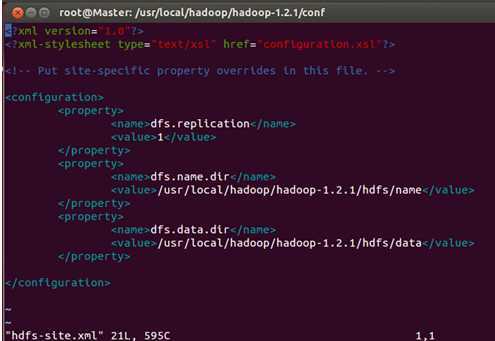
我们把三台机器上的“dfs.replication”值由1改为3,这样我们的数据就会有3份副本:
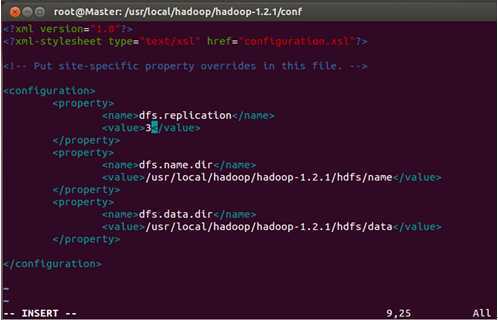
保存退出。
Step 4:修改两台机器中hadoop配置文件的masters和slaves文件
首先修改Master的masters文件:

进入文件:

把“localhost”改为“Master”:

保存退出。
修改Master的slaves文件,

进入该文件:

具体修改为:
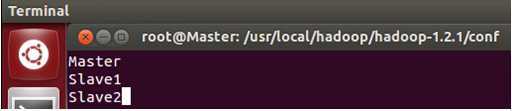
保存退出。
从上面的配置可以看出我们把Master即作为主节点,又作为数据处理节点,这是考虑我们数据的3份副本而而我们的机器台数有限所致。
把Master配置的masters和slaves文件分别拷贝到Slave1和Slave2的Hadoop安装目录下的conf文件夹下:
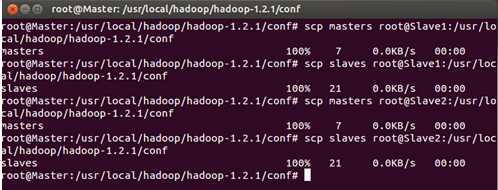
进入Slave1或者Slave2节点检查masters和slaves文件的内容:

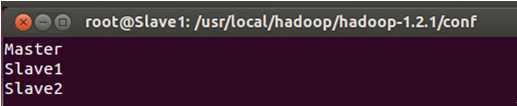
发现拷贝完全正确。
至此Hadoop的集群环境终于配置完成!
【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第二步)(3)
标签:blog http os io ar 文件 数据 2014 log
原文地址:http://www.cnblogs.com/spark-china/p/3951160.html